论文A survey on FPGA-based accelerator for ML models对基于现场可编程门阵列(FPGA)机器学习(ML)加速器的研究现状及发展趋势进行了全面综述。论文作者为Feng Yan, Andreas Koch, Oliver Sinnen,来自University of Auckland和Technische Universitat Darmstadt。
一、引言
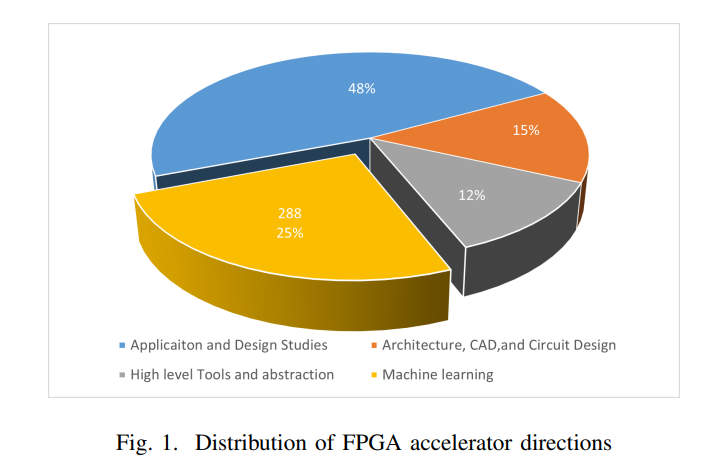
论文全面综述了基于现场可编程门阵列(Field-Programmable Gate Arrays , FPGA)的机器学习(ML)加速器的研究现状及发展趋势,特别关注推理和训练任务在FPGA上的实现。作者选择了过去六年内四大顶级FPGA会议(FCCM、FPL、FPT等)的1138篇论文,其中深入分析了287篇,与ML相关的研究占据了显著比例(25%)。这一趋势表明,FPGA技术和ML模型之间的结合正逐步加深,成为推动技术进步的重要动力。
FPGA作为一种可重配置的硬件平台,其灵活的逻辑单元和内存架构为ML模型的实现提供了独特的优势。与通用的中央处理器(CPU)相比,FPGA能够通过高度并行化的计算满足实时任务需求,而相比图形处理器(GPU),FPGA的能效表现更为卓越。近年来,随着ML模型复杂度的增加,尤其是深度神经网络(DNN)的规模日益庞大,对高性能硬件的需求变得更加迫切。FPGA凭借其动态可重配置能力、高能效比和架构灵活性,逐渐成为ML推理和训练任务的理想平台。
文章在引言中提出了一系列关键问题,例如:FPGA的架构设计是否主要偏向于推理任务?FPGA在满足模型复杂计算需求和数据管理方面存在哪些挑战?这些问题为后续研究提供了明确的方向。此外,作者还强调了FPGA在实现神经网络(NN)模型、特别是卷积神经网络(CNN)方面的显著优势,以及在非神经网络模型加速中的潜在价值。这些讨论奠定了本文系统研究FPGA加速器在ML领域中的学术基础。
二、FPGA在机器学习中的计算流程
文章详细分析了FPGA加速ML模型的计算流程,并将研究范围划分为推理与训练两大部分。
- 推理与训练的分布
研究数据显示,FPGA加速的研究主要集中于推理任务,占研究总量的81%。相比之下,训练任务的研究仅占13%,其余部分涉及矩阵运算等基础操作(6%)。这种不均衡的分布反映了FPGA当前在ML加速中的主要应用方向。推理任务的优势在于其对实时性要求较高,而FPGA的架构灵活性和并行处理能力正好能满足低延迟需求。 - 推理的关键驱动因素
(1)低延迟需求:在自动驾驶、视频监控等实时应用场景中,FPGA凭借其可定制化的计算单元和高效的内存层级,能够显著降低推理延迟。例如,在某些实时图像识别任务中,FPGA通过优化数据传输路径,满足毫秒级的延迟需求。此外,FPGA灵活支持不同的位宽与数据精度,进一步提升了能效比。
(2)能效优化:能效是推理任务中的重要设计目标,特别是在物联网(IoT)设备和边缘计算场景中。FPGA通过动态功率管理和低精度计算等技术,降低了推理能耗。例如,FPGA的流处理架构减少了不必要的数据移动,结合片上存储优化,实现了高能效推理。
