论文Gated Delta Networks: Improving Mamba2 with Delta Rule提出了Gated DeltaNet架构,通过结合门控机制和Delta更新规则,提升线性Transformer在长序列建模和信息检索任务中的表现。
论文作者为Songlin Yang, Jan Kautz, Ali Hatamizadeh,来自NVIDIA。
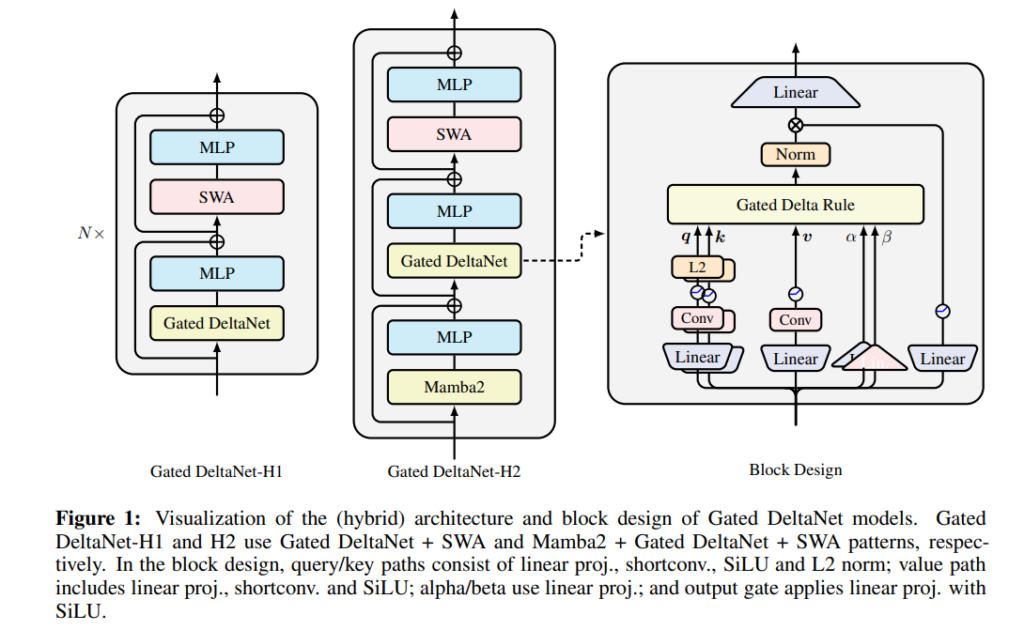
一、研究背景与动机
Transformer架构因其卓越的自注意力机制,在大规模语言模型(LLM)中取得了显著的成果。然而,Transformer的自注意力机制具有平方级的计算复杂度,随着序列长度的增加,计算开销急剧增加,导致训练和推理的资源需求极高。为了解决这一问题,研究者们提出了线性Transformer模型,旨在通过改进注意力机制的计算方式,降低其计算复杂度。线性Transformer的关键思想是用核化的点积注意力替代传统的softmax注意力,从而使得计算复杂度由传统的 O(L2) 降低至 O(L),其中L是序列的长度。
尽管线性Transformer模型在推理阶段大幅提升了计算效率,但它们仍然存在一些局限性,尤其是在处理长序列和进行信息检索任务时。例如,当序列长度超过模型的维度时,线性Transformer会面临“记忆碰撞”的问题,导致无法精确检索重要信息。为了解决这一问题,Mamba2模型引入了门控机制和衰减规则,以增强长序列建模能力。然而,Mamba2在记忆管理上仍然存在不足,特别是在需要动态清除记忆时的处理能力较弱。为此,本文提出了Gated DeltaNet架构,通过结合门控机制和Delta更新规则,旨在提升线性Transformer在长序列建模和信息检索任务中的表现。
二、主要贡献与创新点
- 提出了门控Delta规则:本文提出了一种新的记忆更新机制——门控Delta规则。该规则通过引入一个数据驱动的门控因子来动态调整记忆更新过程,使得模型能够在需要时迅速清除不再需要的信息,同时又能够高效地更新重要的记忆内容。与传统的线性Transformer模型相比,门控Delta规则在记忆管理上更具灵活性和精确性。
- 并行训练算法的优化:为了高效地实现门控Delta规则,本文提出了一种硬件高效的并行训练算法。该算法利用了最新的硬件加速技术,如GPU的张量核心,以实现大规模并行计算,显著提升了模型训练的速度和效率。
- 混合模型架构:在Gated DeltaNet的基础上,本文还提出了几种混合模型架构,将Gated DeltaNet层与滑动窗口注意力(SWA)或Mamba2层结合。这些混合模型在性能上较单一的Gated DeltaNet模型有显著的提升,尤其是在长序列和信息检索任务上。
三、模型原理与设计
1.线性注意力的基础:
线性Transformer模型的核心思想是将传统的softmax注意力机制替换为一种基于矩阵运算的核化点积注意力机制。传统的自注意力计算复杂度为 O(L2),而线性注意力通过改变注意力机制的计算方式,能够将复杂度降低到线性级别,即 O(L)。其计算过程可以看作是一个递归的线性更新过程,公式为:
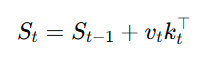
其中,St是在第t步的状态,vt和 kt分别是输入的值和键,矩阵乘法的结果代表了模型的状态更新过程。
2.Delta规则与门控机制的结合:
Delta规则通过每次更新时对记忆进行增量修改,从而保持记忆的连续性。该规则的更新公式为:
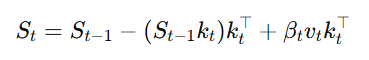
