论文Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention提出了NSA(Native Sparse Attention)机制。NSA为一种硬件对齐的稀疏注意力架构,能够有效地提升长序列建模的效率。在多个基准测试中,NSA展示了其超越全注意力模型的性能,尤其在长序列处理和推理任务中,NSA能够提供显著的加速效果。实验结果表明,NSA不仅在推理阶段具有优越的性能,在训练阶段也能够高效地进行大规模长序列的学习。
论文作者为Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang(梁文锋), Wangding Zeng,来自DeepSeek,Peking University和University of Washington。
一、引言
随着自然语言处理任务中对长序列建模需求的日益增加,传统的全注意力机制由于其计算复杂度较高,尤其在处理长序列时,成为了计算瓶颈。具体来说,随着序列长度的增加,标准的自注意力机制(如Transformer)所需的计算量呈二次增长,尤其是在解码阶段,计算成本极高。为了解决这一问题,稀疏注意力机制应运而生,旨在通过选择性地计算重要的查询-键对,降低计算量,从而提升处理效率,同时保持较高的模型能力。
在此背景下,本文提出了NSA(Native Sparse Attention)机制,即一种原生可训练的稀疏注意力架构。NSA可通过硬件对齐优化和算法创新,实现在长序列建模中的高效性。NSA的创新之处在于其能够通过精确的动态稀疏策略,不仅有效减小计算量,还能够减少训练时的计算负担,同时保持与全注意力模型相当甚至更优的性能。通过这项技术,NSA模型在多个基准测试上都超越了传统的全注意力模型,尤其在处理长序列时展示了显著的加速效果。
二、稀疏注意力方法的重新思考
现代稀疏注意力方法的核心目标是通过降低计算量,来提升模型的效率,特别是在处理长序列时,稀疏性能够有效减轻计算负担。然而,当前大多数稀疏注意力方法在实际应用中存在一些局限性。主要问题包括:
- 阶段性稀疏性:许多稀疏注意力方法仅在推理阶段(即解码阶段)应用稀疏性,这种做法虽然在推理时能减少计算量,但仍然会受到前期预处理阶段高计算开销的制约。例如,某些方法在推理阶段需要进行复杂的计算来构建注意力图或索引,从而无法实现全局加速。
- 与先进注意力架构的不兼容性:一些稀疏注意力方法未能有效适应现代的多查询注意力(MQA)和组查询注意力(GQA)等架构,这些架构通过共享键-值(KV)对来显著减少解码阶段的内存访问瓶颈。然而,许多稀疏注意力方法依然采用独立的查询头和KV缓存,这使得它们无法充分利用这些先进架构的内存优化特性,从而限制了它们的实际加速效果。
因此,NSA的设计重点在于解决这两个问题。首先,NSA通过硬件对齐的优化方案,使得稀疏性能够有效应用到预处理、解码和训练的每个阶段。其次,NSA采用原生可训练的策略,使得稀疏性不仅仅是推理时的优化,而是能够在整个训练过程中,学习到最优的稀疏模式,从而在提高计算效率的同时,保持较好的模型性能。
三、方法论
NSA的设计包含三个主要的注意力路径,这些路径相互协作,以实现高效的稀疏注意力机制:
