论文Joint Semantic Knowledge Distillation and Masked Acoustic Modeling for Full-band Speech Restoration with Improved Intelligibility提出了一种新的语音恢复生成框架MaskSR2,主要目标是提高恢复语音的清晰度和质量,尤其是在全频带(44.1kHz)条件下。该框架基于先前的MaskSR模型,结合了语义知识蒸馏(Semantic Knowledge Distillation)和掩码声学建模(Masked Acoustic Modeling)来预测目标语音的声学细节,从而改善语音的可懂度(用词错误率WER衡量)和整体质量。
论文作者为Xiaoyu Liu, Xu Li, Joan Serrà, Santiago Pascual,均来自Dolby Laboratories。
论文内容概要如下:
语音恢复(Speech Restoration, SR) 是从受损的语音信号中恢复出高质量的、全频带(44.1kHz)语音。相比传统的语音增强(Speech Enhancement, SE)主要解决去噪和去混响问题,语音恢复更具挑战性,因为它还要处理带宽扩展、丢包等问题。尽管现有的生成模型如MaskSR在恢复语音的感知质量上取得了不错的结果,但却无法显著提高语音的可懂度(Word Error Rate, WER),甚至在某些情况下,恢复后的语音WER比受损语音更高。这是因为现有模型在去除失真的过程中可能改变语音中的音韵信息。
为了解决以上问题,论文提出了MaskSR2,在MaskSR的基础上,通过引入语义知识蒸馏(Semantic Knowledge Distillation, KD)机制,显著改善了语音的可懂度,同时保持了高质量。MaskSR2的核心创新在于:
- 无需转录数据:通过使用自监督学习的预训练模型HuBERT来提取语音的语义表示,避免了依赖大型转录语料。
- 在推理阶段计算成本不变:训练时使用HuBERT作为教师模型,推理时舍弃该模型,因而在推理时的计算开销与MaskSR相同。
1. 技术方法详解
1.1 MaskSR2架构
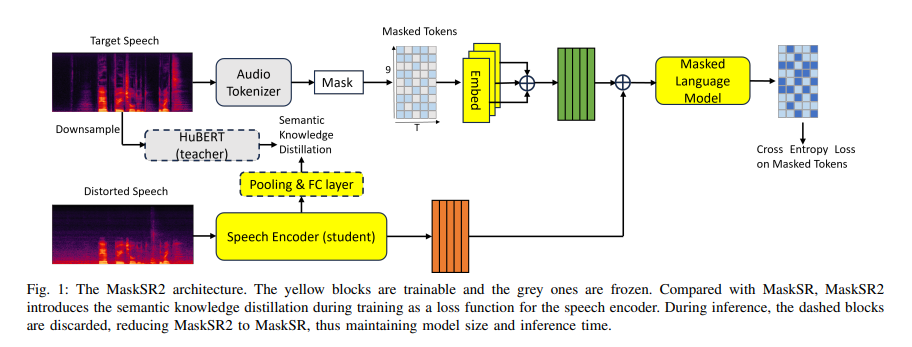
论文的创新模型MaskSR2通过两个主要模块来实现语音恢复:语音编码器(Speech Encoder)和生成模型(Generative Model)。
- 语音编码器:语音编码器的任务是从受损的语音信号中提取其语义信息。在训练过程中,输入的语音信号先经过短时傅里叶变换(STFT),然后通过批量归一化层和全连接层转化为固定维度的特征表示。随后,这些特征被输入到一系列自注意力的Transformer块中,生成语音的潜在语义嵌入。通过引入语义知识蒸馏机制,MaskSR2使用一个预训练的HuBERT模型作为“教师模型”,为语音编码器提供目标语音的语义表示,从而无需依赖转录文本来指导模型训练。
- 生成模型:生成模型基于掩码生成技术MaskGIT。目标语音的声学标记(acoustic tokens)通过预训练的DAC模型进行量化,生成一组离散的标记。这些标记编码了目标语音的细节声学信息。模型通过掩码机制,逐步填补被掩盖的声学标记,最终生成目标语音波形。
1.2 语义知识蒸馏
MaskSR2在语音编码器中引入了语义知识蒸馏机制,即使用来自预训练HuBERT模型的语义表示指导编码器学习。这个蒸馏过程通过三个不同的特征选取策略实现:
- L9-K500:将HuBERT第9层的特征进行k-means聚类,生成500个离散的伪音素类。
- L9-feature:直接使用第9层的连续特征,这些特征包含了丰富的音韵信息和其他与语音恢复任务相关的特征,如说话人差异和韵律信息。
- Avg-feature:使用HuBERT模型所有12层的平均特征,这样可以利用每层特征在不同任务上的优势,可能对生成语音的整体质量更有帮助。
为了确保训练的稳定性,目标特征在每个训练样本上都进行了均值和方差归一化。通过与传统的频谱目标对比实验,论文表明,使用HuBERT的语义表示进行蒸馏相比于直接回归到频谱特征(如STFT)显著改善了语音的可懂度。
1.3 掩码声学建模
生成模型使用MaskGIT机制进行掩码声学建模。目标语音的声学标记通过预训练的DAC模型进行量化。训练时,部分声学标记被随机掩盖,生成模型通过这些掩码位置来预测目标语音的声学标记。推理阶段,模型通过迭代生成目标声学标记,最终生成语音波形。
1.4 推理优化
在推理阶段,MaskSR2通过采样机制生成声学标记,并在每次迭代中重新掩盖低置信度的标记。这种迭代生成的过程能够有效改善目标语音的质量。此外,MaskSR2通过Classifier-free guidance策略来进一步降低WER,这个策略通过在训练时随机替换编码器输出,在推理时以更大权重条件化生成过程,确保生成的语音能够更好地保留原始音素信息。
2. 实验设计与结果
2.1 实验数据
- 训练集:使用了包括DNS Challenge、VCTK和AISHELL-1等多种清晰语音数据,总计800小时,并使用181小时的噪声数据和60,000个房间脉冲响应来模拟不同的失真情况。
- 测试集:为了评估模型性能,论文使用了自生成的44.1kHz全频带测试集和16kHz宽频带测试集,测试样本中包含噪声、混响、带宽限制和剪切等失真情况。
2.2 评价指标
- DNSMOS 和 SESQA 作为参考自由感知质量的评估指标,用于评估生成模型的整体感知质量。
- WER(词错误率)用于评估语音的可懂度,通过ASR系统来测量。
- Speaker Similarity:通过余弦相似度来衡量生成语音与目标语音的说话人相似度。
- 主观听觉测试:通过13名专家听众对生成语音的主观评分进行验证,综合评估语音的感知质量。
2.3 实验结果
实验结果表明,MaskSR2显著提高了生成语音的可懂度和感知质量。具体地:
- 在VCTK测试集上,MaskSR2相较于MaskSR在保持相同推理时间和模型容量的情况下,WER降低了37.9%。
- 主观听觉测试显示,MaskSR2生成的语音质量接近目标语音,并显著优于其他生成模型。
- 在更具挑战性的LibriSpeech测试集上,MaskSR2的WER降低了18.9%,进一步证明了其语义知识蒸馏对语音生成可懂度的重要性。
3. 未来工作方向
论文提到,未来可能探索更强大的自监督学习模型和多任务语音编码器来进一步提升性能。例如,考虑使用WavLM等更强大的模型,或通过多个教师模型的联合学习来提升生成语音的质量和可懂度。