其中,βt是更新的比例因子,它决定了新旧信息的权衡。在Delta规则中,旧的键值对被替换为新的键值对,但每次更新只会修改一个键值对,因此对于需要快速清除旧信息的任务,Delta规则的表现可能会受到限制。
为了解决这一问题,Gated DeltaNet提出了门控Delta规则,通过在Delta规则的基础上引入门控机制。门控因子αt决定了记忆的衰减程度,从而能够灵活地清除不再需要的记忆内容。门控Delta规则的更新公式为:
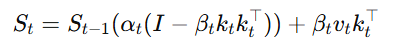
通过这种方式,模型能够在需要时清除不再需要的记忆,同时更新重要的信息。
3.硬件高效的并行训练:
为了使门控Delta规则能够在大规模数据上高效训练,本文提出了硬件高效的并行训练算法。通过使用GPU的张量核心(Tensor Core)加速矩阵乘法操作,并结合分块并行计算(chunkwise parallelism),模型能够在保持训练效率的同时,最大化硬件资源的利用率。该方法的关键在于将输入序列拆分成多个小块,并通过每个小块的最终状态来计算输出。这种分块并行形式不仅可以减少计算复杂度,还能够在多GPU环境下有效分配计算任务,从而提升训练速度。
四、实验分析
1.语言建模与常识推理:
在语言建模任务中,Gated DeltaNet相比传统的线性Transformer模型,如Mamba2和DeltaNet,在困惑度(perplexity)上表现出色。实验结果显示,Gated DeltaNet在处理长序列时能够更好地管理记忆,显著降低了模型的困惑度,尤其是在常识推理任务中的准确率也得到了提升。此外,混合模型(如Gated DeltaNet-H1和Gated DeltaNet-H2)进一步提高了性能,特别是在处理复杂推理任务时,混合模型的优势更为明显。
2.长序列外推能力:
在处理超长序列时,Gated DeltaNet展现了较强的外推能力。实验中,模型在长度达到20K的序列时仍能保持较低的困惑度,而传统的线性Transformer模型(如DeltaNet)则在面对长序列时表现出较大的困惑度。通过结合滑动窗口注意力和门控DeltaNet层,混合模型在长序列推理任务上表现得更为稳定。
3.信息检索与记忆管理:
在S-NIAH基准测试中,Gated DeltaNet在单针检索(S-NIAH-1)任务中的表现优于Mamba2和DeltaNet,尽管在某些更复杂的任务(如S-NIAH-2和S-NIAH-3)中,Gated DeltaNet的检索准确率略有下降,但依然优于其他模型。Gated DeltaNet通过其门控Delta规则,有效地管理了记忆的清除与更新,避免了因记忆碰撞导致的检索失败。
4.训练效率与吞吐量:
Gated DeltaNet的训练吞吐量与DeltaNet几乎相当,且远超Mamba2。这得益于门控Delta规则和硬件加速训练算法的优化,特别是在利用GPU的张量核心进行高效计算时,模型的训练速度得到了显著提升。通过这种硬件高效的训练方法,Gated DeltaNet能够在短时间内处理大量数据,且保持较高的计算效率。
五、结论与未来方向
Gated DeltaNet通过结合门控机制与Delta规则,显著改善了线性Transformer在长序列建模和信息检索任务中的能力。它不仅在多个基准任务中展现了优异的性能,还通过硬件高效的并行训练算法,大幅提升了模型训练效率。未来的研究可以进一步探索Gated DeltaNet在超长序列上的表现,并尝试将更多先进的混合架构结合到Gated DeltaNet中,以解决更复杂的任务。
Gated DeltaNet on GitHub: https://github.com/NVlabs/GatedDeltaNet