论文Scalable Learning of Segment-Level Traffic Congestion Functions提出了一种可扩展的数据驱动框架,用于识别道路分段级别的交通拥堵(模式)函数。这种方法能够在全球范围内实现交通拥堵模型的高效识别和泛化,通过深度学习模型来捕获车流量、车速和密度之间的关系。
论文作者为Shushman Choudhury, Abdul Rahman Kreidieh, Iveel Tsogsuren, Neha Arora, Carolina Osorio, Alexandre Bayen,来自Google Research。
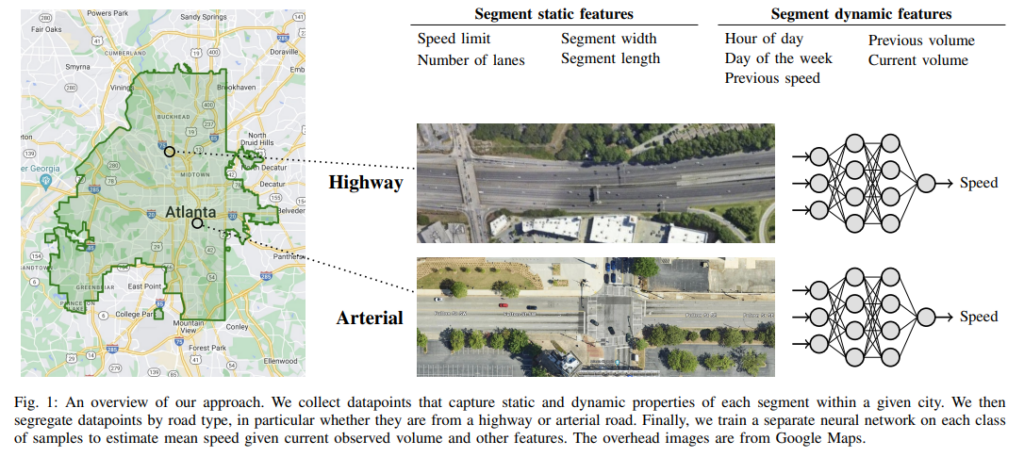
1. 研究背景与目标
城市交通是现代社会生活的重要组成部分,影响着居民的出行安全、环境的可持续性以及生活质量。交通拥堵的精确预测和建模,对于改善城市交通管理和优化道路利用率具有重要意义。尤其是随着智能导航系统和城市交通规划的发展,精准的拥堵模型能够帮助实时优化路径选择,减少旅行时间,降低碳排放量。
传统的交通建模方法往往依赖于“基本图”(Fundamental Diagram, FD),即流量、车速和车密度之间的函数关系。大多数此类方法基于预定义的函数形式,并在各个路段单独拟合参数。这种方法面临许多挑战,如需要大量的观测数据,对物理特性的依赖,以及难以在城市甚至全球范围内扩展。因此,本文的研究目标是开发一种数据驱动的框架,通过在全球范围内的数据集上训练单一的“拥堵函数”(Congestion Function, CF),从而实现对各路段交通行为的统一建模和预测。
2. 提出的方法概述
论文提出的方法基于深度学习技术,特别是使用全连接的前馈神经网络来学习道路分段级别的交通拥堵函数。具体而言,该方法首先通过结合静态和动态的道路特征,构建一个综合的数据集。然后使用该数据集来训练一个单一的神经网络模型,以估计每个道路分段的交通速度。这样做的目的是实现模型在不同路段、不同城市之间的泛化,克服数据稀缺和不一致带来的挑战。
主要步骤包括:
- 数据收集与特征提取:将交通数据汇集在一个包含所有路段的综合数据集中,数据来源包括静态特征(如道路几何特性、车道数、限速等)和动态特征(如时间编码、历史车流量和速度等)。
- 模型训练:使用全连接的前馈神经网络进行训练,学习从部分车流量预测道路段平均速度的函数关系。模型通过优化损失函数(逆速度的均方误差)来最大程度提高预测精度。
- 模型评估与验证:在多个城市的高速公路和主干道上对模型进行测试,评估其在已观测和未观测路段、以及跨城市的泛化能力。
3. 特征与模型设计详解
在该方法中,特征的选择和神经网络的设计是核心。论文详细描述了模型使用的特征类型、模型结构以及如何利用这些特征进行拥堵函数的学习。
3.1 静态特征
静态特征是那些在短期内不随时间变化的道路属性,这些特征主要用于帮助模型在不同路段之间进行泛化,具体包括:
- 路段长度(Length):表示路段的几何长度,单位为米。
- 车道数(Lanes):该路段中沿行驶方向的车道数。
- 车道宽度(Width):所有车道的总宽度,单位为米。
