论文Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval提出的Re-Invoke是一种完全无监督的工具检索方法,旨在扩展LLM的工具使用能力以应对大规模工具集的挑战。通过生成多样化的合成查询和有效提取用户意图,Re-Invoke显著提升了工具检索的准确性,并在多个基准数据集上超越了当前最先进的方法。即使在用户查询包含多个潜在意图的情况下,Re-Invoke也能够高效地从大型工具集中检索到最相关的工具。该方法无需任何训练数据,展现了在无监督场景下高效工具检索的巨大潜力,为未来的工具增强型LLM系统提供了新的思路和方法。
论文作者为Yanfei Chen, Jinsung Yoon, Devendra Singh Sachan, Qingze Wang, Vincent Cohen-Addad, Mohammadhossein Bateni, Chen-Yu Lee, Tomas Pfister,均来自Google。
1. 引言
近年来,大语言模型(LLMs)在解决各种复杂任务(如数学、推理、编码等)方面展现了极其强大的能力。然而,LLMs的核心问题在于它们是基于静态语料库进行预训练的,这使得它们在应对快速变化的真实世界信息时存在局限性。频繁的微调可以一定程度上缓解这个问题,但其计算成本非常高。而人类通常通过各种工具,如搜索引擎、地图、计算器等来补充自身的知识并完成任务,因此一个自然的解决方案是通过工具集成来增强LLMs的能力。这种方法可以使模型在遇到不熟悉的信息时通过工具调用来解决。
然而,随着工具数量的增加,如何有效地从庞大的工具集中选择合适的工具成为了一个主要的瓶颈。传统的方法大多依赖于监督学习来完成工具调用的训练,但这些方法在扩展到大规模工具池时遇到显著困难:例如工具集的动态变化、输入令牌的长度限制,以及用户查询中模糊的意图识别问题。为了解决这些挑战,论文提出了Re-Invoke,一种全新的无监督工具检索方法,旨在通过自动生成合成查询和意图提取,实现高效、准确的工具调用。
2. 研究动机与挑战
论文在研究动机部分详细阐述了当前在工具调用中的关键挑战:
- 输入令牌长度的限制:LLMs在处理包含大量工具信息的上下文时,可能因输入长度限制而无法有效检索到相关工具。
- 工具池的动态变化:工具池中的工具可能会频繁更新,而现有的检索系统通常基于静态的标签进行训练。这种情况下,频繁的更新和再训练成本非常高昂。
- 用户意图的不明确性:用户查询通常含有大量背景信息,导致模型难以准确识别核心意图。例如用户在描述旅行计划时可能混杂了学习语言的需求,这种复杂的意图表达使得传统的检索系统难以准确匹配相关工具。
3. 方法概述
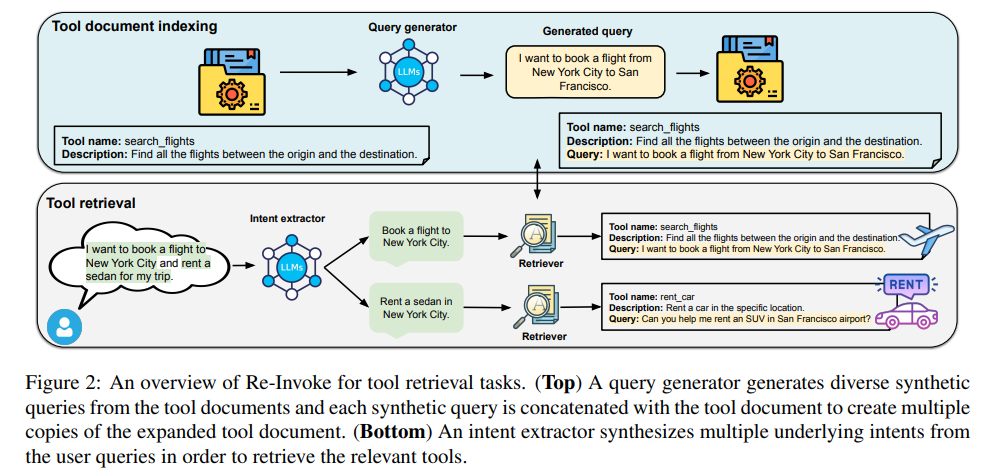
Re-Invoke方法主要由三个关键步骤组成:查询生成、意图提取,以及多视图相似度排序。
3.1 查询生成器(Query Generator)
查询生成器的作用是针对每个工具文档生成多样化的合成查询,以此来丰富工具文档的内容。具体来说,LLM会读取工具文档,并生成一组能被对应工具处理的查询。这些合成查询的生成通过提高采样温度(sampling temperature)实现,以确保生成的查询足够多样化,涵盖工具的不同应用场景。生成的查询与工具文档拼接,形成多个扩展后的工具文档,从而使得工具的表示更加丰富和全面,增强了检索的准确性。
生成查询的过程是完全无监督的,不依赖任何人工标注的数据。这使得Re-Invoke可以方便地应用到规模极大的工具集中,且不需要频繁的再训练。此外,生成查询的过程采用了诸如GPT-4、Gemini API、LLaMa等大规模语言模型。
3.2 意图提取器(Intent Extractor)
在推理阶段,用户的查询可能会涉及多个不同的意图,而这些意图可能被掩盖在大量的背景信息之中。意图提取器的任务就是从用户查询中提取出核心的工具相关意图,过滤掉与工具选择无关的内容。通过这种方式,提取到的意图可以与工具文档的嵌入向量进行相似度匹配,从而找到最相关的工具。该步骤的优势在于,它能有效地处理多意图查询,使得系统可以同时推荐多个工具来完成不同的子任务。
