论文《Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model》提出了一种新的多模态模型训练方法,能够同时处理离散数据(如文本)和连续数据(如图像)。论文详细介绍了Transfusion模型的架构、训练策略、实验结果及其创新点,展示了这种模型在跨模态任务中的强大能力。
论文作者为Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, Omer Levy,来自Meta和University of Southern California。
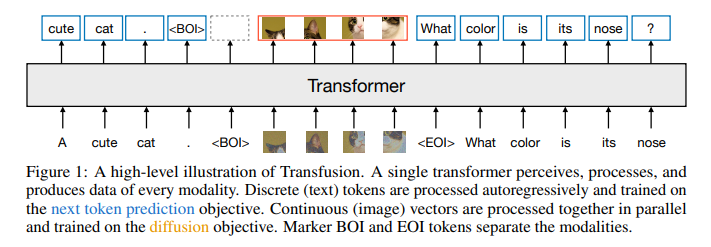
论文概要内容如下:
1. 研究背景与动机
多模态生成模型的核心挑战在于它们需要能够处理不同类型的数据模式:离散的数据如文本和代码,连续的数据如图像、音频和视频。当前,多数模型采用了分离的架构来处理这些数据类型,使用语言模型(如GPT等)处理离散数据,使用扩散模型处理连续数据。然而,这种做法带来了架构复杂性和信息损失。论文的作者提出,通过统一的模型来处理这两种类型的数据,可以解决这一问题,从而提高模型的生成能力和效率。
2. Transfusion模型的架构
Transfusion模型的创新之处在于它采用了一个统一的Transformer架构,通过两种不同的训练目标来处理离散和连续数据:
- 文本处理:模型采用经典的语言模型训练方法,即通过next-token prediction预测下一个token,这种方式广泛应用于文本生成任务中。
- 图像处理:模型通过扩散模型进行训练,扩散模型是一种逐步去噪的生成模型,它通过逐步还原图像中的噪声来生成高质量的图像。
为了确保模型能够有效处理这两种不同的数据,Transfusion在数据编码方面使用了不同的策略:
- 文本数据通过标准的词嵌入(embedding)层转化为向量表示。
- 图像数据则通过图像patch的方式进行处理,每张图像被分割成多个patch,每个patch通过变分自编码器(VAE)编码为向量。
3. 创新点
论文提出了一些关键的创新,提升了多模态任务的表现:
- 模态特定编码与解码层:为不同模态的数据设计了特定的编码和解码层。例如,文本数据通过标准的嵌入矩阵编码,图像数据则通过patch化(patchification)和扩散模型进行编码和解码。
- 混合的注意力机制:模型中的注意力机制结合了文本处理中的因果注意力(causal attention)和图像处理中的双向注意力(bidirectional attention)。对于图像数据,模型允许图像中的不同patch相互之间进行推断,从而大幅提高图像生成质量。
- 图像压缩与编码优化:通过引入U-Net的上/下采样块(down/up blocks),Transfusion能够将每张图像压缩为仅16个patch,同时仍保持高质量的生成效果。这种设计大幅减少了计算成本,使得模型更加高效。
4. 实验与结果
论文展示了一系列实验,验证了Transfusion在多个基准测试中的性能:
- 跨模态任务:在文本生成、文本到图像生成以及图像到文本生成等任务中,Transfusion的表现优于当前基准模型。尤其是图像生成任务,Transfusion相比于基于离散图像token的模型,能够更高效地处理图像数据,同时达到更高的生成质量。实验中,通过Frechet Inception Distance(FID)和CLIP得分的评估,Transfusion在计算开销不到Chameleon模型三分之一的情况下,表现更佳。
- 扩展性:通过对不同参数规模(从0.16B到7B参数)的Transfusion模型进行训练,作者发现模型规模的扩展带来了显著的性能提升,特别是在处理图像生成任务时,模型能够以更少的计算成本达到相同或更好的效果。
实验亮点:
- 图像生成质量:在MS-COCO基准测试中,Transfusion在生成图像的FID指标上显著优于其他方法,尤其是Chameleon模型。
- 多任务学习能力:Transfusion模型不仅在图像生成方面表现卓越,还能够生成高质量的文本,甚至在纯文本任务(如语言模型评估)中也表现出色。
5. 模型扩展与应用
- 压缩能力:通过实验发现,Transfusion模型可以有效地将每张图像压缩到极少的patch(如16个),这大大减少了模型处理图像的计算开销。即便在压缩条件下,模型仍能保持图像生成的高质量,这表明模型在大规模应用中的潜力。
- 推理优化:Transfusion采用了一种推理策略,允许模型根据文本生成图像,或者根据图像生成描述。生成时,模型根据不同模态自动切换推理模式,从而实现了文本和图像的无缝生成。
- 未来方向:Transfusion模型展示了在多模态生成任务中的巨大潜力,作者提出,未来可以探索更多扩展,如引入基于流匹配的生成模型(Flow Matching)来代替扩散模型,进一步提升模型性能。
6. 总结与未来展望
Transfusion模型通过结合语言模型的离散生成和扩散模型的连续生成,展示了一种新型的多模态学习范式。它不仅能够处理不同类型的模态数据(文本和图像),还在计算效率和生成质量上超越了现有的方法。论文展示了模型的扩展性与高效性,尤其是在处理多模态生成任务时,能够在较少的计算资源下取得优异的表现。未来,随着更多的优化和扩展,该模型有望在实际应用中发挥更大的作用。