论文Ultra-Sparse Memory Network提出了一种名为UltraMem的新型神经网络架构,解决传统Transformer模型在推理过程中因内存访问高开销导致的性能瓶颈问题。UltraMem通过引入大规模的超稀疏内存层(Ultra-Sparse Memory Layer),显著提高了计算效率,减少了推理延迟,同时保持或提高了模型的性能。
论文作者为Zihao Huang, Qiyang Min, Hongzhi Huang, Defa Zhu, Yutao Zeng, Ran Guo, Xun Zhou,均来自Bytedance(字节跳动)。
一、引言
近年来,随着自然语言处理(NLP)领域大规模语言模型(LLM)的快速发展,模型的计算需求也呈指数增长。大规模的Transformer模型(如GPT-3等)虽然在各种任务上表现出色,但它们的推理过程往往受到计算资源和内存带宽的限制,导致推理速度显著下降。为了提高计算效率,研究者们提出了一些方法,例如Mixture of Experts(MoE)和Product Key Memory(PKM)。MoE通过选择性激活不同的子模型(即“专家”),从而增加模型的参数数量而不显著增加计算开销。然而,在推理过程中,MoE仍然存在较高的内存访问开销,因为即使激活了部分专家,仍然需要大量的内存访问以完成计算。
PKM方法则通过引入外部内存模块,减少内存访问的频率,从而提高了计算效率,但其性能仍不如MoE。为了解决MoE和PKM的不足,UltraMem提出了一种新的架构,通过引入大规模、超稀疏的内存层,在保证计算效率的同时,减少内存访问延迟。与MoE相比,UltraMem在推理速度上有显著提高,并且能够在相同计算资源下达到更好的模型性能。
二、相关工作
论文首先回顾了与UltraMem相关的研究工作,主要集中在Mixture of Experts(MoE)和Product Key Memory(PKM)两种方法。MoE(Shazeer et al., 2017)最早提出,通过在每个推理步骤中激活一部分“专家”模型,来增加模型的参数数量,同时控制计算开销。尽管MoE可以在训练时有效利用大量参数,但由于推理过程中需要访问大量内存,导致其推理速度较慢。为了解决这个问题,Fedus et al.(2022)进一步提出了多专家选择机制,通过选择少量专家参与计算,降低了内存访问开销。然而,即使在这种情况下,MoE仍然面临着推理延迟过高的问题,特别是在需要处理大批量数据时。
相比之下,PKM(Lample et al., 2019)采用了产品键(Product Keys)机制,将大规模的内存层分割为多个小块,通过索引来访问特定的值。这种方法能够有效减少内存访问的频率,从而提高了推理效率。然而,PKM的性能并未达到MoE的水平,尤其是在大规模训练的场景下,PKM仍然面临着诸多挑战。
UltraMem的提出正是为了克服MoE和PKM的局限性,采用了改进的查询-键检索机制,以及稀疏激活和分布式内存访问策略,使得模型在保证性能的同时,能显著减少内存访问开销。
三、UltraMem架构
