论文Mixtures of In-Context Learners提出了一种名为“上下文学习混合模型(MoICL)”的新方法,以解决现有上下文学习方法在示例选择、内存消耗和推理效率等方面的缺陷。MoICL不仅在性能上优于现有的多种基线方法,而且在计算效率上也有显著的提升,特别是在处理不平衡和噪声数据方面,展现出了强大的鲁棒性。这使得MoICL在需要高效、灵活的上下文学习的各种应用中具有很高的潜力。
论文作者为Giwon Hong, Emile van Krieken, Edoardo Ponti, Nikolay Malkin, Pasquale Minervini,来自University of Edinburgh, United Kingdom。
1. 论文背景与挑战
上下文学习(In-Context Learning, ICL) 是一种无需对模型进行额外微调的学习方式,模型通过提供输入–输出对(示例)来进行任务适应。这种方法在大语言模型(Large Language Models, LLMs)中已经展现出显著的效果(如GPT-3),但它存在以下几个主要挑战:
- 示例选择不佳:现有的ICL方法通常是通过启发式规则来选择示例,缺乏对示例之间关系和其对模型泛化能力的量化分析。这种随机选择示例的方式可能会导致模型性能不稳定,特别是在示例质量差异较大的情况下。
- 计算复杂度高:由于示例被直接拼接到模型输入中,Transformer结构中自注意力机制的计算复杂度会随上下文长度呈二次增长。当示例数量增加时,这种计算代价会变得不可接受,导致内存消耗过高以及推理时间过长。
- 不稳定的泛化性能:ICL方法对所选示例的质量和数量高度敏感。例如,当某些示例来自不同的数据集或者存在标签不平衡的情况时,模型的性能可能会大幅下降。
2. MoICL方法概述
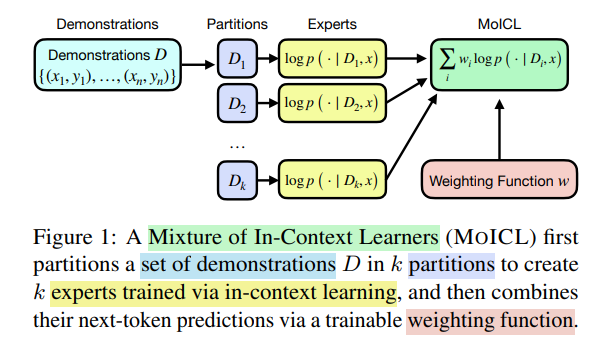
为了应对这些挑战,论文提出了一种新的学习方法,即上下文学习混合模型(Mixtures of In-Context Learners, MoICL)。MoICL的核心思想是将示例集划分为若干子集,每个子集作为一个“专家(expert)”,并通过学习一个加权函数将这些专家的输出组合在一起,从而获得最终的预测。
2.1 方法原理
MoICL包括以下几个主要步骤:
- 示例集划分:将示例集 D 划分为 k个不相交的子集,记作 D1,D2,…,Dk。这些子集分别代表不同的专家,每个专家专注于一部分示例的数据特征。
- 专家训练:每个子集 Di 被用于训练一个专家模型,以生成其对下一个词的概率分布。具体来说,给定一个输入文本 x和子集 Di,模型生成的概率为 p(y∣Di,x)。这些专家独立地进行预测,互不影响。
- 加权组合:通过一个加权函数来合并这些专家的预测。加权函数可以是简单的标量权重或是通过超网络(hyper-network)生成的动态权重。加权后的最终预测为:
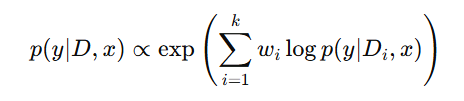
其中 wi是专家 Di的权重,用于表示每个专家对最终输出的贡献。这个加权函数的学习可以通过梯度优化来完成,使得模型能够识别哪些示例子集更为有效。
2.2 权重函数设计
MoICL在加权组合时,采用了两种权重函数设计:
- 标量权重(Scalar Weights):每个专家子集都有一个固定的标量权重,表示其对预测的贡献。这些权重通过训练集进行优化,初始时均匀分布,然后通过梯度优化来调整。
