近年来,机器人技术和具身人工智能(Embodied AI)领域取得了显著进展,特别是在模仿学习(Imitation Learning)和强化学习(Reinforcement Learning)方面。这些进展使得智能体可以在不同的任务中学习并执行复杂的行为。然而,尽管已经取得了这些进展,智能体在任务泛化方面依然面临着巨大的挑战。现有的强化学习方法通常依赖于在训练阶段通过反馈调整模型,使其能应对特定的任务。然而,这种方法的局限性在于,智能体仅能处理在训练阶段出现过的场景和任务。因此,如何让智能体能够在未见过的新任务中进行有效推理,仍然是一个亟待解决的问题。
为了解决这一问题,世界模型(World Models)提供了一个潜在的解决方案。世界模型通过学习环境的动态特征,使得智能体能够在遇到新环境时,通过内在模型推测未来的状态并采取合理的行动。论文DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning提出的DINO-WM(基于预训练视觉特征的世界模型)方法,采用了一种新的方式,利用预训练的视觉特征来进行任务无关的推理,并通过这种方式实现了零样本(Zeor-shot)规划。DINO-WM可以在没有专家示范、奖励建模或预训练逆模型的情况下,仅凭观察图像和行为轨迹进行规划,从而解决了一些复杂的控制任务。
论文作者为Gaoyue Zhou, Hengkai Pan, Yann LeCun, Lerrel Pinto,来自New York University和Meta。杨立昆(Yann LeGun)教授也是论文作者之一。
一、论文相关工作
构建世界模型的方法已有很多研究,尤其是在控制和规划领域。传统的世界模型方法依赖于对环境状态进行建模,并使用这些模型进行任务优化。这些方法通常依赖于在线训练,即智能体需要在环境中进行大量交互,从中学习如何执行任务。然而,在线世界模型的主要问题在于它们只能在训练期间优化某些特定任务,无法处理环境和任务的变化。为了克服这一问题,离线世界模型被提出,这类模型依赖于已经收集的离线数据进行训练,因此能够更好地处理环境的变化。
许多现有方法在学习世界模型时都依赖于原始图像数据或状态空间表示。虽然这些方法可以生成高质量的世界模型,但它们通常计算成本高昂,尤其是在面对需要重建图像的任务时。此外,许多模型会将奖励预测作为辅助任务,这使得它们依赖于特定任务的奖励信号,限制了其通用性。
DINO-WM则提出了一种不同的方法,它通过使用预训练的DINOv2模型的视觉补丁特征来建模环境的动态,而不是直接使用原始图像。这些预训练的补丁特征捕捉了空间和语义信息,从而使得世界模型能够在没有任务特定奖励或演示的情况下,进行任务无关的推理。
二、DINO-WM的核心方法
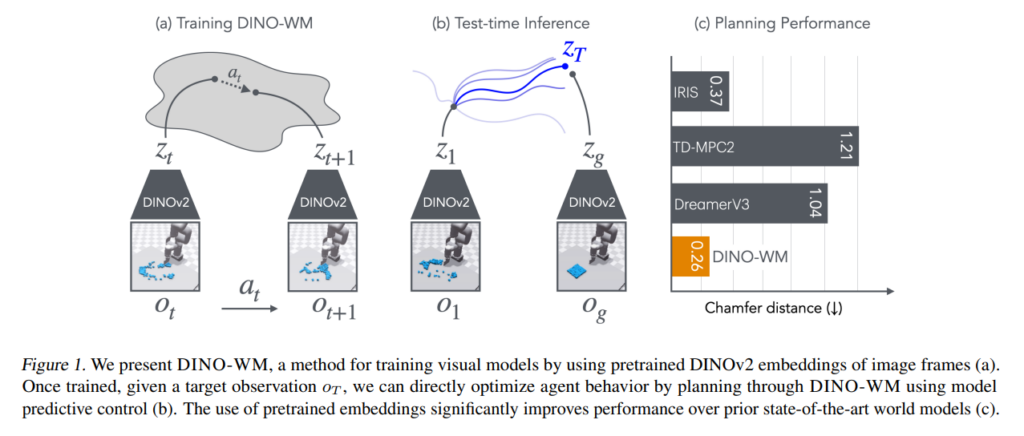
DINO-WM的核心思想是通过利用预训练的视觉嵌入来建立世界模型,并通过模型预测未来的潜在状态来进行规划。具体来说,DINO-WM由三个主要部分组成:
- 观察模型
