论文Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse探讨了思维链(或称“逐步推理”,Chain-of-Thought, CoT)在某些任务中可能会导致大型语言模型(LLM)性能下降的情况。
随着大型语言模型(LLM)和多模态模型(LMM)的发展,思维链CoT逐渐成为这些模型中一种普遍使用的推理方式。这种方法通过在回答之前进行逐步的逻辑推导,使得模型可以更好地处理需要复杂推理的任务,例如数学运算和符号逻辑。然而,这种方法并不总是能提升模型的性能。在某些情况下,思维链CoT甚至会导致模型性能下降。因此,本论文的研究重点在于识别和分析哪些任务中思维链CoT对模型产生了负面影响,尤其是借鉴认知心理学中关于人类在某些任务中经过深思熟虑后表现反而变差的现象。通过对比人类和模型的认知过程,研究希望找到CoT影响模型表现的规律和特征,从而为未来模型推理策略的选择提供依据。
论文作者为Ryan Liu, Jiayi Geng, Addison J. Wu, Ilia Sucholutsky, Tania Lombrozo, Thomas L. Griffiths,来自Princeton University和New York University。
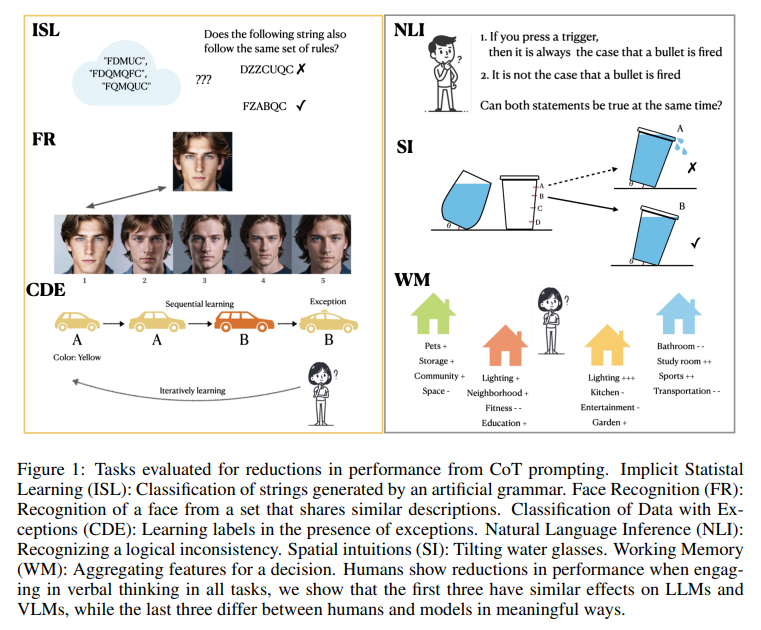
论文提出了两个关键的研究假设:
- 当任务中“口头思考”或深思熟虑会影响人类表现时,类似的推理方式(如思维链CoT)可能也会对模型的表现产生负面影响。
- 这些影响是基于任务的性质及人类和模型在任务中的限制的相似性,因此,模型在某些情况下可能会复现人类的失败模式,而在其他情况下不会。
为了验证这些假设,作者设计了六类实验,其中三类任务满足人类表现受损的条件,同时适用于语言模型;另外三类任务尽管人类表现变差,但由于模型与人类的认知方式不同,思维链CoT对模型的影响可能不相同。
具体来说,作者选择了以下六类任务:
- 隐式统计学习(Implicit Statistical Learning)
- 面部识别(Facial Recognition)
- 处理包含例外的分类(Classification with Exceptions)
- 逻辑不一致性检测(Logical Inconsistency Detection)
- 空间直觉任务(Spatial Intuition Task)
- 聚合多维特征的决策任务(Aggregating Features for Decision Making)
实验一:隐式统计学习
1. 实验背景
隐式统计学习是指人类在没有显式学习规则的情况下,能够从一系列输入中无意识地学习出其内在的统计规律。例如,在人工文法学习任务中,人们被要求对字母序列进行分类,即判断它们是否符合某种规则。研究表明,人类在这种情况下往往无法用语言描述学习到的规则,但却能通过直觉判断出哪些序列是合法的。然而,如果被要求用语言描述这些规则,人类的分类表现会显著下降。
2. 实验设计与模型选择
在本研究中,作者模拟了这种隐式学习的情境,生成了100个由有限状态自动机(FSG)生成的字母序列,并要求多个大型语言模型(如OpenAI o1-preview、GPT-4o、Claude 3 Opus等)在零样本(zero-shot)和思维链(CoT)条件下进行分类。每个分类问题包含15个训练样本和44个测试样本,其中一半是合法序列,另一半则通过对合法序列进行随机修改得到。
3. 实验结果与分析
结果显示,思维链CoT显著降低了模型的表现。例如,OpenAI o1-preview模型在思维链CoT条件下的分类准确率比GPT-4o零样本条件下降了36.3%。这一结果表明,思维链CoT导致模型倾向于通过显式的语言逻辑来推导隐式模式,而这种方法并不适用于捕捉复杂的统计规律,反而影响了模型对数据的归纳能力。这与人类在这种任务中的表现非常类似,即语言描述的干预可能会破坏对隐式规律的感知。
实验二:面部识别
1. 实验背景
面部识别任务通常涉及视觉特征的识别和匹配。在人类的认知实验中,要求参与者对看到的面部进行口头描述,往往会导致其之后的面部识别表现下降,这被称为“语言遮蔽效应”(Verbal Overshadowing)。这是因为语言在描述视觉细节方面存在局限性,难以有效捕捉面部的独特特征。
2. 实验设计与模型选择
