Distilling the Knowledge in a Neural Network是Geoffrey Hinton、Oriol Vinyals和Jeff Dean于2015年发表的一篇“老”论文。三位作者均为AI界的大神。Geoffrey Hinton今天刚刚获得了2024年度诺贝尔物理学奖,他和John J. Hopfield同时获奖。Geoffrey Hinton也成为诺奖和图灵奖的双料得主。
This year’s two Nobel Laureates in Physics have used tools from physics to develop methods that are the foundation of today’s powerful machine learning. John Hopfield created an associative memory that can store and reconstruct images and other types of patterns in data. Geoffrey Hinton invented a method that can autonomously find properties in data, and so perform tasks such as identifying specific elements in pictures.
—
今年的两位诺贝尔物理学奖得主使用物理学的工具开发了奠定当今强大机器学习基础的方法。约翰·霍普菲尔德创造了一种联想记忆,可以存储和重构图像及其他类型的数据模式。杰弗里·辛顿发明了一种能够自主发现数据特性的算法,从而执行诸如识别图片中特定元素的任务。https://www.nobelprize.org/prizes/physics/2024/press-release
论文Distilling the Knowledge in a Neural Network提出了一种通过“知识蒸馏”(Distillation)技术,将大型神经网络或模型集合(ensemble models)中的知识压缩并传递给较小模型的方法。该方法的目标是通过减少计算资源需求的同时,保持原有复杂模型的良好性能。
以下是对论文的更详细解读:
1. 引言
传统上,为了提高机器学习模型的性能,人们会使用“模型集合”(ensemble models),即训练多个不同的模型并结合它们的预测结果。这种方法能够提高泛化能力和性能。然而,模型集合通常非常庞大,计算成本高,在实际应用中难以部署。为了克服这一问题,Caruana等人提出了“模型压缩”(Model Compression),通过将模型集合的知识压缩到单一模型中,减少计算负担。
本文的核心思想是利用一种更为高效的“知识蒸馏”技术,将模型集合中的知识转移到一个更小的模型中,这样小模型可以在不显著牺牲性能的情况下,更适合实际部署。作者通过在MNIST手写数字识别任务和语音识别任务上进行实验,验证了该方法的有效性。
2. 知识蒸馏的基本原理
在训练复杂的神经网络时,模型并不仅仅学习如何对输入进行分类,它还学习了大量关于输入样本的细微信息,例如类别之间的相似性。传统训练方法通常关注正确标签(hard targets),即将输入归为某个固定的类别,但这种方法忽略了模型在错误分类上的概率分布(soft targets)。这些“错误”的预测信息实际上反映了模型对类别之间关系的理解。知识蒸馏的核心思想正是利用这种额外的信息。
软目标(Soft Targets):大型神经网络通过softmax层输出概率分布,这不仅仅告诉我们正确类别的概率,还揭示了错误类别之间的概率关系。蒸馏方法通过使用软目标,将这种信息从大模型传递给小模型。小模型不仅仅学习正确答案,还学习到大模型如何在错误类别之间进行推断。
温度参数(Temperature)
为了让大模型输出的概率分布更平滑、更容易学习,作者引入了“温度参数”(T)。通过将softmax函数中的温度参数设置为一个较高的值,大模型的输出会更加平滑,从而提供更丰富的类别信息。公式如下:
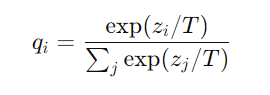
这里,zi是类i的logit值,T为温度。当T较高时,类别之间的概率分布更均匀;当T=1时,softmax函数恢复正常。
