论文Lossless Compression of Vector IDs for Approximate Nearest Neighbor Search提出了一种基于非对称数字系统(ANS)和波列树的无损压缩方法,专门针对近似最近邻搜索中的向量ID和图结构进行优化。通过无损压缩,作者在保证检索精度和搜索效率的前提下,显著减少了存储和传输开销。实验结果验证了所提出的方法能够在多个数据集上取得良好的压缩效果,并对未来在该领域的研究提出了若干建议。
论文作者为Daniel Severo, Giuseppe Ottaviano, Matthew Muckley, Karen Ullrich, Matthijs Douze,均来自Meta。
一、引言
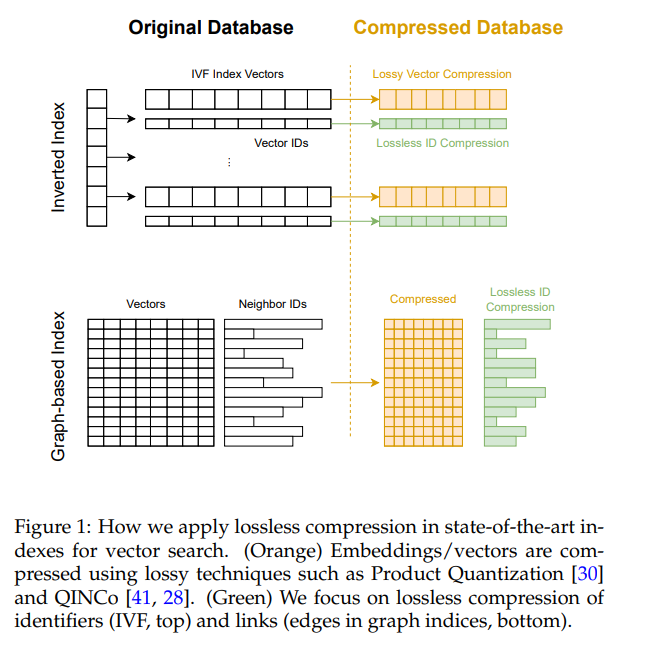
近似最近邻搜索(Approximate Nearest Neighbor Search,简称ANNS)在大规模数据检索中扮演着至关重要的角色。尤其是在图像、视频等多媒体检索领域,随着数据量的不断增长,精确的最近邻搜索变得过于缓慢。为了应对这一问题,许多研究者提出了近似搜索的方法,这些方法通过牺牲一些准确性来换取更快的检索速度。为了提高搜索效率,通常会对数据库中的向量数据进行压缩,以减少存储空间和传输带宽。然而,大部分压缩方法只关注向量本身的压缩,而忽略了向量ID(即用于指示向量在数据库中的位置的标识符)和图结构中的边数据。这篇论文的主要贡献之一,就是提出了一种无损压缩方案,专门针对这些ID和图边数据进行压缩,进而减小数据库的存储和传输成本。
二、相关工作
在向量压缩领域,许多研究集中于量化(quantization)技术,用于将连续的向量压缩成离散的整数或比特序列。这类技术有助于减少向量比较所需的计算量,并在一定程度上提高搜索效率。经典的量化方法包括矢量量化(Vector Quantization)、产品量化(Product Quantization,PQ)等。然而,这些方法通常并不涉及如何对已生成的量化编码进行进一步的无损压缩。熵编码方法,如哈夫曼编码、算术编码等,理论上可以将量化后的数据进行压缩,减少冗余,从而进一步优化存储。
此外,向量检索索引结构中也有大量ID数据需要存储,尤其是倒排文件(Inverted File,IVF)索引和图索引结构。倒排文件通过将向量集合分为若干簇来加速搜索,图索引则通过构建向量之间的关系图来提升搜索效率。在这两种索引结构中,向量ID的存储量可能会占据大部分的空间,而这些ID通常是以32位或64位的整数存储。因此,如何压缩这些ID数据以减少存储和传输开销,是提高向量搜索效率的一个关键问题。
三、背景
本节首先介绍了无损压缩的基本概念。无损压缩的目标是在不丢失任何信息的情况下,尽可能减少数据所需的存储空间。常见的无损压缩方法包括哈夫曼编码、算术编码和非对称数字系统(ANS)。ANS是一种基于概率模型的压缩方法,能够接近于信息熵的理论下限,因此在很多实际应用中取得了较好的压缩效果。ANS的基本原理是通过定义一个概率模型来编码符号,并且通过不断的符号编码和解码来调整压缩比。
