近年来,大规模语言模型(LLMs)的快速发展使其在推理、代码生成、科学计算等任务上展现出越来越强的能力,逐步缩小了与人工通用智能(AGI)之间的差距。然而,即使是最先进的 LLM,如 OpenAI 的 GPT-4o 和 Claude-3.5-Sonnet,仍然在一些高阶推理任务上存在一定局限性,特别是在长链推理(Chain-of-Thought, CoT)、数学推理、复杂编程问题解决等方面。
后训练(Post-training)已成为 LLM 发展过程中不可或缺的部分。近年来的研究表明,通过强化学习(Reinforcement Learning, RL)和监督微调(Supervised Fine-tuning, SFT),可以有效提升模型的推理能力,使其更好地对齐用户偏好,并在推理任务上取得更优表现。例如,OpenAI 的 o1 系列模型通过推理时动态扩展 CoT 长度,极大地提升了在数学、编程和科学推理方面的能力。然而,目前的研究仍然存在一些关键挑战:
- 推理能力的强化学习优化仍然是一个开放问题。尽管已有研究探索了基于过程奖励建模(Process-based Reward Modeling, PRM)、强化学习、搜索算法(如蒙特卡洛树搜索 Monte Carlo Tree Search, MCTS)等方法来提升推理能力,但尚未出现能够全面超越 OpenAI o1 系列的方案。
- 测试时推理能力的可扩展性仍然有限。在当前 LLM 研究中,如何让模型在推理过程中动态地优化自身思维链,并且有效扩展其推理深度,仍然是一个尚未完全解决的问题。
- 监督微调的依赖。大多数提升推理能力的工作都依赖于大量高质量监督数据进行微调,而获取这些数据往往成本高昂,并且可能限制模型的自适应推理能力。
在此背景下,本研究提出了 DeepSeek-R1,这是一个基于纯强化学习(RL)训练的推理优化 LLM,旨在探索如何在不依赖监督数据的情况下,通过强化学习激励模型自发学习推理能力。我们首先训练了DeepSeek-R1-Zero,这是一个完全由 RL 训练的模型,在无 SFT 预训练的情况下展现出强大的推理能力。然而,DeepSeek-R1-Zero 仍然存在可读性差、语言混杂等问题。因此,我们引入了冷启动数据(Cold Start Data),并采用多阶段强化学习训练策略,最终得到更稳定且推理能力更强的 DeepSeek-R1。
此外,我们还探索了蒸馏(Distillation)技术,以便将 DeepSeek-R1 的推理能力迁移到更小的模型,如 Qwen 和 Llama,使得小型模型也能获得强大的推理能力。研究表明,蒸馏的小模型在多个基准测试中超过了其他同类开源模型,如 QwQ-32B-Preview,甚至在某些任务上与 OpenAI-o1-mini 相媲美。
Credit: Deepseek
本研究的主要贡献:
- 纯强化学习驱动的推理能力优化:DeepSeek-R1-Zero 是首个完全基于强化学习训练的 LLM,在推理任务上取得了显著提升,而无需 SFT 预训练。
- 多阶段强化学习训练框架:DeepSeek-R1 采用冷启动数据和多轮 RL 迭代,最终在推理任务上达到了 OpenAI-o1-1217 的水平。
- 高效的蒸馏方法:我们将 DeepSeek-R1 的推理能力蒸馏至小型模型(1.5B-70B 参数规模),并发现蒸馏的小模型能够显著超越常规 LLM 训练方法所能达到的推理水平。
一、DeepSeek-R1-Zero:基于强化学习的推理能力自我进化