观察模型的作用是将原始的图像观测(如RGB图像)转化为潜在空间的表示。为了避免从头开始训练一个观察模型,DINO-WM使用了预训练的DINOv2模型,利用其强大的空间理解能力,将图像编码为补丁嵌入。这些嵌入包含了丰富的空间信息,使得智能体能够在没有任务特定数据的情况下,理解并执行视觉任务。这种方式避免了任务特定数据的依赖,同时保留了空间结构和语义信息,适合用于导航、物体检测和操作等任务。 - 转移模型
转移模型用于根据历史观测和行动,预测未来的潜在状态。在DINO-WM中,转移模型基于Vision Transformer(ViT)架构进行设计。该架构非常适合处理补丁特征,因为它可以通过自注意力机制有效捕捉潜在状态之间的时序依赖性。转移模型通过处理过去一段时间的潜在状态和行动,预测下一个时间步的潜在状态。为了更好地捕捉时序信息,DINO-WM采用了因果注意力机制,即每个潜在状态仅依赖于过去的状态和动作,而不考虑未来的信息。这种设计可以有效防止在训练过程中“作弊”——即利用未来的信息来做出预测。 - 视觉规划
在测试阶段,DINO-WM通过模型预测控制(MPC)方法进行视觉规划。给定初始状态和目标状态(以图像形式表示),DINO-WM的目标是找到一个动作序列,使得智能体的行为最终能够达到目标状态。DINO-WM采用了交叉熵法(CEM)来优化行动序列。通过这种方法,DINO-WM能够在没有额外的任务特定数据的情况下,仅凭观察和目标预测,规划出合适的行动序列。此外,DINO-WM还展示了其在没有额外信息的情况下,通过预测潜在状态来进行任务规划的能力。
三、实验与结果
DINO-WM的实验部分评估了其在不同环境中的表现,包括迷宫导航、机器人臂控制、物体操控等任务。实验结果表明,DINO-WM在这些任务中都表现出色,尤其在面对需要精确控制的任务时,相较于现有的世界模型,DINO-WM能够提供更为准确的预测和规划。
- 零样本(Zero-shot)规划
在多个任务环境中,DINO-WM表现出色,成功完成了基于给定初始状态和目标状态的任务规划。在这些环境中,DINO-WM的任务成功率普遍较高,尤其在操作环境中,DINO-WM的表现明显优于其他基于视觉的世界模型,特别是在面对物体接触丰富的任务时。 - 性能比较
与IRIS、DreamerV3、TD-MPC2等世界模型相比,DINO-WM在多个任务中取得了更好的性能,尤其在复杂的物体操作任务中。传统模型在这些任务中的表现较差,尤其是在需要精确控制和对物体动力学建模时,DINO-WM的预测准确性和规划能力都远超其他方法。
四、总结与展望
DINO-WM为任务无关的世界建模和推理提供了一种新的方法。它通过使用预训练的视觉特征来建模环境动态,并且在测试阶段通过零-shot规划来解决新任务。实验结果表明,DINO-WM在处理多种任务时表现优异,尤其是在需要精确控制的任务中,具有显著的优势。未来的工作可以进一步优化DINO-WM,特别是在更复杂的任务和环境配置下,结合探索策略来增强模型的泛化能力。
DINO-WM的成功表明,预训练的视觉特征可以为机器人控制和任务规划提供强大的支持,而无需依赖任务特定的数据或模型,从而推动了通用世界模型的发展。