作者使用了由生成模型生成的人脸图像数据集,包含了不同性别、种族、发色、眼睛颜色等特征的面孔。每个问题由一张目标人脸和五张候选人脸组成,其中只有一张与目标人脸匹配。视觉语言模型(如GPT-4o、Claude 3 Opus等)被要求在零样本和思维链CoT条件下进行面部匹配。
3. 实验结果与分析
所有测试的视觉语言模型在思维链CoT条件下的表现均有所下降。例如,Claude 3 Opus模型的准确率从零样本的44.0%下降到思维链CoT的29.6%。这表明,思维链CoT引入了语言的干预,可能使模型更倾向于通过描述性语言来理解视觉特征,导致对面部细节的捕捉不足。这与人类在面部识别任务中的表现类似,即口头描述会干扰视觉记忆的细节处理。
实验三:处理包含例外的分类
1. 实验背景
在处理包含例外的分类任务中,人类通常倾向于寻找简单、广泛适用的分类规则。然而,当数据中包含不符合这些规则的例外时,这种策略会导致错误的分类结果。研究表明,要求人类对分类过程进行解释时,他们更容易陷入简单规则的陷阱,从而增加学习时间和错误率。
2. 实验设计与模型选择
在该实验中,作者构造了一组车辆分类任务,要求模型对具有多个特征(如颜色、形状等)的车辆进行分类。数据集中包含一些例外情况,使得单一的特征无法完全描述分类规则。模型需要在多轮训练中不断调整分类策略,直到所有车辆的分类均正确。
3. 实验结果与分析
结果显示,思维链CoT显著增加了模型学习正确分类的时间。例如,GPT-4o在思维链CoT条件下需要的迭代次数是直接分类的四倍以上。这表明,思维链CoT让模型倾向于尝试找到一种普适的规则来描述数据,但由于存在例外,这种策略反而增加了学习的复杂度。
实验四:逻辑不一致性检测
1. 实验背景
在某些逻辑推理任务中,人类在解释逻辑不一致性时,往往会更倾向于寻找一种合理的解释,而忽略不一致性本身,导致判断错误。这种现象是否会在语言模型中复现是一个有趣的问题。
4. 实验设计与模型选择
作者利用自然语言推理数据集(如SNLI、MNLI)构建了逻辑不一致性检测任务,要求模型判断两句子是否存在逻辑不一致。在思维链CoT条件下,模型被要求首先对两句子之间的关系进行解释,然后再作出判断。
5. 实验结果与分析
实验结果表明,在逻辑推理任务中,思维链CoT反而提高了模型的表现。例如,GPT-4o在思维链CoT条件下的准确率比零样本条件提高了40%以上。这可能是因为逻辑推理任务需要更深层次的理解和推理,而思维链CoT正好有助于这一过程。
实验五:空间直觉任务
1. 实验背景
人类在进行空间推理时,往往依赖于视觉或运动模拟,而不是语言描述。例如,倾斜杯子使水面保持水平的任务中,视觉或运动直觉比语言描述更为有效。
2. 实验设计与模型选择
作者模拟了倾斜杯子的任务,让模型判断如何让两个不同高度和形状的杯子中水面保持水平。模型被提供一张包含两个杯子的图像,并被要求选择正确的水位高度。
3. 实验结果与分析
结果显示,思维链CoT并未显著改变模型的表现。由于大型多模态模型缺乏人类的运动模拟能力,其推理主要依赖于语言和视觉输入,因此在此类任务中无法获得与人类类似的直觉优势。
实验六:聚合多维特征的决策任务
1. 实验背景
在需要考虑多个维度特征的复杂决策任务中,例如选择最佳公寓,人类往往会因信息量过大而在深思熟虑后作出错误决策。而模型可以通过思维链CoT有效聚合多维信息,因此表现可能不同于人类。
2. 实验设计与模型选择
作者构造了一组包含多个特征描述的公寓选择任务,要求模型根据这些描述选出最佳公寓。特征描述数量远超人类的工作记忆容量,因此任务对模型和人类的难度差异较大。
3. 实验结果与分析
结果显示,思维链CoT帮助模型更好地聚合多维信息,从而提高了决策准确率。例如,Claude 3.5 Sonnet在思维链CoT条件下的准确率从62%提高到72%。这表明,模型的上下文窗口能力使其能够在面对复杂的多维信息时,借助思维链CoT进行更全面的分析和决策。
研究结论与广泛影响
论文通过六组实验,系统性地分析了思维链CoT在不同任务中的效果,发现其性能表现取决于任务的性质以及模型与人类在任务上的认知差异。对于那些“深思熟虑”会损害人类表现的任务,思维链CoT通常也会导致模型性能下降。而在某些任务中,模型由于具备不同于人类的认知特点,如更大的上下文窗口或对逻辑推理的适应性,思维链CoT反而对其表现有积极影响。
这种研究为我们理解提示选择和推理方式提供了新的视角,提醒我们不能简单地将思维链CoT作为提升模型性能的默认策略。在实际应用中,需要结合任务特征,权衡是否使用思维链CoT,以避免不必要的性能损失。这对未来的模型设计和推理策略优化具有重要意义。