DeepSeek-R1-Zero 是在 DeepSeek-V3-Base(基础模型)上直接应用强化学习(RL)训练出的推理模型,其核心特点是完全不依赖监督微调(SFT)。这意味着该模型的推理能力完全通过 RL 训练过程中自我进化产生,而不是依赖人类提供的高质量训练数据。
训练 DeepSeek-R1-Zero 的核心方法包括:
- 强化学习算法:
- 采用组相对策略优化(Group Relative Policy Optimization, GRPO),该方法不使用传统的价值网络,而是通过对比多个策略输出的得分来进行优化。这种方法减少了计算成本,使 RL 训练更加高效。
- 奖励建模(Reward Modeling):
- 准确性奖励(Accuracy Rewards):在数学、编程等任务上,使用规则检测答案是否正确。例如,数学问题要求模型提供最终答案,并使用标准格式进行检查,而编程任务则利用编译器自动验证代码输出的正确性。
- 格式奖励(Format Rewards):训练时要求模型将推理过程包裹在
<think>...</think>标签中,并将最终答案包裹在<answer>...</answer>中,以确保输出结构的规范性。
- 自我进化过程:
- 训练过程中,DeepSeek-R1-Zero 在 AIME 2024 基准测试上的 pass@1 准确率从 15.6% 提升至 71.0%,并在多数投票(majority voting)模式下进一步提升至 86.7%,达到 OpenAI-o1-0912 的水平。
- 训练过程中,自然涌现了反思(Reflection)、自我验证(Self-verification) 等高级推理能力,表现出类似“顿悟”(Aha moment)的行为,即模型能够自发地重新审视自己的推理过程,并在必要时进行纠正。
尽管 DeepSeek-R1-Zero 展现出强大的推理能力,但它仍然存在一些明显的问题:
- 可读性较差:推理过程往往混杂多种语言,影响理解。
- 语言混杂:不同语言的混合输出导致文本难以阅读。
二、DeepSeek-R1:结合冷启动数据与强化学习的增强版模型
为了解决 DeepSeek-R1-Zero 的可读性问题,研究团队提出了 DeepSeek-R1,并引入了冷启动数据(Cold Start Data)和多阶段训练策略。DeepSeek-R1 的训练流程包括:
- 冷启动数据的引入:
- 采集包含详细 Chain-of-Thought(CoT) 的高质量数据,对 DeepSeek-V3-Base 进行微调,以提供一个更稳定的 RL 训练起点。
- 通过人工筛选与后处理确保数据可读性,避免语言混杂。
- 推理强化学习(Reasoning-Oriented RL):
- 采用类似 DeepSeek-R1-Zero 的 RL 训练方法,并额外引入语言一致性奖励(防止不同语言混杂)。
- 拒绝采样与监督微调(Rejection Sampling & SFT):
- 从 RL 生成的样本中筛选高质量推理数据,进行额外的 SFT 训练。
- 额外加入非推理任务(如写作、问答等)的数据,以提升模型的通用能力。
- 最终强化学习优化(Final RL Fine-tuning):
- 在全领域任务(推理、写作、编程等)上应用 RL,使模型更好地对齐人类偏好。
最终,DeepSeek-R1 在多个推理任务上达到了 OpenAI-o1-1217 的水平,并在部分任务上超越。
三、蒸馏小模型
