论文Distilling System 2 into System 1(《将系统2蒸馏到系统1》)研究了一种将复杂推理过程(称为系统2)“编译”回到标准大语言模型(LLM)输出的方式,即无需中间推理步骤的直接响应输出,这称为“系统1”。
论文作者为Ping Yu, Jing Xu, Jason Weston, Ilia Kulikov,均来自Meta FAIR。
1. 引言
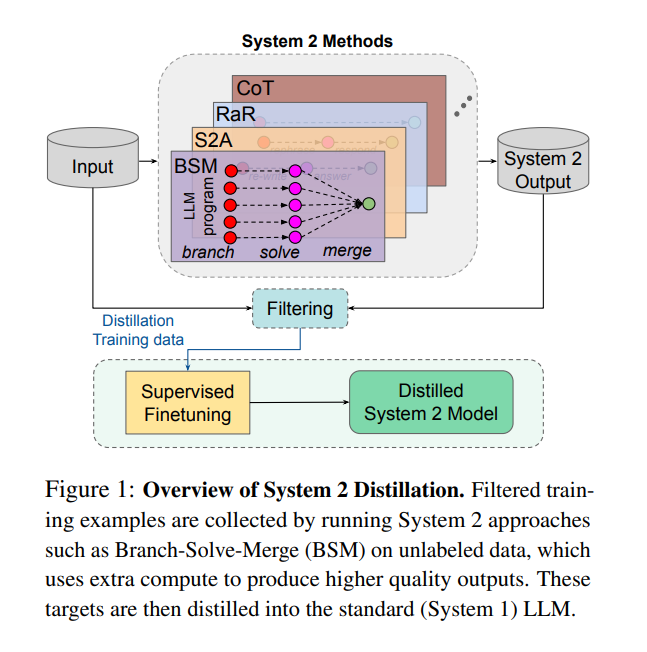
论文的核心目标是通过蒸馏的方法,将复杂推理(系统2)的优点“编译”或“转化”到更为直接的模型推理输出(系统1)中。大语言模型(LLMs)可以通过中间推理步骤来改善最终生成的结果,这类似于心理学中的“系统2”思考,即深度思考与分析的过程。然而,由于系统2推理在推理过程中产生了大量中间计算和结果,这种方法虽然能提升推理精度,但计算成本和延迟较高,难以在实际生产环境中应用。因此,本文旨在设计一种方法,以通过自监督的方式将系统2的推理过程“蒸馏”到系统1模型中,从而提高模型的效率,既保持推理能力,又能显著降低推理成本。
2. 背景与相关工作
2.1 系统1与系统2在心理学中的概念
- 系统1(System 1)是指快速、直觉化的思考过程,具有自动性,通常在无需特别注意的情况下完成。例如识别交通信号、面部识别、或对简单熟悉的符号作出判断。
- 系统2(System 2)则是深思熟虑的过程,需要消耗大量的认知资源,尤其在面对复杂问题或抽象符号处理(如代数运算)时,系统2的作用尤为重要。心理学中称这种从系统2到系统1的迁移过程为“自动化”(automaticity),即通过重复练习,复杂的推理任务逐渐内化成无需意识参与的技能,这类似于新手司机在多次驾驶同一路线后不再需要过多思考便能完成驾驶的过程。
2.2 大语言模型中的系统1和系统2
- 系统1模型:在LLMs中,系统1模型指的是直接给定输入并生成输出的方式,这种方法不涉及任何显式的中间推理步骤。其内部会计算中间的潜在表示,但这些表示是向量化的、分布式的知识,而不是离散的推理步骤,因此系统1模型难以直接处理复杂的符号推理任务。
- 系统2模型:系统2模型在生成最终答案之前会经过多个推理步骤,例如“链式思维”(Chain-of-Thought, CoT)、“树状思维”(Tree-of-Thoughts, ToT)等,通过这些步骤逐步完成推理任务。这些中间步骤为系统2模型提供了额外的推理能力,但也导致了较高的推理成本和延迟。
2.3 蒸馏技术
- 传统的模型蒸馏:通常是将一个强大的“教师”模型的知识蒸馏到一个较小的“学生”模型中,学生模型通过模仿教师模型的行为来提高自身的性能。例如,通过模仿输出分布(Hinton et al., 2015)、模仿教师模型的激活状态(Adriana et al., 2015)或模仿其目标输出的导数(Czarnecki et al., 2017)来训练学生模型。
- 本研究中的蒸馏:在本文中,教师模型和学生模型实际上是同一个模型,只是在训练方式上有所不同,即教师模型使用系统2推理生成中间推理步骤,而学生模型则试图在不生成这些中间步骤的情况下模仿教师的最终输出。
3. 系统2蒸馏的方法
系统2蒸馏的主要目标是将系统2的推理能力转化为系统1模型的直接推理能力,降低推理的时间和计算成本,同时提高推理的准确性。具体步骤包括:
3.1 设置:系统1与系统2模型
- 系统1(SI):直接生成输出,不产生中间步骤。输入为 x,通过模型 pθ(x) 直接得到输出 y。
- 系统2(SII):生成中间步骤 z,这些步骤用于推理过程中的多次调用,最终返回输出 y。
3.2 蒸馏方法
- 数据收集:从未标记的输入数据中,使用系统2方法(如Branch-Solve-Merge)生成相应的高质量输出。具体来说,系统2模型对输入数据进行多次处理,生成中间推理结果并最终生成高质量的输出结果。