接下来,论文介绍了如何应用ANS以及其他相关方法,如位回编码(Bits-back coding)和波列树编码(Wavelet Tree),来对无序的整数集合、图结构和多重集合进行压缩。这些方法利用了数据中存在的某些结构性特征(如集合的无序性或图中节点的连接性)来进行有效压缩。例如,在多重集合中,由于元素的顺序不重要,可以利用这一无序性来减少存储开销,从而达到压缩的目的。
四、数据库索引压缩
数据库索引是提高近似最近邻搜索效率的核心数据结构。常见的索引结构包括倒排文件(IVF)和图索引。IVF通过将数据集划分为若干簇,每个簇内的向量被赋予唯一的ID,以便在搜索时根据查询向量与簇中心的距离快速确定候选簇。图索引则通过构建节点之间的边来表示向量间的相似性,并在搜索时通过遍历图的结构来找到最近邻。无论是IVF还是图索引,都需要存储大量的ID信息,这些ID通常占用了大部分存储空间。
论文提出了一种无损压缩方法,通过利用IVF和图索引中ID数据的无序性来减少存储需求。具体来说,在IVF索引中,簇内的向量ID可以通过重新排序来进行压缩,因为簇内ID的顺序对搜索结果没有影响。同样,对于图索引中的邻接关系,边的顺序也不会影响搜索结果,因此这些数据也可以通过重新排序来进行压缩。通过这种方式,论文中提出的压缩方法能够显著减少存储空间,而不影响搜索精度和效率。
此外,论文还介绍了如何使用波列树和随机边编码(Random Edge Coding,REC)等技术来进一步优化图索引的压缩。波列树是一种高效的序列压缩结构,可以通过递归划分符号集并存储每个符号的出现情况,从而对图中的边进行压缩。REC则通过构建图的压缩概率模型来对图进行编码,并利用该模型对图的邻接关系进行高效压缩。
五、实验
本节通过多个实验评估了所提出的压缩方法的性能。实验涵盖了不同的压缩方法和索引结构,包括基于IVF的压缩、基于图的压缩以及基于波列树和随机边编码的图索引压缩。实验结果表明,使用ROC编码的IVF索引能够将ID的存储空间压缩到原始空间的14.7%,即压缩比为7。而在图索引中,最佳的压缩比为50%,虽然某些数据集的压缩效果没有达到预期,但整体压缩效果依然显著。
在随机访问设置下,作者展示了如何通过压缩单个簇的ID来减少存储需求。实验结果显示,IVF索引在压缩后的查询速度几乎没有受到影响。对于图索引,压缩后的查询时间略有增加,但仍然能够保持较高的搜索效率。
六、讨论与未来工作
尽管本研究提出的压缩方法在多个数据集上取得了显著效果,但在实际应用中仍存在一些挑战。例如,在某些情况下,图索引中的邻接关系较为简单,压缩效果不如预期。此外,不同数据集的特征差异可能会影响压缩算法的效果。因此,未来的研究可以集中在如何通过自适应的压缩策略来应对这些差异,从而提升方法的通用性。
另一个潜在的研究方向是进一步优化量化向量的压缩。虽然本研究已展示了一些通过条件编码进一步压缩量化代码的可能性,但对于一些数据集(如FB-ssnpp1M和Deep1M),进一步压缩并未显著提升效果。因此,如何更好地利用量化代码中的冗余信息,仍然是一个值得深入探讨的问题。
论文研究相关代码:https://github.com/facebookresearch/vector_db_id_compression