微调是利用预训练的大型模型在特定下游任务上获得最佳性能的一种有效方法,特别是对于大型语言模型(LLMs)和其他基于Transformer的模型。然而,微调这些大型模型需要大量的计算资源和内存资源,尤其是当涉及到数十亿参数的模型时。例如,对于GPT-3(175B)或Llama(65B)这样的大模型,微调过程中需要分别高达1200GB和780GB的GPU内存。这种资源需求显然在实际应用中是极其昂贵和难以实现的,尤其对于那些资源有限的组织或个人开发者而言。因此,如何在保证模型性能的同时减少内存消耗成为了研究人员关注的重点。
现有的一些参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法,比如LoRA、QLoRA等,已经尝试通过减少参数量或进行参数量化来降低内存需求。然而,这些方法仍然需要在前向传播时缓存所有的中间激活,以便在反向传播时用于梯度计算。这些中间激活占据了大量的内存,尤其是在大模型上。因此,本文Memory-Efficient Fine-Tuning of Transformers via Token Selection提出了一种新的内存高效微调方法,名为TOKENTUNE,旨在通过选择一部分输入令牌进行微调,以减少对中间激活的存储需求,从而降低整体的内存消耗。
论文作者为Antoine Simoulin, , Namyong Park, Xiaoyi Liu, Grey Yang,均来自Meta。
如下为论文概要内容:
一、方法介绍:TOKENTUNE
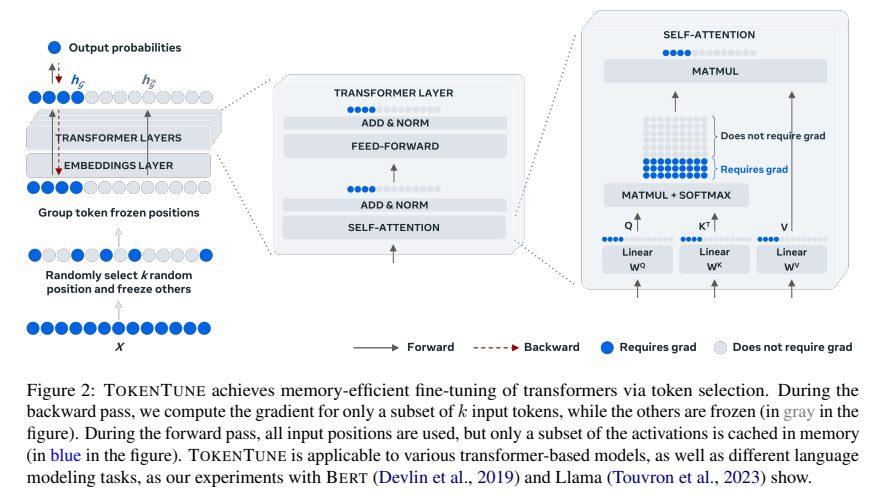
TOKENTUNE 的基本理念是在反向传播过程中仅对选定的输入令牌进行梯度计算,这意味着在前向传播时只需缓存这些选定令牌的中间激活,从而大幅降低内存开销。为了更好地理解TOKENTUNE的工作机制,下面将从几个方面详细描述其过程与方法。
1. 令牌选择策略
令牌选择策略 是TOKENTUNE的核心部分。在每次前向传播时,输入序列中的令牌被划分为两部分:一部分被选为“参与微调的令牌”,另一部分则被“冻结”,即在反向传播时不参与梯度计算。具体来说:
- 论文采用了一种随机令牌选择策略,即在每个输入序列中随机选择若干个令牌参与反向传播。这些选定的令牌将在反向传播过程中生成梯度,而未选中的部分则在计算时被忽略。
- 随机选择令牌的过程使用的是均匀分布,以确保没有任何令牌被偏袒。然而,为了使模型能够更好地理解整个输入语义,在每次选择时,总是包含表示全局信息的特殊令牌(如CLS令牌)。
- 在具体实现上,论文中提到使用PyTorch中的
torch.no_grad()机制来避免为未选中令牌的计算生成梯度,从而降低内存使用。
2. 对模型不同层的处理
为了使令牌选择策略能够在Transformer架构中得到有效应用,TOKENTUNE对不同类型的层(如密集层和注意力层)进行了特别处理:
- 密集层(Dense Layer):
- 在反向传播过程中,普通的微调方法需要计算所有输入的梯度,这包括计算与输入、权重、偏置等相关的所有中间激活。通过只选择部分令牌,TOKENTUNE减少了反向传播所需缓存的激活数量。
- 在实现中,作者将激活拆分为两部分:选定令牌的激活和未选定令牌的激活。在前向传播过程中,计算所有激活,但在反向传播时,仅对选定部分的激活生成梯度,从而减少内存占用。
- 注意力层(Attention Layer):
- 注意力机制是Transformer模型的重要组成部分,涉及对整个输入序列进行操作。为了适应部分令牌的选择策略,TOKENTUNE对查询、键和值(Query, Key, Value)的计算也进行了拆分。
- 在前向传播时,所有的查询、键和值都被计算,但在反向传播时,只计算选定令牌的梯度。这种处理方式使得模型在保留全局上下文信息的同时,显著减少了反向传播中的内存需求。
二、实验设计与结果分析
论文通过大量实验验证了TOKENTUNE在不同规模的模型上的有效性,涵盖了从中等规模(如BERT)到大规模模型(如Llama)的多个下游任务。
1. 微调中等规模模型的实验
在对中等规模的编码器模型(如BERT)进行实验时,研究者选择了GLUE基准测试作为评估基准。GLUE基准测试是一组包含多种自然语言理解任务的数据集,用于评估模型的泛化能力。实验设计中使用了BERT-large模型,并对比了以下几种微调方法:
- 全量微调(Full Fine-Tuning):对模型的所有参数进行更新,内存需求高,但通常能达到最佳性能。
