论文《Hymba: A Hybrid-head Architecture for Small Language Models》提出了一种名为Hymba的小型语言模型架构。Hymba通过将Transformer注意力机制与SSM(State Space Models,状态空间模型)并行结合,成功解决了小型语言模型中高精度回忆与计算效率之间的矛盾。通过元记忆、KV共享和滑动窗口优化等多种技术手段,Hymba在多项任务上实现了新的性能记录。
论文作者为Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, Pavlo Molchanov,主要来自Nvidia。
1. 背景与动机
Transformer架构因其强大的性能和并行处理能力在语言模型中占据主导地位,其通过Key-Value(KV)缓存能够实现长程记忆。然而,Transformer的计算复杂度为平方级(O(N^2)),在处理长序列时,其计算成本和内存需求成倍增长,这对小型模型尤其不利。另一方面,状态空间模型(如Mamba、Mamba-2)采用线性复杂度,适合硬件优化,但在高精度的记忆任务上存在不足,尤其是在复杂语言理解与生成任务中,表现出较差的回忆能力。为解决这些问题,Hymba提出了一种新颖的混合头架构,结合了Transformer的注意力机制和SSM,力求兼顾计算效率与高效的记忆处理能力。
2. Hymba的混合头架构
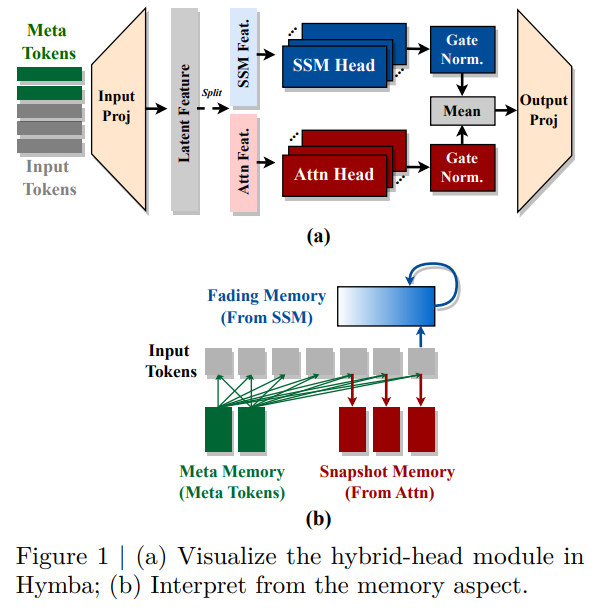
Hymba的创新在于提出了混合头架构,将Transformer注意力头和SSM头集成在同一层中,以并行方式处理相同的输入。这种设计在每一层中实现了高分辨率的回忆能力(来自于注意力机制)和高效的上下文摘要能力(来自于SSM),从而显著提高了模型在处理不同类型信息时的灵活性和表现。
2.1 混合头的优势
传统的混合模型通常通过层叠方式(即将注意力层和SSM层按顺序堆叠)结合两种机制。然而,这种方式存在潜在的瓶颈:某些任务可能对特定层的需求不匹配,导致后续层不得不对前面未处理好的信息进行补偿,从而影响整体性能。而Hymba通过并行融合注意力头和SSM头,使得每一层可以同时访问和处理相同的信息,充分利用两种机制的优势,增强模型处理复杂上下文和回忆任务的能力。
3. 元记忆(Meta Tokens)
为了进一步优化模型的性能,Hymba引入了可学习的元记忆(Meta Tokens),这些token被预置到输入序列的最前面。这些Meta Tokens承担着类似于知识压缩的角色,它们在整个序列中与后续token交互,起到了缓解注意力机制负担的作用,尤其是在滑动窗口注意力(Sliding Window Attention)中,可以有效避免注意力机制因缺乏足够的全局信息而性能下降的问题。
Meta Tokens相当于模型的记忆初始状态,可以在推理阶段通过学习到的特征,预先对后续token的处理进行调节。具体而言,这些Meta Tokens在推理过程中固定不变,并且在序列开头进行离线计算,其目的是初始化KV缓存和SSM状态,增强模型对重要信息的聚焦能力。论文通过实验发现,这些Meta Tokens在不同任务中会呈现不同的激活状态,意味着它们在学习过程中捕获了任务相关的知识,并在推理过程中帮助模型更有效地分配注意力。
4. 关键值(KV)共享与滑动窗口优化
Hymba在模型架构上还进行了进一步的优化,通过跨层KV共享和部分滑动窗口注意力来减少缓存大小和计算复杂度。
4.1 跨层KV共享