小模型的训练:小模型通过学习大模型在高温度下生成的软目标进行训练。在训练阶段,小模型的softmax也使用相同的高温度,但在最终部署时使用标准的T=1。除了软目标外,作者还建议将正确标签作为硬目标进行训练,结合两者,可以提升模型的准确性。
知识蒸馏的优势
- 信息密度高:软目标传递了比硬目标更多的信息。即使是错误的预测,软目标中包含的类别之间的相似性也能帮助小模型更好地理解数据。
- 减少数据量需求:通过蒸馏技术,小模型可以在较少的数据上进行训练,因为软目标提供了更丰富的类别关系信息。
- 提升泛化能力:小模型通过学习大模型的软目标,不仅能在训练数据上表现良好,也能在测试数据上有更好的泛化能力。
3. 实验设计与结果
3.1 MNIST手写数字识别任务
MNIST数据集包含60000张训练图像和10000张测试图像,任务是识别0到9的手写数字。作者在MNIST数据集上进行了一系列实验,以验证知识蒸馏的有效性。
- 大模型:作者训练了一个大型神经网络,包含两个隐藏层,每层有1200个ReLU激活的隐藏单元。该模型使用dropout进行强正则化,并在训练时对输入图像进行随机抖动(translation jittering)。该大模型在测试集上取得了67个错误。
- 小模型:一个较小的模型,包含两个隐藏层,每层800个单元,在没有正则化的情况下,测试集上的错误数为146个。
- 蒸馏后的小模型:将大模型的软目标用作训练小模型的指导,即使没有进行正则化,小模型也能将测试错误数减少到74个。这表明软目标能够有效传递大模型中的泛化能力。
此外,作者还进行了不同温度参数下的实验,发现当小模型的隐藏单元数量减少时,较低的温度(如T=2.5到4)效果更好。即使在训练集中完全去除某些数字(如数字3),蒸馏后的小模型仍能较好地识别这些数字,通过调整偏置,它甚至能够在没有见过训练样本的情况下达到98.6%的正确率。
3.2 语音识别任务
语音识别任务中,作者使用深度神经网络(DNN)进行声学模型的训练。DNN的输入为经过梅尔滤波的声学特征,输出为隐马尔可夫模型(HMM)的状态概率。
- 大模型:由8层,每层2560个ReLU单元组成,最终输出层为14,000个标签。该模型使用大规模语音数据进行训练,测试集上的词错误率(WER)为10.9%。
- 蒸馏模型:将大模型的软目标用于训练一个较小的模型,实验表明,蒸馏后的小模型在帧级别分类准确率上达到了60.8%,与10个大模型集合的平均预测结果(61.1%)相近。
3.3 专家模型(Specialist Models)
对于超大规模数据集(如谷歌的JFT数据集,包含1亿张图像,15,000个类别),训练单一大模型的时间成本极高,甚至无法完成。在这种情况下,作者提出了“专家模型”概念,即通过多个小模型来分别处理某些容易混淆的类别。
- 模型训练:每个专家模型专注于某个类别的子集,并与总模型(generalist model)共享部分权重。通过对这些子集进行软目标训练,可以避免过拟合,并大幅减少训练时间。
- 推理过程:推理阶段,首先由总模型判断哪些类别相关,然后调用相应的专家模型进行细粒度的分类。这种方法能够提高推理的准确性和效率。
4. 软目标作为正则化器
论文进一步讨论了软目标在小数据集上作为正则化器的作用。作者发现,当仅使用3%的训练数据时,直接使用硬标签训练会导致严重的过拟合,而使用软目标训练的小模型能够有效避免这种情况。即使只使用少量数据,软目标也能够帮助模型从中提取到丰富的信息,提升泛化性能。
5. 与专家模型(Mixture of Experts)的关系
论文还探讨了知识蒸馏与传统的专家模型方法的关系。传统的专家模型通过一个门控网络(gating network)来为每个样本选择合适的专家,而知识蒸馏中的专家模型则不需要这样的复杂结构,专家可以独立训练,并通过总模型的预测结果来决定哪些专家参与推理。
6. 总结与讨论
作者总结了知识蒸馏的优势,强调了该方法在将大模型或模型集合的知识压缩到小模型中的潜力。通过这种技术,模型在不显著牺牲性能的前提下,能够大幅减少计算开销,适合实际部署场景。
此外,论文还展望了未来的研究方向,例如如何将专家模型的知识进一步蒸馏到单个大模型中,进一步提高模型的性能和效率。
排版极为朴素的论文说明Slides:https://www.ttic.edu/dl/dark14.pdf