研究团队还将 DeepSeek-R1 的推理能力蒸馏到更小的模型,如 Qwen 和 Llama。结果表明,蒸馏的小模型在多个基准测试中超过了其他同类开源模型,如 QwQ-32B-Preview。
四、实验与评估
研究团队在多个基准测试上评估了 DeepSeek-R1 及其蒸馏模型,主要包括数学推理、代码推理、知识问答以及通用文本生成任务。实验结果表明,DeepSeek-R1 在多个基准测试中达到了或超越了 OpenAI-o1-1217 的水平,而其蒸馏模型在小型参数规模下也展现出强劲的推理能力。
1.DeepSeek-R1 评估
DeepSeek-R1 在多个基准测试上的表现均优于 DeepSeek-R1-Zero,并在部分任务上超越 OpenAI-o1-1217:
- 数学推理(AIME 2024, MATH-500):
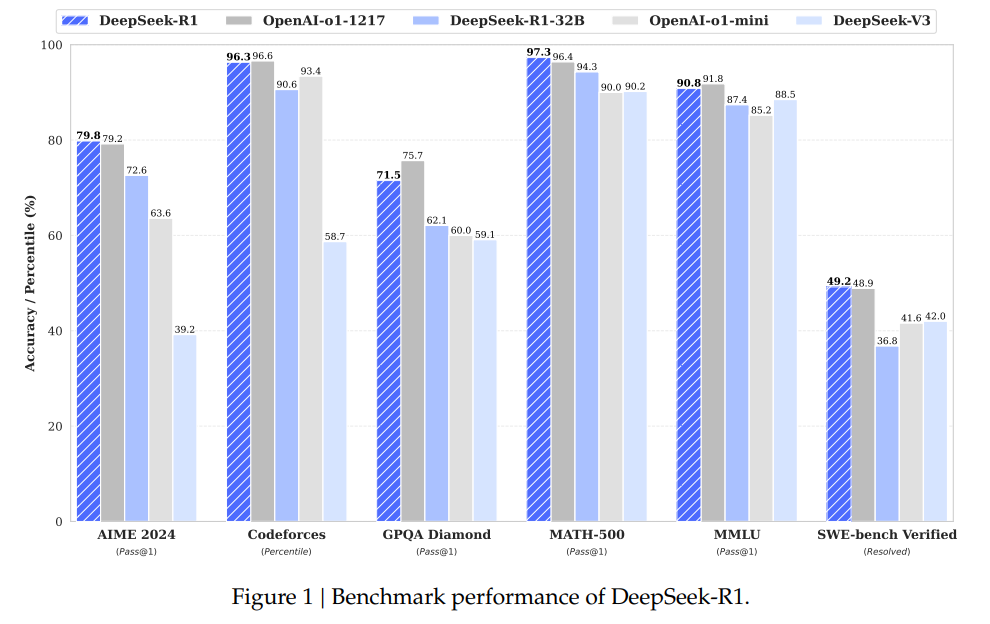
- 在 AIME 2024(美国数学邀请赛)上,DeepSeek-R1 的 pass@1 得分达到 79.8%,超越 OpenAI-o1-1217(79.2%)。
- 在 MATH-500 数据集上,DeepSeek-R1 的 pass@1 得分高达 97.3%,略高于 OpenAI-o1-1217(96.4%)。
- 代码推理(Codeforces, LiveCodeBench):
- 在 Codeforces 编程竞赛任务上,DeepSeek-R1 取得 96.3% 的人类排名百分比(percentile),Elo 评分为 2029,与 OpenAI-o1-1217(Elo 2061)接近。
- 在 LiveCodeBench 代码生成任务上,DeepSeek-R1 的 pass@1 得分为 65.9%,优于 OpenAI-o1-mini(53.8%)。
- 知识问答(MMLU, GPQA Diamond):
- 在 MMLU(多任务语言理解)测试上,DeepSeek-R1 取得 90.8% pass@1,略低于 OpenAI-o1-1217(91.8%),但显著优于 DeepSeek-V3(88.5%)。
- 在 GPQA Diamond(高难度知识问答)测试中,DeepSeek-R1 取得 71.5% pass@1,超越 DeepSeek-V3(59.1%)。
- 开放式文本生成:
- 在 AlpacaEval 2.0 测试中,DeepSeek-R1 以 87.6% 的胜率 超越 Claude-3.5 和 GPT-4o。
- 在 Arena-Hard 测试中,DeepSeek-R1 以 92.3% 的胜率 超越 GPT-4o 和 OpenAI-o1-mini,展现出在通用任务上的强大能力。
2.蒸馏小模型评估
研究团队还将 DeepSeek-R1 的推理能力蒸馏到更小的模型,如 Qwen 和 Llama,发现:
- DeepSeek-R1-Distill-Qwen-7B 超越 QwQ-32B-Preview:
- 在 AIME 2024 上,DeepSeek-R1-Distill-Qwen-7B 取得 55.5% pass@1,显著超过 QwQ-32B-Preview(50.0%)。
- 在 MATH-500 上,DeepSeek-R1-Distill-Qwen-7B 取得 92.8% pass@1,超过 OpenAI-o1-mini(90.0%)。
- DeepSeek-R1-Distill-Qwen-32B 和 DeepSeek-R1-Distill-Llama-70B 超越 OpenAI-o1-mini:
