论文ChatQA: Surpassing GPT-4 on Conversational QA and RAG提出了名为ChatQA的模型,其在检索增强生成(RAG)和对话式问答(Conversational QA)任务中表现超越了GPT-4。
论文作者为Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro,来自NVIDIA。
一、背景与研究动机
近年来,对话式问答(Conversational QA)和检索增强生成(RAG,Retrieval-Augmented Generation)系统成为学术界和工业界的热点话题。用户越来越倾向于以对话的方式获取信息,因为这种方式能更好地支持上下文关联和连续问题推理。此外,许多实际应用场景需要模型整合大量上下文信息(例如,长文档和表格数据)以提供准确的回答。然而,开发一种能够匹敌甚至超越专有模型(如GPT-4)的开源对话式问答系统仍是一个重大挑战。
当前主要挑战:
- 现有大语言模型(LLM)需要具备强大的指令跟随能力,同时能够高效利用用户提供的上下文或检索到的证据进行回答。
- 在多轮问答中,模型需要有效处理上下文不完整的问题,例如用户问题中可能缺乏具体的指代信息。
- 生成幻觉(hallucination)是当前LLM面临的重要问题,尤其在无法回答的问题场景中,模型倾向于生成虚假或不准确的回答。
- 高质量的对话式问答模型往往依赖于专有数据和资源(如OpenAI的模型和数据),这对开源研究形成了障碍。
二、论文核心贡献
论文提出了ChatQA,一个开源的模型家族,旨在解决上述挑战,具体贡献包括:
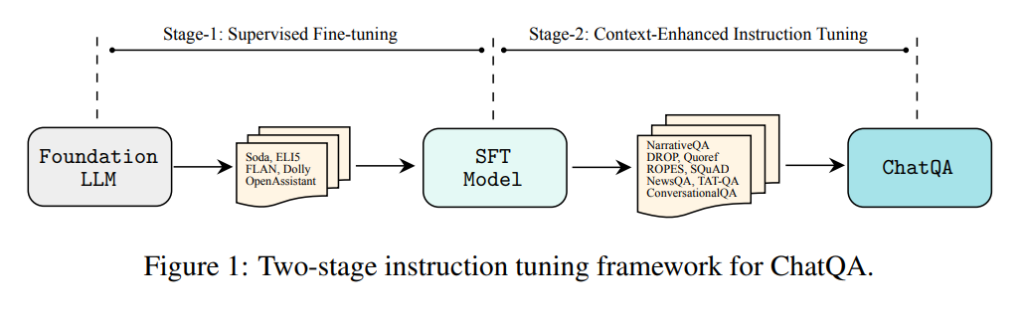
- 双阶段指令微调方法:通过监督微调(SFT)和上下文增强指令微调,显著提升了模型的对话式问答和检索增强生成能力。
- 优化检索机制:通过微调单轮检索器以支持多轮问答场景,实现了接近甚至超越查询改写模型(如GPT-3.5-Turbo)的性能,同时降低了部署成本。
- CHATRAG BENCH评测基准:设计了覆盖10个数据集的综合评测框架,涵盖文本问答、表格问答、算术推理和无法回答的问题场景。
- 开源生态系统:开放了模型权重、训练数据、评测基准和检索器,助力社区研究发展。
三、方法论
1. 双阶段指令微调方法
阶段一:监督微调(SFT)
目标:通过在大规模指令数据集上微调预训练LLM,增强模型的指令跟随能力。
- 数据构建:
- 合并了128K高质量的指令跟随数据,来源包括:
- 社交对话数据集Soda;
- 长文问答数据集ELI5;
- 链式推理(Chain-of-Thought, CoT)数据集(如FLAN、Dolly);
- 合成指令微调数据集(如Self-Instruct、Unnatural Instructions);
- 公共和私有的多轮对话数据集(如OpenAssistant、Dolly)。
- 数据集统一格式化为对话形式,包括“System”角色(引导模型提供礼貌和有用的回答)、“User”角色和“Assistant”角色。
- 合并了128K高质量的指令跟随数据,来源包括:
- 训练策略:
- 使用上述统一数据集对基础LLM进行微调,使其在指令跟随任务中表现出色。
阶段二:上下文增强指令微调
目标:进一步增强模型在上下文敏感和检索增强生成任务中的能力。
- 数据集构建:
- 人类注释数据(HumanAnnotatedConvQA):
- 收集了7K文档(覆盖多领域),由人类标注7K多轮对话,每个对话平均包含5轮用户-助手交互。
- 引入了1.5K标注为“不可回答”的样本,通过删除上下文中相关内容构造。
- 合成数据(SyntheticConvQA):
- 利用GPT-3.5-Turbo生成7K多轮对话,并通过4-gram重叠评分标注相关和不相关的文本片段。
- 生成了1.5K不可回答样本,模拟真实场景。
- 人类注释数据(HumanAnnotatedConvQA):
- 混合训练数据:
- 包括单轮问答数据集(如SQuAD、DROP)、多轮问答数据集(如HumanAnnotatedConvQA)、表格问答数据集(如TAT-QA),以及阶段一的全部SFT数据。
2. 检索优化方法
密集检索器微调:通过对高质量多轮问答数据进行微调,将单轮检索器扩展为多轮问答场景,以实现更高效的上下文检索。
查询改写(Query Rewriting):采用查询改写模型(如GPT-3.5-Turbo)重写用户问题为完整问题,与微调检索器相比:1)检索器微调方法在召回率和效率上更具优势;2)查询改写引入额外计算开销和API成本。
四、实验与结果
1. 基准测试:CHATRAG BENCH
- 数据集覆盖:
- 长文档数据集(如Doc2Dial、QuAC)需要检索;
- 短文档数据集(如CoQA、DoQA)直接作为输入;
- 表格数据集(如ConvFinQA、SQA)涉及复杂的数值推理。
- 模型表现:
- ChatQA-1.0-70B在综合评分上超越GPT-4(54.14对53.90)。
- Llama3-ChatQA-1.5-70B进一步提升,超越GPT-4-Turbo,领先幅度为4.4%。
2. 不可回答场景
- ChatQA通过标注少量“不可回答”样本,显著降低了幻觉生成:
- ChatQA-1.0-70B在QuAC和DoQA数据集上与GPT-4性能接近,优于GPT-3.5-Turbo。
3. 消融实验
- 阶段一和阶段二的重要性:
- 移除阶段一训练后,性能下降1.9分。
- 移除阶段二训练后,性能下降10.92分,表明阶段二对上下文感知能力至关重要。
- 数据集成效分析:
- 加入单轮问答数据集提升了多轮问答能力。
- 使用人类注释数据的模型在文本数据集上表现更好,特别是在不可回答场景中表现更优。
五、分析与讨论
1. 检索的影响
- 检索片段数量:检索top-5相关片段能在性能和上下文复杂度之间取得最佳平衡。
- 上下文顺序:顺序排列与逆序、交错排列性能相当,表明模型能够从复杂上下文中提取信息。
2. 表格问答性能
尽管ChatQA在文本数据集上表现优异,但在表格推理任务(如SQA)中仍稍逊于GPT-4。这表明模型在表格理解和数值推理方面还有改进空间。
六、结论与未来方向
论文通过创新性双阶段微调方法和优化检索机制,展示了ChatQA在对话式问答任务中的强大能力,其性能在多个基准上超越了GPT-4。未来的研究方向包括:
- 在表格问答任务上进一步优化模型推理能力;
- 在指令微调中更好地平衡上下文连续性和检索片段的离散性;
- 研究更高效的检索器优化方法以支持超大规模数据。
ChatQA: https://chatqa-project.github.io/