- 训练加速的挑战与潜力
训练任务面临的数据处理复杂性为FPGA的应用带来了显著挑战。FPGA的片上存储资源有限,难以同时处理大规模训练数据。此外,训练过程中需要频繁的梯度更新操作,FPGA在处理这类复杂的计算依赖时容易受到数据传输瓶颈的限制。
为应对上述问题,研究提出了一些创新的解决方案。例如,稀疏化技术通过减少模型权重的冗余性,降低了对存储资源的需求;分布式训练架构则利用多个FPGA节点进行并行计算,从而提升整体效率。同时,硬件与算法协同设计(co-design)成为优化训练加速的重要趋势,这种方法不仅关注FPGA架构的优化,还在算法层面对数据流和计算模式进行改进。
- 矩阵运算的重要性
矩阵运算是ML算法的核心操作,其性能优化直接影响模型的整体表现。FPGA凭借高度并行化的计算能力,能够显著加速矩阵运算。例如,FPGA通过自定义矩阵乘法电路,实现了高效的浮点运算。此外,FPGA在稀疏矩阵处理中的表现尤为突出,这对图神经网络(GNN)等模型的加速具有重要意义。
三、不同模型的FPGA加速研究
- CNN加速研究
CNN在FPGA加速研究中占据主导地位。这得益于CNN在计算机视觉任务中的卓越性能,例如图像分类、目标检测和语音识别等。CNN的局部连接特性减少了对数据传输的需求,而权重共享机制则提高了计算资源的利用率。FPGA通过这些特性实现了对CNN的有效加速。
此外,量化(Quantization)和剪枝(裁剪,Pruning)是CNN优化的两大关键技术。量化通过将浮点权重转换为定点表示,减少了模型的存储需求和计算复杂度;剪枝则通过移除冗余连接,进一步压缩了模型规模。
- RNN加速研究
RNN因其在时间序列和自然语言处理中的广泛应用而备受关注。尽管RNN的递归结构带来了数据依赖性和存储瓶颈,但FPGA通过定制化架构设计,在降低延迟和提高并行性方面取得了显著进展。例如,长短期记忆网络(LSTM)和门控循环单元(GRU)的硬件实现成为RNN加速研究的重点。 - GNN加速研究
GNN因其处理图结构数据的能力而受到广泛关注。FPGA通过灵活的数据路径设计,能够高效处理GNN的稀疏矩阵运算和动态图更新任务。研究还提出了多种硬件优化策略,例如分块处理和硬件加速框架,进一步提升了GNN的训练和推理效率。 - 注意力机制与Transformer加速
Transformer模型的成功推动了基于注意力机制的研究。FPGA通过矩阵运算优化和非线性计算加速,显著提升了Transformer的计算效率。例如,动态量化技术和分片矩阵操作实现了对大规模序列任务的高效支持。 - 传统机器学习模型加速
尽管神经网络模型占主导地位,传统机器学习模型(如k近邻、决策树等)在特定场景中仍具有重要意义。FPGA通过定制化的计算单元和低功耗设计,提升了这些传统模型在实时应用中的性能。
四、研究趋势与展望
本文总结了FPGA在ML加速领域的研究趋势,指出未来的研究可能集中于以下方向:
- 模型融合:探索CNN、GNN和Transformer的结合,以满足多样化的应用需求。
- 特定场景优化:针对边缘计算和大规模数据处理场景,开发专用加速器。
- 硬件与算法协同设计:通过结合算法创新和硬件优化,实现性能与能效的双重提升。