- 不同PEFT方法:包括LoRA、Ladder Side Tuning等,这些方法尝试通过减少参数量来降低内存需求。
- TOKENTUNE:仅选择16个输入位置进行微调,以验证其在减少内存消耗的同时是否能保持与全量微调相近的性能。
实验结果:
- TOKENTUNE在GLUE上的平均得分接近全量微调,并且在某些任务上(如CoLA任务)性能与其他PEFT方法持平甚至更优。
- 在GPU内存的使用上,与全量微调相比,TOKENTUNE仅使用了约一半的内存,这意味着其可以在更低的硬件要求下实现对模型的高效微调。
2. 微调大规模模型的实验
为了进一步验证TOKENTUNE在大规模模型上的表现,研究者还对Llama2-7B模型进行了实验,特别是通过指令微调(Instruction Tuning)和少样本评估(Few-Shot Evaluation)的方式,来评估模型在处理复杂任务上的能力。
- 指令微调:使用开源的Open-Platypus数据集对Llama2-7B进行微调,并结合LoRA和QLoRA等方法进一步降低内存需求。
- 少样本评估:在多个任务(如MMLU、ARC、HellaSwag、TruthfulQA等)上进行少样本测试,以评估模型在只给出少量示例情况下的泛化能力。
实验结果:
- TOKENTUNE与LoRA、QLoRA结合使用时,可以显著降低大规模模型的内存需求。在Llama2-7B模型的微调中,通过结合QLoRA和TOKENTUNE,内存需求降低至全量微调的三分之一。
- 在少样本任务的表现上,TOKENTUNE与其他方法相当,甚至在某些任务上略有提高,这表明在减少内存需求的同时,性能损失可以忽略不计。
3. 令牌选择比例的影响
实验还研究了不同令牌选择比例对模型性能和内存需求的影响。在GLUE基准测试中,通过选择不同数量的输入令牌进行微调,发现当选定令牌的比例增加时,模型的性能逐渐提高,但在达到某一阈值后,性能的提升趋于平稳。
- 例如,当选择16个令牌时,模型的性能已经接近于选择全部令牌时的性能,但内存消耗却显著减少。因此,对于大多数任务,选择20%-30%的令牌作为默认比例可以在性能和内存之间取得良好的平衡。
三、方法优势与局限性
优势:
- 内存效率显著提高:通过仅选择部分输入令牌进行梯度计算,TOKENTUNE显著降低了存储中间激活的内存需求,尤其是在大型语言模型的微调过程中。
- 与现有方法兼容:TOKENTUNE可以与其他PEFT方法结合,如LoRA和QLoRA,从而进一步减少内存使用。这种兼容性使得其应用更加灵活,可以根据任务和硬件条件选择合适的组合策略。
- 性能保持不变或略有提升:尽管减少了内存需求,但在实验中,TOKENTUNE在多个任务上都表现出与全量微调相近的性能。这表明该方法在不牺牲模型能力的情况下,实现了更高的计算效率。
局限性:
- 选择令牌的策略简单:当前版本的TOKENTUNE使用的是随机选择令牌的策略,这种方法虽然简单有效,但可能不是最优的。未来的研究可以尝试引入更智能的选择机制,以进一步提高性能。
- 对特定任务的依赖性:在某些任务上,减少令牌可能会导致性能下降,特别是对于需要精确捕捉上下文关系的任务。因此,如何针对不同任务优化令牌选择策略仍然是一个开放的问题。
- 其他领域的应用尚待验证:虽然TOKENTUNE在语言模型的微调中表现良好,但其在其他领域(如计算机视觉中的Transformer架构)中的效果尚未得到验证。未来的工作可以探索其在更广泛领域中的适用性。
四、结论与未来工作
结论:本文提出了TOKENTUNE,一种通过选择输入令牌实现内存高效微调的创新方法。通过在前向传播中只缓存部分中间激活状态,TOKENTUNE显著降低了微调过程中对GPU内存的需求。实验结果表明,该方法能够与其他PEFT方法结合,进一步降低内存开销,同时保持与全量微调相近的模型性能。
未来工作:
- 优化令牌选择策略:未来可以探索更智能的令牌选择机制,比如基于令牌的重要性评分或上下文依赖关系,以进一步提高微调的效率和效果。
- 扩展到其他领域:目前的研究主要集中在自然语言处理领域,未来可以将该方法扩展到其他应用领域,如计算机视觉中的大规模模型,验证其在不同领域中的适用性和有效性。
- 理论分析与解释性:进一步的工作可以从理论上分析为什么仅选择部分令牌就可以保持与全量微调相近的性能,以及如何解释这种现象背后的机制,这对于理解深度学习模型的内在工作原理具有重要意义。