论文《Star Attention: Efficient LLM Inference over Long Sequences》提出了一种名为“星状注意力(Star Attention)”的算法,用于提高大型语言模型(LLM)在长序列推理任务中的效率。Star Attention 提出的两阶段块稀疏注意力机制为长序列推理提供了一种有效的解决方案,通过引入锚块来保持注意力的全局一致性,减少了计算和内存负担。这种方法不仅能够在推理任务中显著提升效率,还为未来的长序列建模提供了新的思路,即通过分布式的方式保持全局信息的一致性,同时实现高效的局部计算。
论文作者为Shantanu Acharya, Fei Jia, Boris Ginsburg,均来自Nvidia。
1. 背景与挑战
近年来,大型语言模型(LLMs)的发展极大地推动了自然语言处理任务的进步,特别是在长序列推理任务中(如多文档摘要、代码库分析等)。随着模型上下文长度的增加,传统的 Transformer 模型的自注意力机制面临巨大的计算和内存开销,这是由于自注意力的计算复杂度是二次的(O(n^2))。因此,当上下文长度达到数十万甚至百万个标记时,注意力计算带来的内存和计算负担极大地限制了模型的应用。
为了解决这个问题,许多方法被提出以降低内存消耗和提升推理速度,例如 Flash Attention 通过在 GPU 上高效实现全局注意力来减少内存开销和运行时间,而 Ring Attention 通过将注意力计算分布到多个设备上来提高可扩展性。尽管这些方法在某些方面提高了效率,但仍然存在通信开销大和难以进一步扩展的问题。
2. Star Attention 方法详解
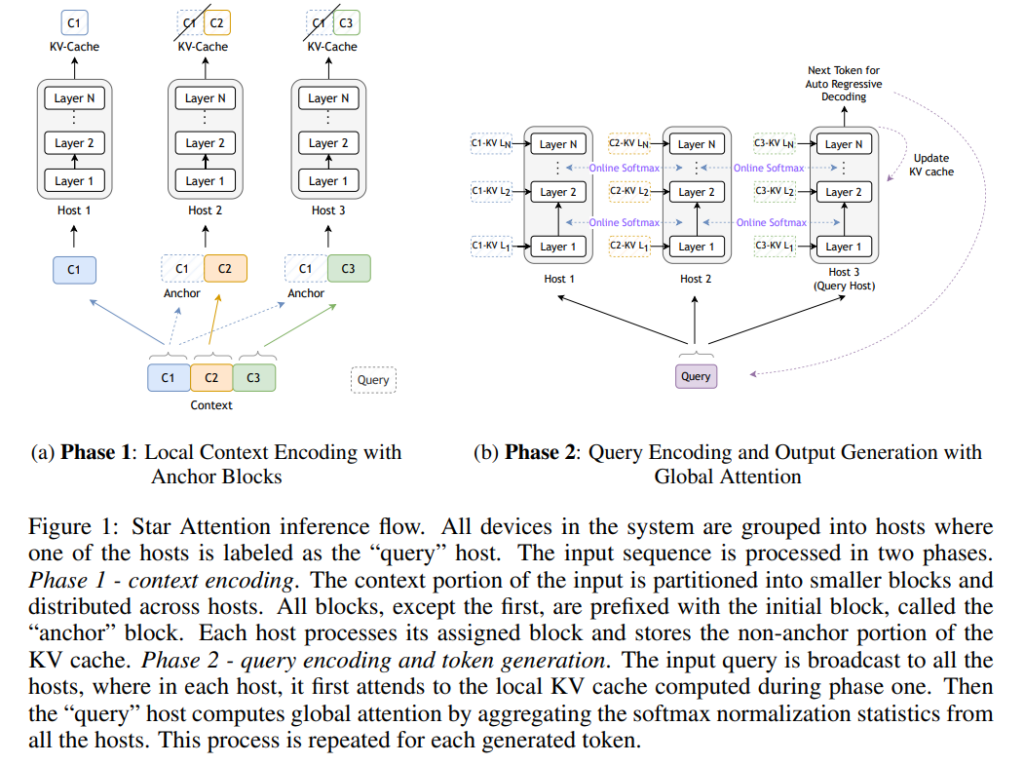
论文中提出的 Star Attention 是一种针对长序列推理任务设计的高效块稀疏注意力机制,旨在显著减少自注意力的计算复杂度和内存需求,同时保持模型精度。Star Attention 包含两个阶段的处理:阶段一是上下文编码,阶段二是查询编码与生成。
2.1 阶段一:上下文编码(Context Encoding)
在上下文编码阶段,输入序列被分割为多个块,并分配给不同的计算节点,每个节点独立计算自己的块,这样的方式可以显著降低计算的复杂度。
- 上下文分块(Blockwise Context Encoding):输入序列被划分为连续的多个块,每个块被分配到一个不同的“上下文主机(context host)”进行处理。每个块还会包含序列的首块,这个首块被称为“锚块(Anchor Block)”。锚块的作用是为每个块提供统一的全局参考,确保整个模型中生成的一致性和精确性。
- 块局部注意力(Blockwise-Local Attention):每个主机只计算分配给它的块的自注意力,并且不需要与其他主机通信。由于每个块都有锚块作为参考,这样的局部注意力机制可以降低复杂度为线性,同时还保持相当的注意力质量。这种处理方式类似于 Ring Attention 但避免了“环形”通信,从而减少了通信带来的延迟。
具体地,锚块的引入是为了消除块间注意力计算中由于缺乏全局信息而导致的注意力偏差问题。在没有锚块的情况下,每个块只能看到自己的内容,这会导致在块的开头产生大量的“注意力沉(attention sink)”,即注意力集中在每个块的第一个标记上。通过在每个块前加入锚块,注意力沉现象被移到锚块上,从而使得注意力模式更接近全局注意力,同时保持计算的线性复杂度。
2.2 阶段二:查询编码与生成(Query Encoding and Token Generation)
在生成阶段,模型进入第二阶段,即对查询进行编码并生成输出。
- 查询与生成:查询被广播到所有上下文主机,每个主机计算本地的注意力输出,然后将结果发送到“查询主机(query host)”。查询主机收集所有上下文主机的输出,通过全局 softmax 计算出全局注意力,从而生成新的标记。
- 分布式 softmax:Star Attention 使用了一种在线 softmax 算法来实现全局注意力,该算法只需在各主机之间传递一个标量(代表 softmax 分母)和一个向量(代表注意力输出),显著降低了通信开销。
