论文Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent介绍了腾讯发布的一款开源巨型专家混合(MoE)模型,即混元大模型(Hunyuan-Large)。该模型拥有3890亿总参数量和520亿激活参数。
论文作者为来自Tencent Hunyuan Team的多名成员。
一、背景与模型概述
Hunyuan-Large是由腾讯团队推出的一款基于专家混合(MoE,Mixture of Experts)技术的开源巨型语言模型,具有3890亿总参数量和520亿激活参数,是目前公开的最大规模的MoE模型之一,能够处理长达256K的token输入。其设计目的是通过更有效的专家模型结构,突破以往语言模型在理解、推理和生成任务上的性能瓶颈,并与当前其他开源的类似规模的LLM(大语言模型)进行竞争。Hunyuan-Large特别强调在高效性、训练开销和推理成本方面的优化,同时保持了卓越的模型性能。
1.1 大模型的背景及意义
近年来,随着语言模型的发展,人工智能(AI)领域取得了显著进展。尤其是自从ChatGPT的成功推出之后,基于Transformer架构的大语言模型在自然语言处理(NLP)、计算机视觉(CV)、语音处理、AI科学计算等众多领域得到了广泛应用。这些模型通过预训练获取基础能力,再通过后续微调适应特定任务需求。然而,随着模型规模的不断增大,传统的密集(dense)架构难以应对资源消耗和实际应用需求。为此,MoE成为一种新兴的方法,通过激活部分专家模型,降低计算和内存开销,同时提高模型的适应性和性能。
腾讯的AI对话系统“元宝”采用了MoE架构,并在多个应用场景中得到了成功部署。此次推出的Hunyuan-Large作为开源版本,旨在向学术界和产业界提供一个强大的工具,以推动MoE相关技术的应用和普及。
二、预训练阶段详细介绍
Hunyuan-Large的预训练过程分为几个关键步骤,包括数据和分词器的设计、模型结构的优化以及预训练配方的探索。
2.1 数据和分词器
2.1.1 数据处理与合成
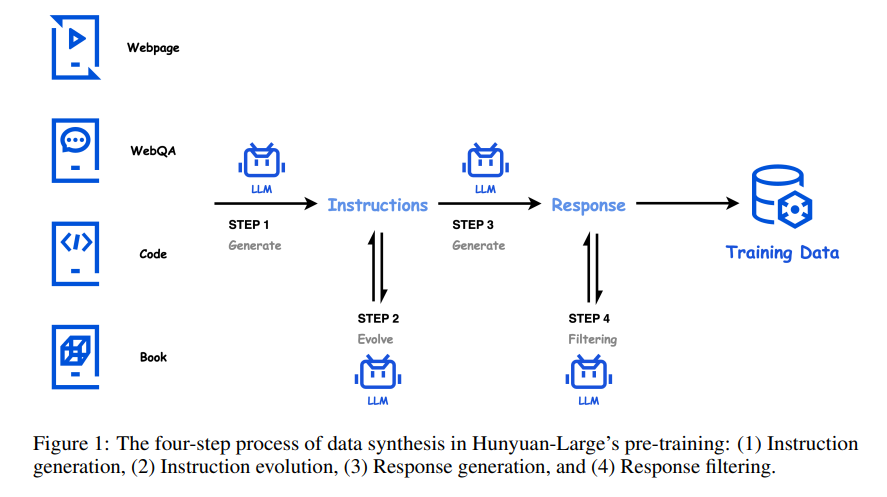
数据是Hunyuan-Large模型性能的基石,腾讯团队为其准备了高质量的7万亿tokens数据,其中包括1.5万亿的合成数据。数据主要由中文和英文组成,以满足实际应用的多语言需求。数据合成的过程采用了四步生成方法:
- 指令生成:通过知识丰富的种子数据(如网页数据、代码库、书籍等)生成涵盖不同领域的多样化指令。这些指令形式多样,风格复杂,以确保模型能有效学习多种任务类型。
- 指令演变:对初始生成的指令进行细化和演变,增加指令的清晰度、信息量以及难度,通过“自我指令增强”方法扩展指令的低资源领域,以帮助模型突破原有的能力边界。
- 响应生成:利用多个领域的专家级子模型生成针对演变后指令的高质量响应,确保指令的复杂性与实际应用的高匹配度。
- 响应过滤:使用评论模型和自一致性检查机制过滤生成的指令响应对,确保其高质量和一致性,剔除低质量和不准确的合成数据。
通过这一系列的数据处理和合成,模型具备了广泛而深刻的任务理解与推理能力,并显著提高了对未见数据的泛化能力。
2.1.2 分词器
Hunyuan-Large采用了128K词汇大小的分词器,这个分词器由10万来自开源tiktoken分词器的token,以及额外的2.8万针对中文特定优化的token组成。与LLama3.1分词器相比,Hunyuan-Large的分词器压缩率有显著提升,从2.78字符/词提升到了3.13字符/词,这样既能保证模型训练和推理的效率,又能在大词汇表中保证足够的词嵌入学习能力。
2.2 模型结构
2.2.1 模型架构概述
Hunyuan-Large的整体架构基于经典的MoE结构。模型在每一层中使用多个专家替换原来的FFN层,通过激活少量专家来实现计算的高效性。模型共由64层组成,具有80个注意力头(每个token在推理时激活1个共享专家和1个特定专家)。在模型架构中还引入了旋转位置编码(RoPE)和SwiGLU激活函数,以提高模型的学习能力和效率。
2.2.2 KV缓存压缩技术
在推理过程中,KV(键值)缓存占用的内存往往是模型性能的瓶颈。Hunyuan-Large通过组合查询注意力(GQA)和跨层注意力(CLA)来压缩KV缓存,从而在保证模型性能的同时大幅度降低内存开销。具体来说,GQA通过对KV头进行分组,而CLA则通过在相邻层共享KV缓存,这种组合策略使得KV缓存占用相比传统MHA(多头注意力)减少了约95%。
