论文Large Language Monkeys: Scaling Inference Compute with Repeated Sampling(《大型语言猴:通过重复采样扩展推理计算》)详细探讨了在推理过程中,通过扩展计算量(即增加推理时的计算资源)来提升大型语言模型(LLMs)解决复杂任务的能力。论文的核心思想是,通过生成多个不同的解决方案(也就是“重复采样”),而非依赖单次尝试来解决问题,能够显著提高解决问题的成功率,尤其在代码生成、数学推理等可以通过自动验证器验证的任务中。
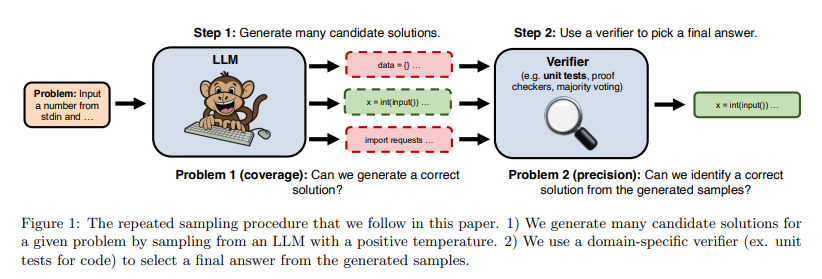
论文标题中的“猴子(Monkey)”是受无限猴子定理(Infinite monkey theorem)启发。让大模型LLM扮演猴子,为LLM给定一个正温度(positive temperature),让LLM为给定问题生成多个候选解决方案,然后使用领域特定的验证器(如代码的单元测试)从生成的样本中选择最终答案。
论文作者为Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, Azalia Mirhoseini,来自Stanford University,University of Oxford和§Google DeepMind。
论文概要内容如下:
1. 扩展推理计算的背景与意义
在训练阶段,扩展计算资源(如更大的模型、更大的训练数据集、更多的训练步骤)已经显著提升了LLMs的能力。然而,在推理阶段,计算资源的使用仍然较为保守,通常是每个问题只进行一次推理尝试。作者提出,推理计算的扩展是提升模型推理能力的另一维度,可以通过增加生成的样本数量来提高模型的表现。
论文通过实验证明,生成的样本数量与模型能够解决问题的覆盖率之间存在对数线性关系,这表明推理阶段也存在类似于训练阶段的“扩展定律”。这种方法特别适用于可以自动验证结果的领域,例如编程和形式化证明等任务。
2. 覆盖率和精度的定义与分析
- 覆盖率(Coverage):指模型在推理过程中,通过生成多个样本能够解决的所有问题的比例。覆盖率随着样本数量的增加而提高,研究显示覆盖率与样本数量呈对数线性关系。通过实验,作者发现覆盖率随着样本数量的增加可以跨越几个数量级增长。例如,在编程任务中,通过增加样本数量,模型的覆盖率从单次尝试的0.02%增加到使用10,000次采样后的7.1%。
- 精度(Precision):在某些任务中,即使生成了多个样本,仍然需要从中识别出正确答案。精度指的是模型在生成多个样本后,能否有效挑选出正确答案的能力。在能够使用自动验证器(如单元测试、证明检查器等)的任务中,精度可以得到自动保证;然而,在没有自动验证器的任务中,如数学推理,精度问题仍然是一个挑战,常用的多数投票或奖励模型在处理大规模样本时效果有限。
3. 重复采样在不同任务中的应用
作者对不同任务进行了重复采样实验,包括:
- 数学问题(GSM8K、MATH):这些问题没有自动验证器,因此需要依赖模型自行判断哪一个样本是正确的。实验表明,尽管覆盖率随着样本数量的增加而大幅提升,但现有的精度提升方法(如多数投票、奖励模型)在100个样本之后效果趋于平缓,远远未达到覆盖率的提升效果。
- 编程任务(CodeContests、SWE-bench Lite):这些任务中,使用自动化验证工具(如单元测试)来验证生成的代码是否正确。实验表明,重复采样显著提高了代码问题的解决率。例如,在SWE-bench Lite中,DeepSeek-V2-Coder-Instruct模型通过250次采样可以解决56%的问题,超过了GPT-4o单次尝试43%的表现。
- 形式化证明(MiniF2F-MATH):在这种任务中,模型生成的证明可以通过自动化工具(如Lean4)进行验证。实验显示,重复采样能够大幅提升覆盖率和任务成功率。
4. 重复采样的成本效益
论文指出,重复采样不仅在效果上优于单次尝试的推理方法,在成本效益上也具有优势。作者通过对比不同模型的API调用成本和推理性能,发现即使是较弱的模型,通过生成多个样本进行推理,其综合表现和成本效益都可以超过更昂贵、更强大的模型。例如,在SWE-bench Lite问题上,DeepSeek模型的每次采样成本仅为0.008美元,通过多次采样(例如5次)可以以更低的成本解决更多问题,而比单次使用Claude 3.5或GPT-4o模型更具性价比。
5. 在缺乏自动验证器的领域中面临的挑战
对于无法使用自动验证工具的任务,如数学问题,论文强调目前的样本验证方法(如多数投票和奖励模型)在样本数量超过100之后效果有限,无法充分利用较大样本数量带来的覆盖率提升。这表明在这些领域中,开发更加智能、精确的样本验证方法是未来研究的重要方向之一。
6. 未来研究方向
作者提出了一些未来的研究方向,以进一步提升重复采样的效果:
- 提升样本多样性:目前,论文主要依赖于通过调节采样温度(temperature)来生成多样化的样本。未来可以结合更高级别的多样性生成方法,提升样本间的差异性。
- 多轮交互:在实验中,模型生成样本时是单次生成的,未来可以通过让模型在生成样本后,利用反馈机制进行改进,从而提高解的质量。
- 学习先前的尝试:目前的实验是独立生成每个样本,而不参考之前生成的样本。未来可以通过使用模型反馈,让模型在生成后续样本时参考先前的生成结果。
7. 推理系统的优化
重复采样是一种与传统聊天机器人推理工作负载不同的推理类型。在许多实时应用中,低延迟和快速响应是关键,而重复采样则可以专注于通过大批量样本生成来最大化硬件的利用率,从而优化整体吞吐量。此外,通过共享前缀的注意力优化算法,可以进一步减少重复采样的成本。
8. 验证器的改进
在没有自动化验证工具的领域中,提升模型自我验证生成答案的能力是未来的重要研究方向之一。这不仅适用于数理推理等结构化任务,还可以扩展到需要主观判断的领域,例如创意写作等。通过开发新型的自动化验证器或任务转换器(如将非正式的数学陈述转化为形式化语言),可以进一步扩大重复采样方法的应用范围。
总结:
论文通过实验证明,重复采样是扩展推理计算的一种有效方法,可以显著提高LLMs的覆盖率和任务表现。在某些任务中,弱模型通过增加采样次数可以超越强模型的单次尝试结果,且具有更高的成本效益。然而,对于没有自动验证器的任务,如何精确识别正确的样本仍然是一个挑战。因此,未来研究的重点将是开发更强大的样本验证方法和提高生成样本的多样性与交互能力。