论文Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make Your LLMs Use External Data More Wisely详细探讨了如何将外部数据更有效地集成到大型语言模型(LLMs)中,以提升模型处理实际任务的能力。它通过提供分类和方法,对现有的RAG技术以及更广泛的数据增强LLMs技术进行了全面综述,并讨论了在各种场景下面临的挑战及解决方案。
论文作者为Siyun Zhao, Yuqing Yang, Zilong Wang, Zhiyuan He, Luna K. Qiu, Lili Qiu,均来自微软亚洲研究院(Microsoft Research Asia)。
以下是论文概要内容:
一、引言
论文开篇介绍了大语言模型在解决复杂任务中表现出的显著能力。然而,单靠训练好的LLMs并不能在所有领域中取得最佳效果,尤其在领域专用任务上,例如医疗、法律、金融等。主要问题在于:
- 幻觉生成:模型可能会基于它认为是对的知识生成错误的响应,这在关键领域中是不能接受的。
- 领域不匹配:预训练时模型的知识可能不具备最新的时效性,且未覆盖所有领域的专业数据。
- 缺乏解释性和可控性:预训练模型难以解释其生成的内容,外部数据的加入可以增强这些方面。
因此,论文提出,结合外部数据来增强LLMs的能力,尤其是RAG技术,通过实时检索和利用外部数据来支持模型生成响应,可以大大改善这些问题。
二、问题定义
论文详细定义了外部数据增强的LLMs任务形式,并提出通过以下数学公式表示:
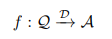
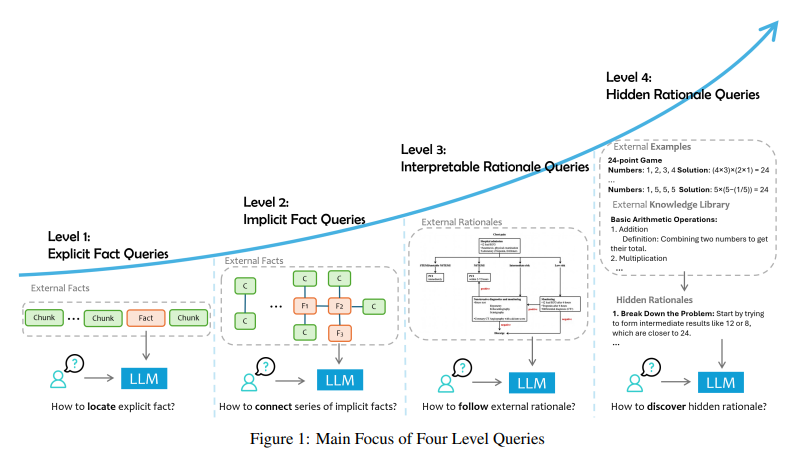
其中,Q代表查询,D代表外部数据,A代表响应。论文进一步提出,在RAG任务中,根据外部数据和任务的焦点不同,可以将查询划分为四个层次,每个层次对应不同的查询复杂性和数据需求:
- 显式事实查询(Explicit Fact Queries):直接要求从外部数据中检索显式、明文的事实。
- 隐式事实查询(Implicit Fact Queries):需要简单的推理或信息整合来获取隐含的事实。
- 可解释推理查询(Interpretable Rationale Queries):不仅需要提取事实,还需要能够理解和应用外部数据中的明确推理逻辑。
- 隐藏推理查询(Hidden Rationale Queries):更复杂的查询,涉及到隐含的、未明确说明的推理逻辑。
三、显式事实查询(L1)
这是最简单的查询类型,模型只需要从外部数据中检索直接可用的明文事实。例如,“2024年奥运会将在哪举办?”可以通过检索外部数据直接回答。论文对L1查询进行了如下描述:
- 数据依赖性:查询的回答直接依赖于外部数据中是否存在明确的事实。例如,外部数据被划分为若干片段(D1, D2, …, Dn),模型需要从中选择合适的片段来生成答案。
- RAG方法的应用:RAG技术通常用于处理此类查询,通过动态检索相关数据并将其集成到LLMs的生成过程中。然而,显式事实查询的挑战在于数据处理、检索和评估的难度。
挑战:
- 数据处理问题:如何有效处理和解析非结构化、多模式的外部数据(如表格、图像等)。
- 数据检索问题:如何从海量外部数据中准确检索出所需的片段。
- 评估难度:如何准确评估检索和生成的质量。
论文提出了一些针对这些问题的解决方案,例如改进数据处理、增强检索机制等。
四、隐式事实查询(L2)
隐式事实查询要求模型在外部数据中找不到直接的答案,需要模型通过推理、整合信息来生成响应。例如,“现在堪培拉所在国家的多数党是哪个党?”需要模型知道堪培拉在澳大利亚,然后再结合最新的政党信息回答。
挑战:
- 多步推理:隐式事实查询常常涉及多跳推理(multi-hop reasoning),需要模型逐步收集信息,然后综合生成答案。
- 复杂的数据检索需求:由于信息可能分散在多个文档中,单次检索往往不足以生成完整的答案。
论文讨论了几种适用于隐式事实查询的技术,例如递归RAG(Iterative RAG)和基于图/树结构的RAG(Graph/Tree RAG)。通过这些技术,模型能够分步执行多次检索,并综合多个数据片段生成正确的响应。
五、可解释推理查询(L3)
可解释推理查询需要模型不仅能获取事实,还能理解和应用领域特定的推理逻辑。此类查询的核心是外部数据通常包含某种形式的解释或决策流程,模型需要遵循这些推理流程来生成响应。例如,医疗领域中的诊断指南、法律领域的法规文本都属于这类数据。
挑战:
- 提示优化的成本:手动设计提示(prompt)来引导模型进行特定推理非常耗时且计算开销大。
- 缺乏透明性:提示的效果难以预测,尤其是模型内部的推理过程不透明,难以确定提示是否真正有效。
论文提出了几种解决方案,例如通过强化学习优化提示(Prompt Tuning),以及使用Chain of Thought(CoT)提示来增强模型的推理能力。
六、隐藏推理查询(L4)
隐藏推理查询是最复杂的查询类型,涉及的推理逻辑通常是隐含的,且没有明确记录。这类查询要求模型能够从大量外部数据中提取隐含的模式,并生成答案。例如,在法律、金融等领域,可能需要从过往的案例和经验中总结推理规则。
挑战:
- 逻辑检索困难:检索到的外部数据可能不直接包含查询答案,需要通过逻辑推理来连接相关信息。
- 数据不足:某些情况下,外部数据无法直接提供所需的推理支持,模型需要通过归纳总结间接信息生成答案。
论文提出了一些可能的解决方案,如离线学习(Offline Learning)、上下文学习(In-Context Learning)以及微调(Fine-Tuning),以提高模型在应对隐藏推理查询时的能力。
七、总结与展望
论文总结了处理外部数据增强LLMs应用时面临的不同层次查询挑战,并提出了相应的技术解决方案。主要有三种方式将外部数据注入到LLMs中:
- 上下文注入:将部分领域数据作为输入上下文提供给模型。
- 小模型指导:训练一个小模型来引导模型如何使用外部数据。
- 微调:直接使用领域数据对LLMs进行微调,使其成为领域专家模型。
论文还指出,不同的查询类型需要不同的技术方法,因此在开发LLMs应用时,理解任务需求并选择合适的技术非常重要。