论文FACTS About Building Retrieval Augmented Generation-based Chatbots详细讨论了如何在企业环境中构建基于检索增强生成(RAG)的聊天机器人,尤其是在NVIDIA内部三个企业聊天机器人的开发过程中遇到的实际挑战和解决方案。论文围绕NVIDIA提出的“FACTS”框架,阐述了构建企业级聊天机器人的关键因素,系统性分析了构建企业级生成式AI聊天机器人所面临的挑战,并通过实践提出了一系列可操作的技术方案。特别是在数据新鲜度、架构灵活性、成本控制、测试与反馈循环、安全性等方面,提供了全面的指南与实践经验,能够帮助其他企业在构建类似系统时避免常见的陷阱并提升系统的可靠性和效率。
论文作者为Rama Akkiraju, Anbang Xu, Deepak Bora, Tan Yu, Lu An, Vishal Seth, Aaditya Shukla, Pritam Gundecha, Hridhay Mehta, Ashwin Jha, Prithvi Raj, Abhinav Balasubramanian, Murali Maram, Guru Muthusamy, Shivakesh Reddy Annepally, Sidney Knowles, Min Du, Nick Burnett, Sean Javiya, Ashok Marannan, Mamta Kumari, Surbhi Jha, Ethan Dereszenski, Anupam Chakraborty, Subhash Ranjan, Amina Terfai, Anoop Surya, Tracey Mercer, Vinodh Kumar Thanigachalam, Tamar Bar, Sanjana Krishnan, Samy Kilaru, Jasmine Jaksic, Nave Algarici, Jacob Liberman, Joey Conway, Sonu Nayyar, Justin Boitano,均来自NVIDIA。
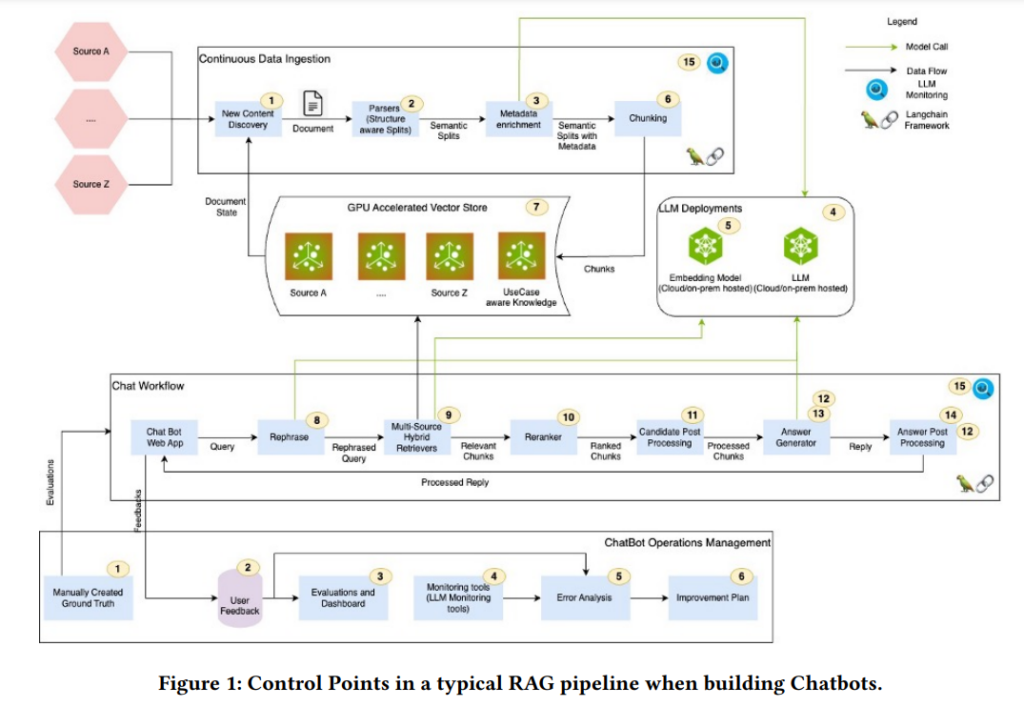
如下为论文概要内容介绍:
1. 引言
企业聊天机器人已经逐渐成为企业内部的生产力工具,用于查找与HR福利、IT帮助、财务信息等相关的内容。传统的聊天机器人主要依赖对话流系统,尽管可以提供一定程度的问答功能,但其能力有限,只能通过训练意图理解系统和检索技术提供提取式的答案。这种方法不仅开发复杂,而且功能有限。
生成式AI(Generative AI)的出现,特别是大型语言模型(LLM)与向量数据库的结合,显著提升了聊天机器人的对话能力。生成式AI不仅能根据用户输入生成上下文相关的答案,还能通过检索增强生成(RAG)系统结合实时更新的数据,为用户提供更加准确且符合时效性的回答。
随着NVIDIA构建生成式AI聊天机器人的初步尝试,团队意识到构建成功的企业级聊天机器人并不简单。通过RAG管道引入的信息检索和生成能力,聊天机器人可以解决诸多问题,但如何在企业环境中高效部署这些系统仍然存在诸多挑战。这些挑战涉及对生成模型的精细调校、对文档的安全访问控制、生成简洁且精确的响应、包括相关引用等诸多方面。
2. 案例研究
NVIDIA在内部开发了三款不同功能的聊天机器人:
- NVInfo Bot:这款机器人用于回答与企业相关的各种信息查询,处理约500M文档(总大小超过7TB),支持多种数据格式(例如文档、HTML、PDF、幻灯片等)。该机器人通过LangChain等框架和向量数据库构建,并确保严格的文档访问控制。
- NVHelp Bot:专注于IT帮助和HR福利相关的查询,处理大约2K多模态文档(文本、表格、图片、PDF、HTML等)。该机器人主要帮助员工处理日常的IT和HR问题。
- Scout Bot:专注于财务信息的查询,处理公司新闻、博客、SEC文件等公共数据来源,数据量约为4K多模态文档。
通过这些案例研究,NVIDIA总结了构建企业级RAG聊天机器人的一系列挑战和解决方案,并提出了一个结构化的框架来应对这些挑战。
3. FACTS 框架
FACTS是NVIDIA团队总结的一个用于构建企业级RAG聊天机器人的五维框架,代表着Freshness(数据新鲜度)、Architecture(架构灵活性)、Cost Economics(成本经济性)、Testing(测试)、Security(安全性)五个关键维度。
