论文TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models(《TemporalBench: 基于细粒度时序理解的多模态视频模型基准测试》)深入探讨了多模态视频模型在时序理解上的表现,提出了一个名为TemporalBench的新基准。TemporalBench可系统化地测试模型在捕捉细节、理解复杂时序动态上的表现。实验结果表明,当前的多模态模型在这方面仍然远远落后于人类,尤其是在长视频理解和细粒度动作推理上。论文还提出了多重二元准确性(MBA)作为新的评估标准,以消除多项选择问答中的偏差,真正测试模型的时序理解能力。
论文作者为Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao, Yong Jae Lee, Jianwei Yang,来自University of Wisconsin-Madison, Microsoft Research, Ohio State University, University of California(San Diego), Northeastern University, University of California(Santa Cruz), Chinese University of Hong Kong, Illinois Institute of Technology, Georgia Institute of Technology等。
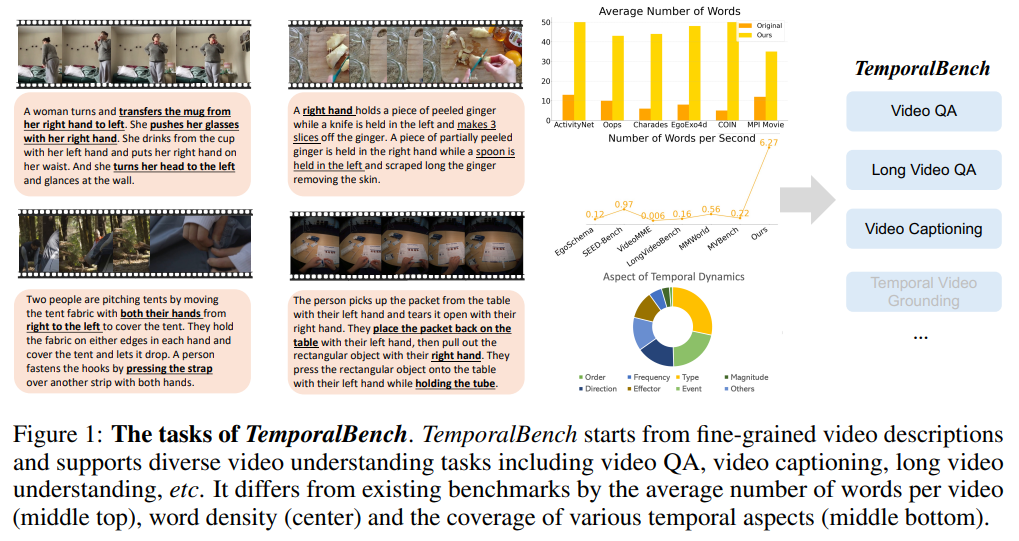
1. 研究背景与动机
在当前的人工智能应用中,视频理解是至关重要的,涵盖了从活动识别、长时序动作预测到自动驾驶和机器人感知等领域。现有的视频理解基准大多缺乏细粒度的时序标注,导致这些基准更像是图像理解的扩展,忽视了视频本质上的时间维度。例如,很多现有的基准只需要模型识别视频中的静态场景,甚至单帧画面即可回答大部分问题,这无法真实反映模型对时间动态的理解能力。通过对现有数据集的分析,作者发现这些基准通常存在“单帧偏差”(Single Frame Bias),即模型可以通过分析单帧静态信息来获得高分,而无需理解视频中的时序变化。这些问题促使研究者们开发了TemporalBench,以系统化地评估多模态模型对时间动态的理解能力。
2. TemporalBench 的构建与特点
TemporalBench是一个新开发的基准,专门用于评估多模态视频模型在细粒度时序理解方面的能力。其核心贡献包括:
- 丰富的时序标注:TemporalBench包含约10,000个问答对,这些问答对是基于约2,000个视频片段的高质量人工注释生成的。这些注释细致描述了视频中的动作频次、运动幅度、事件顺序等细粒度信息。
- 多样化的任务支持:TemporalBench支持多种任务的评估,包括视频问答、视频字幕生成、长视频理解等,且涵盖不同模型,如多模态视频嵌入模型和文本生成模型。这样,研究人员可以利用这些任务全方位地评估模型在时序理解上的表现。
- 细粒度的时间推理能力评估:TemporalBench通过精心设计的问答对,测试模型对视频中连续动作和细微变化的理解能力。例如,要求模型区别“切三次生姜”与“切两次生姜”的差异。这种细节不仅考察模型对单个动作的识别能力,还考察其对动作间复杂时序关系的理解。
3. 多模态视频理解中的挑战
3.1 单帧偏差与语言偏差
作者指出,现有基准存在明显的单帧偏差和语言偏差。单帧偏差指的是模型只需从视频中的某一静态帧提取信息,就能正确回答大部分问题,而不需要考虑视频中的动态变化。例如,在一些视频问答任务中,只需知道视频中的场景元素(例如一个人在做饭)就足以推断答案,而无需了解事件的发生顺序或动作的细节。
语言偏差则体现在,现有的多模态模型往往基于语言模型进行训练,使得它们在遇到视频中的细节问题时会更多依赖语言理解而不是时序推理。这意味着,模型可能只是基于对问题和答案选项的语言模式匹配来做出回答,而不是真正理解视频中的内容。
