近年来,具身智能体(Embodied Agents)在人工智能研究中受到了越来越多的关注。这些智能体需要具备理解环境、感知视觉信息以及执行复杂任务的能力。多模态大型语言模型(Multi-modal Large Language Models, MLLMs)的兴起,使得基于大规模预训练模型的智能体成为可能。然而,当前研究主要集中在语言驱动的具身智能体,而 MLLMs 在具身智能体中的应用仍然缺乏系统性的评估框架。
论文EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents提出 EmbodiedBench,这是一个全面的基准测试框架,专门用于评估视觉驱动的具身智能体。其主要特点包括:
- 多层次任务评估:涵盖 1,128 个测试任务,涉及四个不同环境,包括高层语义任务(如家庭场景)和低层物理交互任务(如导航和操控)。
- 细粒度能力测评:设计六个子集,专门评估智能体的常识推理、复杂指令理解、空间感知、视觉感知、长时规划等关键能力。
通过对 13 个主流 MLLMs(包括专有和开源模型)进行测试,研究发现:
- 现有 MLLMs 在高层次任务(如计划任务)上表现较好,但在低层物理操控任务上存在显著性能瓶颈(最佳模型 GPT-4o 的平均成功率仅为 28.9%)。
- 视觉输入对于低层次任务至关重要,其去除后成功率下降 40%-70%,而高层任务对视觉输入的依赖较小。
本论文作为Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, Tong Zhang,来自University of Illinois Urbana-Champaign, Northwestern University, University of Toronto和Toyota Technological Institute at Chicago。
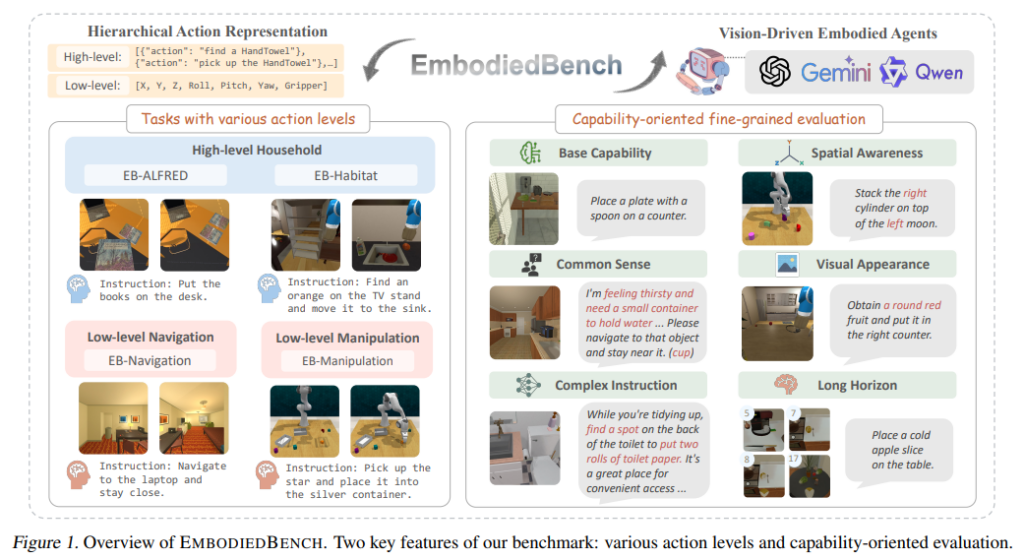
一、相关研究
具身智能体的研究可以追溯到早期的强化学习和机器人研究,近年来随着 LLMs 和 MLLMs 的发展,这些模型在推理和决策任务上展现了强大的能力。然而,目前的评测框架仍然存在局限性。
- LLMs 在高层任务中的应用
- SayCan(Ahn et al., 2022):结合语言模型和强化学习,使机器人能根据自然语言指令执行任务。
- Inner Monologue(Huang et al., 2022):引入反思机制,让智能体在执行过程中调整决策。
- VOXPOSER(Huang et al., 2023):通过 3D 结构建模提升机器人在复杂场景中的适应能力。
- MLLMs 在感知和决策中的应用
- PALM-E(Driess et al., 2023):一个端到端的多模态模型,结合视觉和语言信息,实现跨领域任务。
- RT-2(Brohan et al., 2023):采用 Transformer 结构,将大规模网络知识迁移到机器人控制领域。
- 现有基准测试的局限性
- ALFWorld、VisualAgentBench、AgentBench 等评测框架主要针对 LLMs,缺乏对 MLLMs 在具身任务中的评测。
- VisualAgentBench 是目前唯一针对 MLLMs 评测的框架,但它主要关注高层任务,如家庭任务或 Minecraft 游戏,而低层任务(如精准操控和空间感知)未得到充分研究。