3.1 数据新鲜度(Freshness, F)
在RAG系统中,数据新鲜度是至关重要的。传统的生成模型(如GPT类模型)在训练完成后,其知识实际上是被冻结的,这导致它们可能无法生成最新的企业信息。此外,LLM容易生成错误或虚假的信息(称为“幻觉”),这在处理企业专有数据时是不可接受的。RAG系统通过向量数据库从相关文档中检索出企业数据并与LLM结合,能够确保数据的时效性。然而,RAG管道中存在多个控制点,这些控制点的错误调校可能会导致检索准确度降低,进而影响生成回答的质量。
控制点的挑战:
- 元数据增强、文档分块、查询重写:这些步骤对检索的相关性有重大影响。例如,文档的分块(chunking)策略、查询的重写方式以及检索结果的重新排序,都会影响检索到的内容是否准确相关。
- 混合搜索:单纯的向量数据库检索有时不足以处理如人名、地名、公司名称等实体匹配问题。结合词法搜索(如ElasticSearch)和向量检索的混合搜索方法,可以提高检索的准确性。
- 代理架构:对于复杂查询(如财务数据分析)需要复杂的代理架构来分解查询并进行协调。
经验总结: 为了提高企业聊天机器人的检索相关性,NVIDIA团队在管道中实施了元数据增强、分块策略优化、查询重写和重排序等技术手段,并通过自动化的机器学习模型调整这些参数。尽管已经取得了一定成效,但仍然有更多优化空间。
3.2 架构灵活性(Architecture, A)
由于AI技术的快速发展,RAG系统的架构需要足够灵活,以应对不同需求。为此,NVIDIA开发了一个名为NVBot的模块化平台,允许开发者根据具体需求选择合适的向量数据库、嵌入模型和LLM,并支持跨团队的开发合作。
架构的关键特性包括:
- 多机器人架构:在企业内部可以同时构建多个专用的领域机器人和一个总的企业级机器人。领域机器人专注于特定的业务领域,而企业级机器人则作为“总控中心”,根据用户的查询,将问题路由给最合适的领域机器人。
- 低代码/无代码开发支持:NVBot平台支持低代码/无代码开发环境,允许企业员工通过简单的配置和插件方式构建自己的聊天机器人。
3.3 成本经济性(Cost Economics, C)
由于大型语言模型的使用成本高昂,构建企业级聊天机器人需要精打细算。NVIDIA提出了几种降低成本的策略:
- 使用小型开源模型:与商用的大型语言模型相比,开源的小型模型(如Llama3-70B)在许多场景下性能相当,并且响应延迟更低,成本也更低。
- GPU优化:通过NVIDIA的TensorRT-LLM推理库优化模型推理,可以进一步减少响应延迟。
- LLM网关:NVIDIA开发了内部的LLM网关,用于管理不同部门对LLM的调用请求,跟踪其成本,确保在使用商用LLM API时的安全性和成本控制。
3.4 测试(Testing, T)
RAG系统的测试过程十分复杂,尤其是在生成式AI系统中,测试需要人工参与来验证模型生成的回答是否准确。NVIDIA提出了几个关键的测试环节:
- 安全性测试:为了确保开发速度不影响安全性,NVIDIA与内部的红队合作,开发了回归测试数据集,用于每次更新后的安全性测试。
- 提示词变化测试:生成式AI模型对提示词的变化非常敏感,因此在每次提示词修改后需要进行全面的回归测试。
- 反馈循环:持续的用户反馈和基于人类反馈的强化学习(RLHF)是提高系统性能的重要手段。
3.5 安全性(Security, S)
在处理企业内容时,安全性至关重要。RAG系统必须确保:
- 企业内容的访问控制:企业文档通常受到访问控制列表(ACL)的保护,RAG系统在生成回答时必须严格遵循这些访问控制规则。
- 衍生风险:生成式AI系统可能会生成脱离原始上下文的回答,导致信息误读或敏感数据泄露。为此,NVIDIA开发了过滤和分类系统,以确保检索过程中自动过滤掉敏感数据。
- 企业内容安全:为了防止企业内容被不当访问或泄露,NVIDIA实施了内容安全项目,对文档进行敏感性分类,并在检索时排除敏感内容。
4. 结论
NVIDIA通过构建三个不同领域的聊天机器人,总结了构建企业级RAG系统的关键经验。这些经验被总结为FACTS框架,涵盖了内容新鲜度、架构灵活性、成本优化、系统测试和安全性五个维度。NVIDIA提出了一系列具体的技术方案,帮助企业构建安全、高效且具备成本效益的聊天机器人。
此外,论文还展望了未来的研究方向,包括如何处理复杂查询、如何在频繁更新的企业数据上高效生成摘要、如何通过AutoML自动优化RAG管道的控制点以及如何建立更加稳健的评估框架来测试生成的主观响应。