论文Token Statistics Transformer: Linear-Time Attention via Variational Rate Reduction提出的Token Statistics Transformer(ToST)通过引入TSSA(Token Statistics Self-Attention)注意力模块,显著降低了计算复杂度和内存需求,同时保持了与传统Transformer架构相当的性能。
论文作者为Ziyang Wu, Tianjiao Ding, Yifu Lu, Druv Pai, Jingyuan Zhang, Weida Wang, Yaodong Yu, Yi Ma, Benjamin D. Haeffele,来自UC Berkeley, UPenn, UMich, THU, HKU, JHU等机构。
一、研究动机与背景
Transformer架构自2017年提出以来,已经在自然语言处理、计算机视觉等多个领域取得了极大的成功。其核心创新之一便是自注意力机制(Self-Attention),这使得Transformer能够高效地处理输入序列中的长距离依赖。然而,尽管自注意力机制在多个任务中表现出色,但其计算复杂度是一个显著的瓶颈。传统的自注意力机制需要计算所有标记对之间的相似度,因此其计算复杂度是平方级别的。随着输入标记数量的增加,计算资源需求也随之大幅度提升,尤其是在处理长序列任务时,这一问题尤为突出。
该论文提出了一种新的注意力机制——Token Statistics Self-Attention (TSSA),通过引入变分最大编码率降维(MCR2)目标,设计了一种线性时间复杂度的注意力操作符。通过这种方法,Transformer架构的计算复杂度可以从传统的二次方复杂度降低到线性复杂度,从而大大提高了计算效率,同时保持了与传统Transformer架构相当的性能。
二、方法论与新型注意力机制
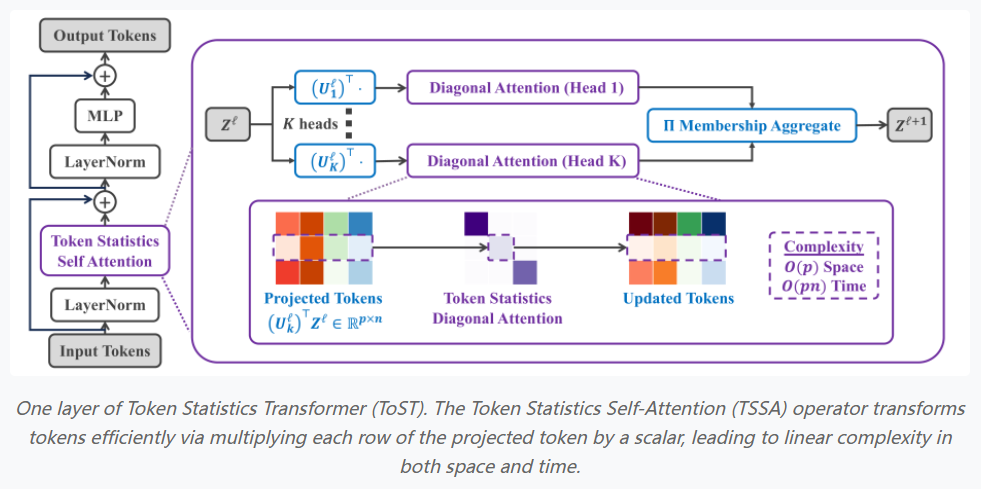
- 最大编码率降维(MCR2)目标与变分形式在Transformer的自注意力机制中,核心操作是计算输入标记之间的相似度,并基于这些相似度加权平均生成输出标记。这一操作需要计算每一对标记的相似度,导致计算复杂度为O(n²),其中n是输入标记的数量。为了减少计算复杂度,论文提出了一种新型的优化目标——最大编码率降维(MCR2)目标。该目标通过压缩标记特征同时扩展整体特征的空间,从而有效地减少计算复杂度。MCR2目标中的压缩项旨在将同一组标记的特征压缩到一个低维空间中,而扩展项则试图将所有标记的特征尽可能地扩展。具体来说,给定一个标记矩阵X,论文假设这些标记属于K个组(例如,表示不同的标记模式),MCR2目标旨在找到每个组内特征的压缩表示,同时保持整体标记特征的扩展性。通过最大化MCR2目标,模型可以自动学习到数据的低维结构。论文进一步推导了MCR2目标的变分形式,并使用“白盒”架构设计方法将其转化为一种新的注意力机制。这一注意力机制不再依赖于标记对之间的相似度计算,而是基于标记特征的统计量(如二阶矩)来进行计算,从而大大提高了计算效率。