- 压缩粗粒度标记(Token Compression):为了减小计算量,NSA首先将标记序列分割成多个块,并对每个块进行压缩处理。具体来说,NSA通过聚合连续的键-值对来生成压缩后的表示,这样做可以保留大部分上下文信息,同时减少计算开销。
- 选择性保留重要标记(Token Selection):虽然压缩后的标记能够有效减少计算量,但它们可能会丢失一些细粒度的信息,因此,NSA还通过选择性保留一些最重要的标记来确保局部上下文信息的完整性。该选择过程通过计算块的重要性分数来完成,并只保留最重要的标记,从而确保了高效计算和上下文精度的平衡。
- 滑动窗口(Sliding Window):为了进一步捕捉局部上下文信息,NSA设计了一个滑动窗口机制。这个机制允许模型在处理输入序列时,能够动态地关注邻近的标记,从而提高局部上下文的精度,尤其在处理长文本时,能够避免因上下文跨度过长而导致的信息损失。
这三种机制结合起来,形成了NSA的完整架构。压缩路径负责全局上下文的扫描,选择路径负责局部精度的保留,而滑动窗口则专注于捕捉局部信息。这些路径的协同工作使得NSA能够在保证全局信息和局部信息都得以有效捕捉的前提下,大幅度减少计算量。
四、实验
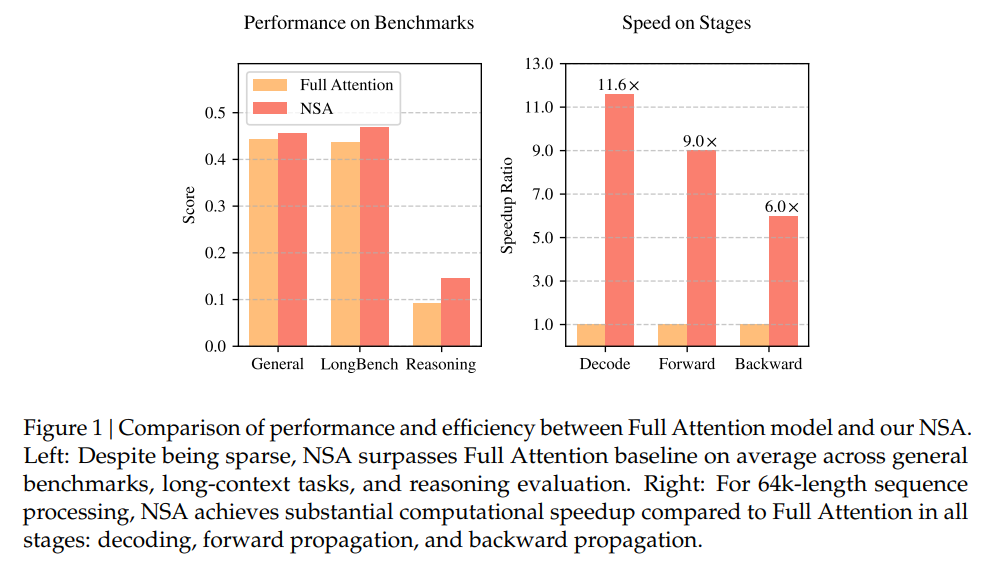
为验证NSA的有效性,本文进行了多轮实验,涵盖了不同的语言评估、长序列评估和推理评估。实验结果表明,NSA在这些任务中均超越了传统的全注意力模型,并且在处理64k长度的序列时,NSA相比全注意力模型展现了显著的加速效果。具体来说,NSA在解码、前向传播和反向传播三个阶段的计算速度均得到了显著提升,尤其是在长序列的处理上,NSA能够提供高达11.6倍的加速。
NSA的训练时间也得到了有效缩短。通过引入硬件优化策略,NSA能够在现代硬件上高效运行,尤其在GPU上,通过优化内存访问模式和计算图,NSA能够最大化硬件的计算能力。
五、效率分析
NSA的硬件对齐优化设计使得它能够在GPU上实现显著的效率提升。与传统的全注意力机制相比,NSA在解码阶段的内存访问量大大减少,从而降低了内存带宽的压力,显著提高了解码速度。具体来说,NSA在64k长度的序列处理中,相比全注意力模型,解码和反向传播的速度分别提高了9倍和6倍。此外,NSA在训练阶段也表现出了较强的效率,特别是在长序列的处理上,NSA的计算效率随着上下文长度的增加而逐渐提高。
六、讨论
NSA在实现高效稀疏注意力的过程中,面临了多个挑战。首先,在标记选择策略方面,NSA采用了块状选择策略,这种策略能够有效地减少计算和内存开销,并最大化硬件的利用效率。其次,NSA在训练过程中采用了可训练的稀疏性策略,这一设计能够确保模型在训练过程中学习到最优的稀疏模式,从而提高了模型的性能。
通过对现有方法的分析和对比,NSA的设计理念在解决现有稀疏注意力方法的局限性方面起到了积极作用。特别是在稀疏性应用的全局优化和局部精度保留方面,NSA展示了其独特的优势。
七、相关工作
本文回顾了现有的几种稀疏注意力方法,包括基于固定稀疏模式的方法、动态标记修剪方法和查询感知选择方法。与这些方法相比,NSA通过结合硬件优化和训练优化,解决了现有方法中的多个瓶颈,尤其在长序列的建模和推理任务中,NSA表现出了明显的性能优势。