- 超网络权重(Hyper-network Weights):采用一个较小的神经网络来生成每个专家的权重。超网络的输入是所有子集的示例,输出是对应的权重。相比于标量权重,超网络权重具有更强的泛化能力,因为它可以在面对新的示例时动态调整权重。
2.3 稀疏化权重
为了进一步提高计算效率,MoICL还引入了稀疏化权重的概念,即在每次预测时,仅对少数几个子集分配非零权重,从而减少需要计算的专家数量。这种方法有效地降低了计算复杂度和推理时间,同时保持较高的预测精度。
3. 实验与结果分析
为了验证MoICL的有效性,作者进行了多组实验,涵盖了五个分类数据集和一个生成任务的数据集。以下是实验的主要结果和分析:
3.1 分类任务中的表现
在五个分类数据集上(TweetEval、SST2、RTE、FEVER、PAWS),MoICL相比于传统的ICL和其他基线方法展现了显著的性能提升。例如,在TweetEval数据集上的仇恨言论分类任务中,MoICL的准确率相比于传统的ICL提高了约13%。MoICL在面对不平衡标签的情况下,依然能够保持较好的泛化性能,其标量权重配置在多种设置下均优于其他方法。
3.2 面对域外数据和标签不平衡的稳健性
MoICL在面对域外数据(Out-of-Domain, OOD)和标签不平衡的问题时,展现出了显著的稳健性。例如,当部分示例来自不同的数据集时,MoICL通过动态调整这些示例的权重,有效地降低了其对最终预测结果的负面影响。具体实验显示,当50%的示例为域外数据时,MoICL对这些示例分配了负权重,表明这些示例被视为“反专家(anti-experts)”,其对最终预测起到了负向抑制作用。
3.3 噪声示例的过滤
MoICL还能够自动过滤掉低质量或噪声示例。例如,在NQ-Open数据集的生成任务中,MoICL对噪声示例的权重显著低于正常示例,表现出较强的抗噪能力。实验中,当引入多个错误标注的示例后,MoICL的表现几乎不受影响,而传统的ICL方法则出现了显著的性能下降。
4. 计算复杂度与效率
MoICL在计算效率上也具有明显的优势:
- 降低上下文长度:通过将示例集划分为多个子集,MoICL有效地减少了单个专家所需处理的上下文长度。这在Transformer模型中尤为重要,因为自注意力机制的计算复杂度与上下文长度的平方成正比。通过减少每个子集的示例数量,MoICL显著降低了计算复杂度和内存消耗。
- 稀疏化策略:通过稀疏化专家权重,仅对少数子集分配非零权重,MoICL进一步降低了推理的计算开销。实验显示,与传统的ICL方法相比,MoICL在达到相同预测精度的前提下,推理时间减少了约30%。
5. 主要贡献与未来研究方向
论文总结了MoICL在上下文学习中的主要贡献:
- 提出MOICL方法:通过动态学习不同示例子集的权重,MoICL显著提高了ICL的学习效果,并减少了对上下文长度的依赖。
- 增强对噪声和不平衡数据的处理能力:MoICL能够自动识别并抑制低质量示例的影响,从而提高模型的鲁棒性和泛化能力。
- 提高计算效率:通过稀疏化权重和子集划分,MoICL在减少内存和计算需求的同时,依然保持了较高的预测性能。
未来研究方向:
- 黑箱模型的适应性:虽然MoICL不需要直接访问模型的参数,但它需要访问模型的输出概率(logits),这使得其难以应用于像GPT-4这样的黑箱模型。未来可以考虑采用黑箱优化方法来解决这个问题。
- 示例子集的全局扩展:目前MoICL只对选定的示例子集进行权重学习,未来的研究可以探索如何将这种权重学习扩展到整个训练集,以便进一步提升其泛化能力