这种分布式的注意力计算方式通过减少跨节点的 KV(键值对)传输,极大地提升了效率,并确保了全局 attention 的正确性。此外,由于 Star Attention 是基于 Transformer 的通用注意力机制,可以无缝集成到大多数已经通过全局注意力训练的 Transformer 模型中,而无需额外的模型微调。
3. 实验与结果分析
为了验证 Star Attention 的有效性,论文在 Llama3.1 系列模型(包括 Llama3.1-8B 和 Llama3.1-70B)上进行了多个长序列推理实验,涵盖了从 16K 到 1M 标记长度的推理任务。主要评估指标为推理速度和推理精度的权衡。
3.1 实验设置
- 模型与基线:实验在多个版本的 Llama 模型上进行,包括支持长上下文长度的 Llama-3.1-8B 和 Llama-3.1-70B。在基准对比中,Star Attention 与 Ring Attention 作为对比对象,后者通过环形通信来实现全局块注意力。
- 评估基准:使用了 RULER 和 BABILong 基准来评估模型的性能。RULER 基准包括 13 个任务,涵盖了从简单查询到多跳推理、聚合等多种类型的任务;而 BABILong 基准则测试了在超长上下文下对复杂关系的推理能力。
3.2 结果分析
- 速度与精度的权衡:Star Attention 在推理速度上相比 Ring Attention 提高了最多 11 倍,并且保持了 95%-100% 的精度。尤其是在长序列(如 128K 标记及以上)上,Star Attention 的优势更加明显。模型在长序列任务中的表现表明,通过使用适当大小的锚块和上下文分块,可以在速度和精度之间找到良好的平衡点。
- 任务类别分析:在 RULER 基准中,不同任务对模型的要求有所不同。Star Attention 在简单的单点查询(Single-NIAH)和聚合任务中表现与全局注意力几乎一致,而在需要跨越多个块的信息传递的多跳推理任务中(Multi-Hop Tracing),由于块间缺乏通信,精度有一定的下降。
4. 消融实验:锚块的作用与影响
为更好地理解锚块的作用,论文进行了多项消融实验来分析锚块的内容和位置对模型性能的影响。
4.1 锚块的位置与内容
- 位置变化:实验发现,锚块的位置(即锚块的位置 ID 是否变化)对模型的影响较小,无论锚块的位置 ID 是随机生成,还是与上下文块保持一致,模型的精度变化不大。
- 内容变化:锚块的内容对模型的影响非常显著。实验测试了锚块内容的多种配置,包括使用单一重复标记、随机标记、打乱的首块内容等,结果表明,只有保留原始的首块内容才能使模型保持最佳的性能。这意味着锚块在上下文块中充当了全局信息的角色,其内容对于保持注意力模式的一致性至关重要。
4.2 锚块的大小
实验还分析了锚块大小对模型性能的影响,结果表明,随着锚块大小的增加,模型的精度显著提高。特别是在序列长度为 128K 的实验中,当锚块大小与上下文块大小一致时,模型的精度最高。这表明锚块的作用不仅仅是减少注意力沉现象,它还可能承担了其他维持模型性能的重要作用。
5. 结论与未来工作
Star Attention 通过结合块式局部注意力和全局注意力的机制,显著提升了长序列推理的效率,在大幅减少计算复杂度和内存需求的同时,保持了较高的精度。该方法无需对已有的 Transformer 模型进行微调,可以直接集成到大多数基于全局注意力的 LLM 中。
尽管取得了显著进展,论文也指出了一些未来需要解决的问题:
- 锚块机制的进一步优化:如何选择最优的锚块大小和内容以在复杂任务中进一步提升模型的性能。
- 块间通信的改进:当前 Star Attention 的局部块处理虽然提高了效率,但在多跳推理等需要块间通信的任务中表现不如全局注意力。未来可能需要探索如何在保证效率的前提下引入有限的块间通信,以改善模型在复杂任务中的表现。
- 更复杂的长序列任务:未来的工作将关注如何改进锚块机制,使得 Star Attention 在更加复杂的长序列推理任务中表现更加稳健,特别是在多跳推理和需要跨越上下文的大范围聚合任务中。
Star Attention on GitHub: https://github.com/NVIDIA/Star-Attention