3.3 多视图相似度排序(Multi-view Similarity Ranking)
由于用户查询中的每个意图可能对应不同的工具,因此Re-Invoke引入了多视图相似度排序策略。具体来说,该方法首先通过多视图来衡量每个意图与工具文档之间的相似度,然后将多个意图的相似度得分进行聚合,从而得到最终的工具排序结果。这种方法不仅考虑了每个意图与工具文档的匹配度,还确保了每个意图都得到了充分的表达和检索。
在排序过程中,生成的工具文档会通过不同的合成查询进行扩展,每个工具文档在嵌入空间中表示为多个视角的嵌入向量。在实际检索中,系统首先计算每个意图与工具文档的相似度,然后根据这些相似度来对工具进行排序,并选择最合适的工具来满足用户的所有需求。
4. 实验与结果
论文采用了多个基准数据集来评估Re-Invoke的性能,包括ToolBench和ToolE数据集,这些数据集涵盖了工具检索的不同场景。以下是实验的详细内容和结果:
- 基准数据集:实验使用了ToolBench(包括I1, I2, I3)和ToolE数据集,其中ToolBench用于单工具和多工具检索性能的评估,而ToolE则主要用于多工具任务的检索。
- 实验评估指标:使用了nDCG@5(归一化折扣累积增益)作为主要的评估指标,这个指标用于衡量模型在检索任务中的排名质量。实验还使用了recall@k来评估检索的覆盖率。
- 实验结果:实验结果表明,Re-Invoke在所有基准数据集上均显著优于现有的稀疏和密集检索方法。例如,基于BM25的稀疏检索和基于Vertex AI嵌入的密集检索虽然已经具备一定性能,但在处理复杂意图和大规模工具集时表现不足。相比之下,Re-Invoke在ToolE数据集上的nDCG@5达到了39%的相对提升,显示了在多工具检索场景中的显著优势。
此外,实验还评估了Re-Invoke与不同语言模型的结合,如GPT-3.5-turbo和Mistral-7B,结果显示该方法在这些模型上的表现也非常优异,证明了其与不同基础模型的良好兼容性。
5. 模块分析与消融实验
为了验证Re-Invoke各个模块的有效性,论文进行了详细的消融实验,以确定每个模块对整体性能的贡献:
- 查询生成器的作用:仅使用查询生成器对工具文档进行扩展,能够显著提升检索性能,尤其是对文本描述较短的工具文档而言,查询生成器能够弥补工具描述中的信息不足。
- 意图提取器的作用:意图提取器在多意图的复杂查询中表现尤为重要,它能够有效地将用户的复杂查询拆解为多个独立的意图,提升了检索的准确性。
- 多视图相似度的贡献:通过结合多个视角的相似度计算,系统能够更全面地反映用户查询与工具文档之间的匹配情况,这对于那些包含多种工具使用场景的复杂任务尤为重要。
6. 详细分析与系统性能
- 延迟与计算成本:在工具文档索引阶段,Re-Invoke的查询生成器可以提前生成合成查询,因此在在线推理阶段不会增加额外的延迟。而意图提取器则需要在推理阶段调用LLM来提取用户意图,因此会带来一定的延迟和计算开销。论文建议可以通过知识蒸馏(Knowledge Distillation)和模型量化(Quantization)来降低延迟和计算成本。
- 实验分析:在比较稀疏检索和密集检索的过程中,Re-Invoke无论在稀疏还是密集的场景下都表现出显著的性能提升。这得益于其结合LLM的工具文档扩展和用户意图提取策略,这些策略有效地提高了工具文档的表示能力和用户意图的匹配精度。
7. 局限性与未来工作
论文还探讨了Re-Invoke的局限性及未来的研究方向:
- 合成查询的质量:合成查询的多样性和质量直接影响了检索性能。Re-Invoke目前通过LLM的简单采样来实现查询多样性,但未来可以探索更复杂的生成方法,如利用外部知识库进行控制式提示(Controlled Prompting)或迭代式改进。
- 意图提取器的改进:目前的意图提取依赖于LLM的内部知识,而未来可以结合下游代理的执行反馈来进一步优化意图提取过程,从而提高整体系统的检索准确性。