3.2 细粒度视频理解的复杂性
细粒度视频理解需要模型能够捕捉到视频中的细微变化和复杂的时序依赖关系。例如,TemporalBench中包含大量描述人类动作的片段,这些片段的时序动态难以用单一画面捕捉,模型必须理解动作是如何逐步展开的,如“一个人用右手拿起桌上的物品,再用左手拆开包装”。这种对复杂动态的理解是现有大部分视频理解模型所不具备的,因此TemporalBench旨在填补这一空白。
4. 数据集构建与注释方法
TemporalBench的数据集由人工精心注释,视频片段主要取自于现有的视频基准,包括程序视频(如COIN)、人类活动视频(如ActivityNet、Charades)、自我视角视频(如EgoExo4D)、电影描述(如MPI Movie Description)等。数据集构建过程包括以下几个阶段:
- 视频采集:从多个已有的数据集中采样视频片段,共计约2,000个片段。每个视频片段都经过精心挑选,确保涵盖多种人类活动和不同场景。
- 正向注释生成:由经验丰富的AMT工人对视频进行初步注释,提供细致的描述,包括每个动作的开始和结束时间、动作的具体细节等。之后,论文的作者对这些注释进行校对和完善,确保描述准确、详尽。
- 负向注释生成:为了生成具有挑战性的多项选择题,作者利用GPT-4和其他大型语言模型生成负向描述,这些描述在细节上略有不同,例如将“切三次生姜”改为“切两次生姜”,或将动作的顺序调整,以验证模型是否能真正理解视频中的时序动态。
5. 评估指标与实验结果
5.1 多重二元准确性(Multiple Binary Accuracy, MBA)
论文中提出了多重二元准确性(MBA)来取代传统的多项选择评估方法。在传统的多项选择问答中,模型往往可以通过排除不太可能的选项来猜测正确答案,特别是当所有错误选项只是对正确答案的细微改动时,模型可以检测这些细微变化来找到“最合理”的描述。为此,作者提出将多项选择问题拆解为多个二元选择问题,以更公平地评估模型对视频时序的理解能力。实验结果表明,模型在这种新的评估标准下的表现显著下降,这表明现有模型的时序推理能力仍然有很大提升空间。
5.2 视频模型的表现
实验结果显示,现有的多模态视频模型在TemporalBench上的表现远低于人类水平。例如,GPT-4在短视频的多重二元问答任务中的准确率为38.5%,而人类的平均表现为67.9%。更长的视频理解任务对现有模型提出了更大挑战,模型的表现普遍较差,特别是在理解多个连续的复杂动作时,模型的表现远不及人类。
此外,作者还发现,增加输入视频的帧数并没有显著提升模型的表现,这表明模型在细粒度的动作理解上存在瓶颈。模型在视频长度增加时的表现也不理想,这说明理解长视频中的细微时序变化仍是一个极具挑战性的任务。
5.3 模型对不同细粒度任务的表现
在细粒度任务的评估中,模型在区分动作顺序、频率以及动作方向等方面表现较弱。特别是在涉及动作频率(如识别某个动作执行了几次)的问题上,现有模型往往无法准确区分不同频次的动作,表明模型缺乏对重复事件的记忆和理解能力。
6. TemporalBench 的意义与未来展望
TemporalBench为多模态视频理解提供了一个更具挑战性的评估基准,能够更全面地测试模型在细粒度时序理解上的能力。通过详细的时序注释,TemporalBench弥补了现有视频基准在时序动态评估上的不足,特别是它能有效区分模型是否真正理解了视频中的时序关系,而不仅仅是通过语言模式来猜测答案。
论文的作者希望TemporalBench能推动多模态视频模型在时序推理能力上的进一步发展,包括更好地捕捉视频中的时序依赖关系、改进对长视频的理解能力等。此外,TemporalBench还可以用于其他基础性视频任务的研究,如细粒度时空定位和基于详细提示的文本到视频生成(Text-to-Video Generation)。
TemporalBench on GitHub: https://temporalbench.github.io/