- 白盒网络架构设计“白盒”架构设计是一种通过逐步优化目标函数来构建网络的方式。在这种设计方法中,网络的每一层都可以看作是执行一个优化步骤,该步骤旨在最小化或最大化某个目标函数。通过这种方式,网络架构的设计过程可以与优化算法(如梯度下降)相联系,使得每一层的操作都可以通过优化步骤来解释。论文在白盒架构设计的基础上,提出了一种新的注意力操作符,称为Token Statistics Self-Attention (TSSA)。与传统的自注意力机制不同,TSSA不再计算每对标记的相似度,而是通过标记特征的二阶矩统计量来进行低秩投影。这一方法通过对输入标记特征进行数据依赖的低秩投影,只保留重要信息,抑制不重要的信息,从而有效地减少了计算负担。论文中还指出,TSSA的计算复杂度为O(n),即与标记的数量呈线性关系,这使得TSSA成为一个非常高效的注意力操作符。
三、实验结果与分析
- 视觉任务为了验证所提出的Token Statistics Transformer (TOST)架构,论文对其在视觉任务中的表现进行了评估。实验中使用了多个标准数据集,如ImageNet、CIFAR10、Oxford Flowers等,并将TOST与传统的Vision Transformer(ViT)架构进行了比较。实验结果表明,TOST在这些数据集上的分类准确率与ViT相当,但其计算和内存复杂度显著低于ViT。特别地,在处理大规模图像数据集时,TOST的效率优势更加明显。通过替换标准的自注意力模块,TOST能够在保持相似性能的同时,显著减少计算和内存消耗。
- 长序列建模论文还在长序列建模任务上对TOST进行了评估,使用了Long-Range Arena (LRA)基准。LRA基准旨在测试模型在处理长序列时的能力,涵盖了多个长文档理解任务,如文本检索、图像路径查找等。实验结果表明,TOST在这些任务中表现出色,尤其在长序列建模方面,其性能超过了大多数现有的Transformer变种。与传统Transformer模型相比,TOST在长序列任务中展现了更高的效率和更低的计算需求。
- 语言建模任务论文还评估了TOST在语言建模任务中的表现。通过将TOST应用于标准的语言建模数据集(如OpenWebText、WikiText等),实验结果表明,TOST能够在不牺牲性能的前提下,显著提高计算效率。尽管自注意力机制通常被认为是语言建模成功的关键,TOST通过替换自注意力操作符,仍能保持较好的性能,并在计算速度和内存使用方面具有明显优势。
四、总结与展望
本文提出了一个创新的Token Statistics Transformer架构,通过引入Token Statistics Self-Attention (TSSA)模块,解决了标准Transformer架构中自注意力计算复杂度过高的问题。TSSA通过利用数据依赖的低秩投影,显著降低了计算复杂度,且不依赖于标记对之间的相似度计算。实验结果表明,TOST在多个视觉、语言和长序列任务中都表现出色,并且在计算效率和内存使用方面远远优于传统的Transformer模型。
未来的工作可以进一步优化TSSA模块的计算效率,探索其在更多任务中的应用,并结合更高效的训练方法,进一步提升其在实际应用中的表现。TOSS架构的提出为Transformer模型的高效设计提供了新的思路,并且有潜力在多个实际任务中得到广泛应用。
Token Statistics Transformer(ToST): https://robinwu218.github.io/ToST/
ToST on GitHub: https://github.com/RobinWu218/ToST