为弥补这些不足,EmbodiedBench 设计了多层次任务和能力评测,涵盖从高层计划到低层操控的完整任务体系。
二、问题建模
具身智能体的行为可以分为高层任务和低层任务,每种任务的复杂性和执行方式不同。
- 具身智能体的行动层次
- 低层次行动(Low-Level Actions):指直接可执行的原子级指令,如
move forward 0.1m。通常采用 7 维向量[X, Y, Z, Roll, Pitch, Yaw, Gripper]进行描述。 - 高层次行动(High-Level Actions):由多个低层行动组成,例如
find a HandTowel可能涉及旋转、扫描目标、接近目标等多个子步骤。
- 低层次行动(Low-Level Actions):指直接可执行的原子级指令,如
- 视觉驱动智能体的决策建模
智能体的决策可建模为部分可观测马尔可夫决策过程(POMDP):
(S,A,Ω,T,O,L,R)
其中:
- S:完整环境状态(不可直接观测)
- A:高层或低层行动空间
- Ω:视觉感知空间
- T:状态转移函数
- O:状态与观测之间的映射
- L:语言指令
- R:任务完成的奖励函数
智能体的目标是通过策略π(at∣L,ht) 最大化任务成功率。
三、EmbodiedBench 设计
EmbodiedBench 包含四个不同环境,每个环境针对特定任务进行评测。
- EB-ALFRED(基于 ALFRED 数据集):
- 任务:高层规划,涉及拾取、放置、打开、关闭等操作
- 评测能力:任务分解、长期计划
- EB-Habitat(基于 Language Rearrangement Benchmark):
- 任务:导航和物品放置
- 评测能力:目标导向任务执行、局部环境探索
- EB-Navigation:
- 任务:目标导向导航
- 评测能力:空间感知、路径规划
- EB-Manipulation(基于 VLMBench):
- 任务:低层次物体操控
- 评测能力:精准动作执行、物体交互
EmbodiedBench 设计六个子集:
- 基本任务能力(Base)
- 常识推理(Common Sense)
- 复杂指令理解(Complex Instruction)
- 空间感知(Spatial Awareness)
- 视觉感知(Visual Perception)
- 长时规划(Long Horizon)
四、实验与分析
- 主要实验结果
- 高层任务表现优异,但低层任务表现不佳,如 GPT-4o 在 EB-ALFRED 取得 56.3% 成功率,而在 EB-Manipulation 仅为 28.9%。
- 视觉输入对低层任务至关重要,去除后成功率下降 40%-70%。
- 长时规划(Long-Horizon)为最难任务,GPT-4o 在此子集仅有 64% 成功率(相比基础任务下降 22%)。
- 误差分析
- 主要错误类型:
- 规划错误(55%):如缺少必要步骤
- 认知错误(41%):如错误终止任务
- 感知错误(4%):如物体识别错误
- 主要错误类型:
五、结论与未来方向
- 改进低层任务执行
- 增强长时规划能力
- 提升视觉感知与空间推理能力
- 优化多步视觉理解
EmbodiedBench 为未来 MLLM 在具身智能体中的应用提供了坚实的评估工具,并为研究者提供了更丰富的分析方法和改进方向。
EmbodiedBench on GitHub: https://embodiedbench.github.io/