2.2.3 专家路由策略
Hunyuan-Large采用了混合专家路由策略,即每个token会激活一个共享专家和一个特定专家。通过再循环路由机制,对被过载专家丢弃的token进行随机重新分配,确保更多的信息得以利用,提高了训练的效率和稳定性。
2.2.4 专家特定学习率缩放
Hunyuan-Large在使用AdamW优化器的基础上,根据不同专家的负载情况来动态调整学习率。由于共享专家和特定专家在每次训练中的token数量不平衡,因此为每个专家分配特定的学习率,以保证模型的训练效率和稳定性。具体来说,特定专家的学习率是共享专家的0.31倍,从而确保不同专家能够根据各自的情况进行最佳的训练。
2.3 预训练配方
2.3.1 MoE扩展规律探索
Hunyuan-Large在预训练阶段通过对MoE扩展规律的探索,确定了最优的激活参数和训练数据量。通过一系列实验,模型最终选择了520亿作为激活参数数量,并确定了大约7万亿的训练tokens,以保证在有限计算预算内达到最佳的性能。
2.3.2 学习率调度
模型的学习率调度包括初期的学习率热身阶段、中期的缓慢衰减阶段以及最终的退火阶段。这样的学习率安排确保模型在探索解空间的同时,逐步收敛到更优的解,从而避免过早收敛到次优解。
2.3.3 长上下文预训练
为了让模型具备处理长文本的能力,Hunyuan-Large在预训练过程中逐步增加序列长度,从32K到256K。模型采用了旋转位置编码(RoPE),并在256K阶段将RoPE的基频率扩大到10亿,以提高对长序列的适应能力。
三、后续训练阶段的详细介绍
3.1 监督微调(SFT)
监督微调旨在进一步提升Hunyuan-Large的特定任务能力,包括数学、代码、逻辑推理等方面。通过指令提取、指令泛化、指令平衡和数据质量控制等数据处理方法,模型得以有效适应多样化的应用场景。
在指令泛化方面,模型通过设计并训练了一套泛化系统,逐步提升指令的复杂性和难度,并通过构建指令分类模型,平衡各种类型指令在数据集中的分布,以提升模型的广泛适用性和泛化能力。
3.2 人类反馈强化学习(RLHF)
为了使模型的行为更加符合人类的偏好,Hunyuan-Large使用DPO方法,通过结合离线和在线的训练策略来实现。训练中,模型会生成多个响应,并通过奖励模型选择最优的响应,最终通过对优选响应的监督损失项来稳定DPO的训练过程,从而减轻奖励黑客和对齐税带来的影响。
四、模型评估
Hunyuan-Large在各种任务中的表现优异,特别是在数学推理、代码生成、长文本理解等多个领域,显著超越了包括LLama3.1-405B等在内的当前最先进的大模型。在MMLU和数学数据集上的性能尤为突出,其中MMLU的准确率比LLama3.1-405B高出2.6%。在数学推理能力评估中,Hunyuan-Large也表现出了明显的优势,尤其在MATH数据集上,达到了77.4%的表现,超越了所有的对手。
五、长上下文处理能力评估
Hunyuan-Large在长上下文处理上也进行了详细的评估,采用了RULER和LV-Eval两个基准测试,此外还通过腾讯内部开发的PenguinScrolls数据集进一步评估其在实际应用中的长文本处理能力。RULER测试表明,Hunyuan-Large在不同上下文长度下保持了稳定的高性能,尤其在64K到128K的token范围内,性能明显优于基准模型。PenguinScrolls数据集则进一步验证了模型在多种任务和多语言长文本处理中的能力,特别是在信息提取、定性分析和数值推理任务上。
六、结论与未来方向
Hunyuan-Large代表了MoE模型技术的一个里程碑,其卓越的性能得益于高质量的合成数据、优化的模型结构以及精心设计的训练配方。通过对MoE模型的扩展规律的探索,腾讯团队为该模型提供了最佳的参数配置,同时结合监督微调和人类反馈强化学习进一步提升了模型的任务能力。未来,腾讯团队计划继续优化Hunyuan-Large,并推动MoE模型在更多领域中的应用和实践,以期在通用人工智能(AGI)的发展中发挥更积极的作用。
Code on GitHub: https://github.com/Tencent/Tencent-Hunyuan-Large
Models on Huggingface: https://huggingface.co/tencent/Tencent-Hunyuan-Large