- 质量过滤:通过无监督的一致性(self-consistency)标准来筛选生成的输出数据,确保其高质量。例如,通过对同一个输入多次生成结果,筛选出结果一致的样本,或者通过输入扰动(如改变输入顺序)测试模型输出的稳定性。
- 模型微调:使用经过筛选的数据集对系统1模型进行微调,使其在不需要生成中间步骤的情况下,直接生成高质量的输出。
4. 实验和结果
论文在多个任务和多种系统2方法上进行了广泛的实验,验证了系统2蒸馏方法的有效性。
4.1 实验设置
- 模型选择:使用了Llama-2-70B-chat作为实验的基础模型,并选择了多个系统2方法(如Rephrase and Respond, System 2 Attention, Branch-Solve-Merge)和五个不同的任务进行实验。
- 任务设置:包括简单的符号推理任务(如“最后字母串联”)、复杂的逻辑推理任务(如“硬币翻转推理”)以及评估LLM对复杂对话的理解和判断的任务。
4.2 Rephrase and Respond 蒸馏实验
- 任务描述:Rephrase and Respond(RaR)方法首先对输入问题进行重述,接着再对问题进行解答。其目的是通过重述来澄清问题,从而提升推理质量。
- 实验结果:
- 在“最后字母串联任务”中,通过RaR蒸馏后的系统1模型的准确率从30.0%提高到98.0%,显著超过了原始的系统1和系统2的性能。
- 在“硬币翻转推理任务”中,蒸馏后的系统1模型也能达到与2-Step RaR接近的性能,但推理时生成的token数量显著减少,从而降低了推理成本。
4.3 System 2 Attention 蒸馏实验
- 任务描述:System 2 Attention (S2A) 方法用于减少模型在推理时的偏差,通过重新编写输入文本来去除不相关的上下文或有偏见的信息,然后生成最终的答案。
- 实验结果:在处理包含偏见的输入时,蒸馏后的系统1模型表现优于系统1和系统2,生成的输出更为简洁,计算成本更低。与原始S2A相比,蒸馏后的模型不仅保持了一致性,还减少了推理过程中的偏见影响。
4.4 Branch-Solve-Merge 蒸馏实验
- 任务描述:Branch-Solve-Merge (BSM) 方法将复杂任务拆分为若干子任务并行处理,最后合并结果。其在评价任务中的性能显著高于常规的LLM,但推理成本较高。
- 实验结果:蒸馏后的BSM模型在评估任务中,表现优于未蒸馏的BSM方法,甚至超越了GPT-4在某些任务上的表现,但生成token的数量远少于系统2模型,因此大幅降低了推理成本。
4.5 Chain-of-Thought 蒸馏实验
- 任务描述:Chain-of-Thought (CoT) 方法通过生成中间推理步骤来解决复杂的数学推理任务。
- 实验结果:对于数学推理任务(GSM8k数据集),系统2蒸馏效果不佳,表明某些复杂推理任务仍难以通过这种方法直接转化到系统1模型。这也反映了系统2蒸馏存在的挑战和局限性。
5. 结论
论文证明了通过系统2蒸馏,模型可以在保持推理性能的同时显著降低推理成本,使得许多本来依赖复杂推理过程的方法可以应用于更高效的系统1模型中。这为未来的大规模高效AI系统的构建提供了一个重要的方向。
- 创新之处:通过自监督学习的方法,将系统2的推理步骤“编译”到系统1模型中,从而提高效率,减少计算资源的消耗。
- 应用前景:通过自动化和高效化系统2的推理过程,这些模型在未来可以专注于那些目前还不能很好处理的推理任务,就如人类通过自动化特定技能来解放认知资源一样。
6. 局限性与未来研究方向
- 蒸馏效果的任务依赖性:本研究证明了对某些系统2方法的成功蒸馏(如Rephrase and Respond, System 2 Attention等),但对于某些复杂的推理任务(如数学推理)则效果有限。
- 数据质量的影响:由于采用自监督学习,蒸馏效果依赖于训练数据的质量,本研究依靠一致性过滤来提高训练数据的质量,未来可以尝试其他无监督数据增强策略。
- 未来方向:未来研究可探索更为系统化的方法来识别哪些任务适合蒸馏,哪些不适合,从而提升模型在不同任务上的适应性。