UltraMem架构在PKM的基础上进行了一系列改进。首先,UltraMem引入了Tucker分解(Tucker Decomposition)来优化查询-键检索过程。Tucker分解是一种矩阵分解方法,通过将大规模的查询-键矩阵分解为多个小矩阵,减少了计算复杂度。这使得UltraMem能够在大规模内存访问的情况下,仍然保持较低的计算开销。
其次,UltraMem采用了隐式值扩展(Implicit Value Expansion,IVE)技术,通过将内存表扩展为多个虚拟内存块,进一步减少了内存访问的需求。具体来说,IVE将每个内存值的多个虚拟扩展映射到不同的内存地址,从而在推理时可以选择性地访问这些扩展值,而无需直接访问原始内存表。这样,UltraMem能够在保持较小内存访问开销的同时,处理更大的模型和数据。
此外,UltraMem还采用了多核评分(Multi-Core Scoring,MCS)技术,在内存访问时为每个内存值分配多个评分,这有助于提高检索准确性,并进一步减少内存访问时的延迟。通过这些技术的组合,UltraMem能够在推理过程中显著提高速度,并减少内存访问开销。
四、定量分析
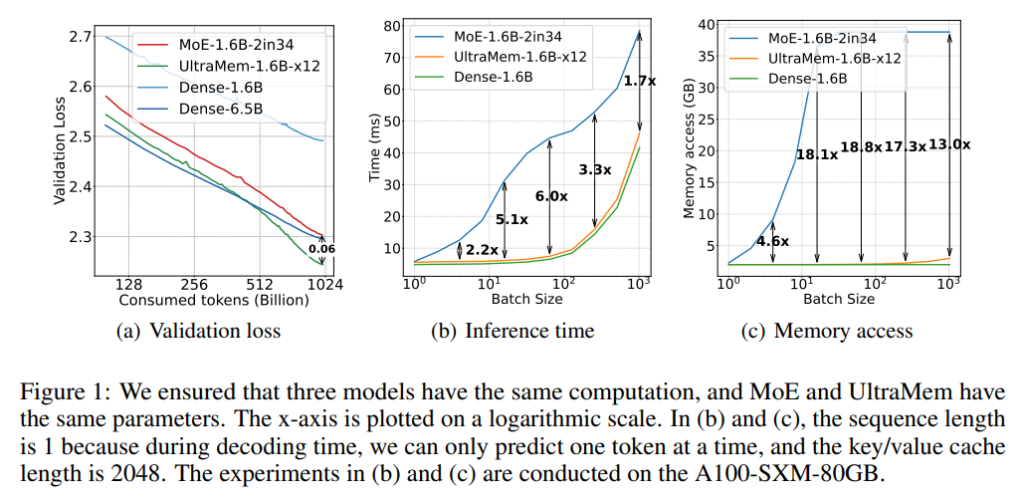
为何选择UltraMem而非MoE 在论文中,作者对比了UltraMem和MoE的性能,特别是在推理时的内存访问开销和推理速度。假设Transformer模型的隐藏层维度为D,MoE使用每个token选择两个专家,并假设每个专家的内部维度为2D。在这种情况下,MoE的内存访问量为min(2B, Nmoe) × 2D^2,其中B是批次大小,Nmoe是专家数量。而UltraMem则通过选择前m个值来激活内存,内存访问量为min(Bm, N) × D/2,其中m是激活的值的数量。
随着批次大小的增加,MoE的内存访问量迅速增长,而UltraMem的内存访问量增长较慢,直到达到上限。实验结果表明,在常见的推理批次大小下,UltraMem比MoE快6倍,且在其他批次大小下也表现出色。此外,在较小批次大小的情况下,MoE的推理速度显著低于UltraMem,进一步证明了UltraMem在实际推理中的优势。
五、实验
在实验部分,作者展示了UltraMem在不同规模的模型中的表现,结果表明,UltraMem能够在相同的计算资源下,超越MoE和PKM,尤其在处理大规模模型时表现尤为突出。通过对比不同模型的推理时间和内存访问开销,作者验证了UltraMem的优越性。
作者还进行了大量的评估,使用了10个不同的基准数据集,包括MMLU、TriviaQA、GPQA等,评估了模型的知识能力、推理能力、阅读理解能力和整体表现。实验结果表明,UltraMem在各个任务中的表现均优于MoE和PKM,尤其是在计算和内存资源有限的情况下,UltraMem能够提供更高的推理速度和更优的模型性能。
六、结论
论文最后总结了UltraMem的优势。UltraMem通过减少内存访问开销和提高推理速度,显著提升了大规模语言模型的推理性能。与MoE相比,UltraMem不仅具有相同的计算资源消耗,还在推理速度和性能上具有明显的优势。通过对UltraMem架构的深入分析,论文展示了一种新的高效大规模语言模型架构,它为未来大规模模型的开发提供了新的思路和方向。