传统的Transformer架构中,每一层都会生成独立的KV缓存,而论文中提出的KV跨层共享技术则允许相邻层之间共享KV缓存。这一方法基于实验发现,相邻层的KV缓存具有高度相似性,通过共享可以有效减少冗余存储,并且将节省下来的参数用于模型的其他部分,从而提高整体性能。实验结果表明,这种KV共享技术可以将模型的吞吐率提高约1.15倍,同时维持甚至略微提升常识推理任务的准确性。
4.2 滑动窗口注意力
为了进一步减少模型的内存占用,Hymba在部分层采用了滑动窗口注意力(SWA),替代了全局注意力机制。滑动窗口注意力仅关注一定范围内的局部上下文,因此计算复杂度更低。然而,全局注意力的缺失可能导致模型在回忆能力上的退化。为了解决这一问题,Hymba结合SSM头在全局上下文中的摘要能力,使得在只使用部分全局注意力的情况下,仍然能够保证模型的记忆能力和推理性能。实验结果表明,采用三层全局注意力(第一层、中间层和最后一层)即可实现与全局注意力相近的性能,而缓存大小和吞吐率却分别提升了2.7倍和3.8倍。
5. 性能表现与实验结果
Hymba通过多项基准测试验证了其性能的优势,包括常识推理、回忆密集型任务和多轮对话等任务。具体而言,Hymba-1.5B模型在多个任务上超越了所有参数小于2B的公开模型,包括Llama-3.2-3B。在与其他小型语言模型的对比中,Hymba显示出更高的准确性、更低的缓存需求和更高的推理效率。例如,Hymba在常识推理任务上比Llama-3.2-3B平均准确率高出1.32%,缓存大小减少了11.67倍,推理吞吐率提高了3.49倍。
Hymba模型家族包含了从125M到1.5B参数的不同版本。模型的训练采用了DCLM-Baseline-1.0、SmoLM-Corpus等数据集,并结合了Warmup-Stable-Decay学习率调度器和数据退火技术来确保训练的稳定性。实验还表明,在相同参数量下,Hymba-125M和Hymba-350M版本在多个基准任务中均优于其他同类模型,体现了其架构设计的高效性。
6. 混合头架构的记忆解释
论文对Hymba的混合头架构从记忆的角度进行了深入解释。注意力头的高分辨率回忆能力被类比为人类大脑中的“快照记忆”,能够存储详细的瞬时信息;而SSM头则被类比为“衰退记忆”,能够总结长期上下文,但逐渐遗忘细节。通过这种组合,Hymba可以在不丢失全局信息的前提下,将更多的“快照记忆”用于存储局部细节,从而提高记忆效率和模型性能。
论文通过移除部分层的注意力头或SSM头,分析了各组件的重要性。结果表明,在同一层内,注意力头和SSM头的相对重要性是输入自适应的,并会根据任务的不同而有所变化。特别是,第一层的SSM头在语言建模中至关重要,移除它会导致模型的准确率大幅下降。此外,通常移除注意力头会导致约0.24%的平均准确率下降,而移除SSM头则会导致1.1%的下降,说明SSM头在某些情况下对整体性能的贡献更大。
7. Hymba模型家族与训练细节
Hymba包括了125M、350M和1.5B参数规模的模型,采用了混合数据集进行训练,包括DCLM-Baseline-1.0、SmoLM-Corpus和自有高质量数据集,总共使用了1万亿个训练token。模型的训练采用了“热身-稳定-衰退”(Warmup-Stable-Decay)的学习率调度方式,并通过数据退火技术确保训练的稳定性和高效性。在训练过程中,模型的序列长度逐渐从2k增加到8k,以提升多轮对话和复杂任务的处理能力。
8. 实验结果与模型评估
Hymba在多项基准测试中表现出了卓越的性能,包括语言建模、常识推理、回忆任务、数学推理等。在常识推理和回忆密集型任务中,Hymba显著优于其他模型,尤其是在多轮推理和复杂上下文理解任务中,展示了其混合头架构的优势。此外,Hymba还表现出了较强的可扩展性,能够通过参数高效微调(如DoRA方法)进一步提高在特定任务上的性能。