- 在 GPQA Diamond、LiveCodeBench 以及 Codeforces 等推理任务上,DeepSeek-R1 的蒸馏模型均超越了 OpenAI-o1-mini,并与 OpenAI-o1-1217 接近。
实验结果表明,蒸馏后的小模型在推理任务上的表现大幅超越同等参数规模的 LLM,表明 DeepSeek-R1 的推理能力可以高效地迁移到小模型上。
五、讨论
1.蒸馏 vs 强化学习
研究团队发现,直接对小模型进行强化学习的效果不如蒸馏。实验表明:
- 直接使用 RL 训练的 32B 模型(DeepSeek-R1-Zero-Qwen-32B),其推理能力仅与 QwQ-32B-Preview 持平。
- 而蒸馏后的 DeepSeek-R1-Distill-Qwen-32B 则显著优于前者,在多个推理任务上都超过了 QwQ-32B-Preview。
这一发现表明:
- 蒸馏可以高效地将大型模型的推理能力迁移到小型模型上,并且比直接对小模型进行 RL 训练更高效。
- 小模型仍然受到计算资源的限制,即使应用大规模 RL 训练,效果仍不及从大型模型蒸馏而来的版本。
2.失败尝试
在研究过程中,研究团队还尝试了一些方法,但发现它们在大规模推理任务中的效果有限:
- 过程奖励模型(PRM):
- 该方法试图通过奖励推理过程中的每个中间步骤来引导模型。然而,在通用推理任务上,精确定义每一步是否正确非常困难,并且容易导致奖励作弊(reward hacking),即模型通过某些捷径获取高分,而非真正优化推理能力。
- 蒙特卡洛树搜索(MCTS):
- 受 AlphaGo 启发,研究团队尝试使用 MCTS 进行推理优化。然而,语言任务的搜索空间远大于围棋或国际象棋,导致 MCTS 难以扩展。此外,由于 MCTS 需要依赖精确的价值网络,而当前语言模型的价值估计仍然存在不稳定性,因此最终未能成功提升推理能力。
六、结论与未来方向
本研究证明了纯强化学习可以有效提升 LLM 的推理能力,并提出了一种结合冷启动数据和多阶段 RL 训练的方法,最终训练出性能接近 OpenAI-o1-1217 的 DeepSeek-R1。此外,研究团队还探索了蒸馏策略,并成功将 DeepSeek-R1 的推理能力迁移到小型模型,显著提升了小模型的推理水平。
未来,研究团队计划继续优化:
- 通用能力:
- 目前 DeepSeek-R1 在函数调用(function calling)、多轮对话(multi-turn dialogue)、复杂角色扮演(complex role-playing)等任务上的表现仍有提升空间。
- 语言一致性:
- 目前 DeepSeek-R1 主要针对中英文优化,在处理其他语言时可能会出现语言混杂的情况。未来计划扩展至多语言支持。
- 提示工程(Prompt Engineering):
- 研究发现,DeepSeek-R1 对提示词(prompt)较为敏感,特别是少样本(few-shot)提示往往会降低推理表现。因此,未来将优化提示设计,使模型在不同提示下保持稳定表现。
- 软件工程任务:
- 由于代码评估时间较长,导致大规模 RL 训练在软件工程任务上的优化仍然有限。未来计划通过拒绝采样(Rejection Sampling)或异步评估来提升模型在软件工程任务上的表现。
DeepSeek-R1 及其蒸馏模型的开源预计将进一步推动 LLM 在推理任务上的发展,并为研究社区提供更强大的推理能力工具。
参考阅读:OpenAI o3-mini 系统说明(OpenAI o3-mini System Card)