论文Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge提出了一种新的元奖励(Meta-Rewarding)方法,用于大型语言模型(LLMs)的自我改进过程。该方法允许模型评估自己的判断,并利用这些反馈来改进其判断能力。这种无监督的方法显著提高了模型的判断和遵循指令的能力,如在AlpacaEval 2和Arena-Hard基准测试中的胜率提升所示。
论文作者为Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar,来自Meta FAIR、University of California, Berkeley和New York University。
论文内容概要如下:
一、引言
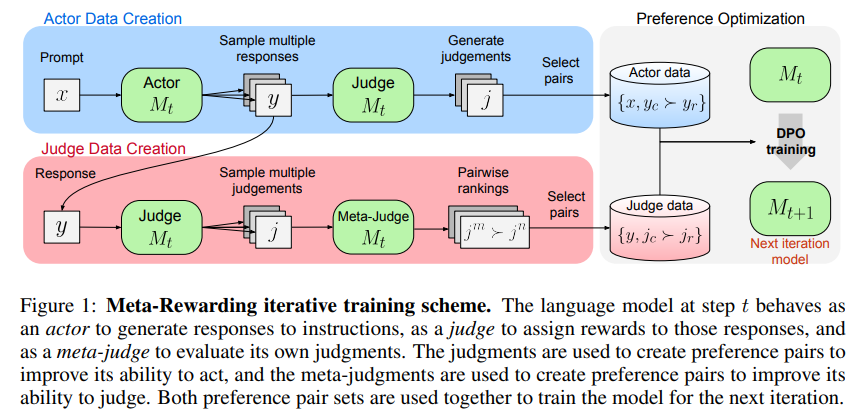
大型语言模型(LLMs)在遵循指令和回答用户查询方面取得了显著进展。传统改进这些模型的方法依赖于昂贵的人类数据。然而,最近的自奖励机制表明,LLMs可以通过自我评估来改进,而无需依赖人类标签员。现有方法的局限性在于它们主要集中在改进模型的响应,而不是其判断能力,导致迭代训练过程中快速饱和。提出的元奖励步骤通过让模型评估自己的判断,来增强其判断能力。
二、方法
- 元奖励框架:
- 角色:模型承担三个角色:演员(actor)、评审(judge)和元评审(meta-judge)。
- 演员:生成对指令的响应。
- 评审:评估这些响应并给予奖励。
- 元评审:评估评审的判断,以提高模型的判断能力。
- 迭代训练过程:
- 步骤1:演员为每个提示生成多个响应变体。
- 步骤2:评审使用预定义的标准评估每个响应并给予分数。
- 步骤3:元评审评估评审的判断,创建判断的偏好对用于训练。
- 步骤4:应用偏好优化以改进演员和评审的角色。
- 长度控制机制:
- 旨在减轻评审偏向于较长响应的倾向,通过将评审分数与长度信息结合,以确保在分数接近时选择较短的高质量响应。
三、实验
- 设置:
- 初始模型为Llama-3-8B-Instruct,一个经过指令微调的模型。
- 除了初始模型外,不使用额外的人类监督训练数据。
- 模型经历多次元奖励训练,重点在演员和评审角色。
- 评估指标:
- 指令遵循:在AlpacaEval 2、Arena-Hard和MT-Bench等基准测试中进行评估。
- 奖励建模:测量模型生成的分数与人类偏好的相关性,以及与强大AI评审的相关性。
- 结果:
- 在AlpacaEval 2和Arena-Hard上的胜率显著提高。
- 增强了与人类判断和强大AI评审(如GPT-4)的相关性。
四、主要发现
- 元奖励显著增强了模型的演员和评审技能。
- 长度控制机制有效防止训练迭代过程中响应长度的爆炸。
- 迭代训练:通过多次迭代持续改进,每次迭代都有显著的性能提升。
五、局限性
- 5分评审系统:由于响应之间的质量差异最小,往往导致平局,需要仔细平均多个判断以区分它们。
- 分数饱和:随着训练的进行,响应越来越接近最高分,导致进一步改进难以检测。
- 位置偏差:元评审评估中的持续偏差。
六、结论
元奖励机制显著提高了LLMs的判断能力,增强了它们在没有额外人类反馈的情况下遵循指令的能力。这种方法为实现AI模型的超对齐(super alignment)提供了一个有前途的方向。
七、进一步研究
- 探索更细致的评分系统,以更好地区分响应并避免分数饱和。
- 减轻元评审中的位置偏差,以提高训练效果。
- 在更广泛的基准测试中评估该方法,以确认其通用性和鲁棒性。