- 限速(Speed Limit):该路段的限速,单位为米/秒。
3.2 动态特征
动态特征是那些随时间变化的道路和交通量信息,帮助模型在时间序列中更好地学习交通流速之间的关系,包括:
- 时间编码(Temporal Encoding):对时间(如一天中的某个小时和一周中的某天)进行正弦-余弦编码,以捕获信号的周期性。
- 标准化流量(Normalized Flow):用车流量除以路段长度和车道数,以捕获单位长度和单位车道的流量。
- 前期测量(Previous Measurements):包括前一个时间间隔的车流量和速度,这些历史信息可以增强模型对当前时段交通状态的预测能力。
3.3 路段优先级聚类
由于不同类别的道路(如高速公路和主干道)具有不同的交通行为,因此模型在训练时需要将路段按类型聚类。具体地,论文将路段分为两类:
- 高速公路(Highway):主要用于连接区域的高速路段,可能存在部分或完全的访问控制。
- 主干道(Arterial):用于城镇或邻近社区间的连接,或者从小型支路通往大型道路。
4. 实验与结果分析
论文在多个大都市区域进行实验,以验证所提出方法的有效性与泛化能力。
4.1 数据集
研究的数据集涵盖了全球多个主要城市(如亚特兰大、洛杉矶、慕尼黑、伦敦、大阪、迪拜)的路段信息,统计信息表明每个城市的路段数均超过数万,并且涵盖不同的交通模式和道路结构。该数据集来源于Google Maps的道路网络数据和驾驶趋势,测量频率为每小时一次,涵盖了每周所有天,从早上7点到晚上10点之间的时间段。
4.2 模型设置与训练
训练模型时,论文采用了全连接前馈神经网络,输入层对每个特征进行零均值和单位标准差的标准化,隐藏层采用指数线性单元(ELU)作为激活函数,输出层使用Sigmoid激活来预测逆速度。损失函数选择了L2平方误差,专注于低速时段的预测精度。整体模型参数如批大小为256,训练的总轮数为30次。
4.3 实验结果
论文的实验结果从多个角度对模型的表现进行了评估,包括预测性能、泛化能力,以及跨城市的迁移能力。
4.3.1 与传统方法的对比
论文将所提出的数据驱动模型与传统的“每段路段独立拟合模型”(例如Bureau of Public Roads模型,BPR)进行了对比。结果显示,在高速公路上,数据驱动模型的预测误差与基于每段路段单独拟合的方法相当,甚至在一些情况下表现更好。然而,在主干道上,模型的预测误差相对较大,这可能是因为主干道的交通动态更加复杂。
4.3.2 泛化能力评估
- 未观测路段的泛化能力:模型在80%的路段上训练,在剩余20%未见过的数据上进行测试,使用了5折交叉验证。结果显示,模型在新路段上的表现与在原始训练路段上的表现相似,说明其具有良好的泛化能力。
- 跨城市的迁移学习能力:模型还在跨城市的“零样本迁移学习”中进行了测试,即在一个城市训练的模型直接应用于另一个城市。结果显示,欧美城市之间(如洛杉矶到慕尼黑)的迁移效果较好,而从亚洲城市(如大阪)迁移到欧美城市的效果相对较差,这可能与不同城市之间的交通模式差异有关。
4.3.3 拓展分析:关键密度预测
为了验证模型的下游效用,论文进一步研究了其是否能够预测与道路段交通流量相关的重要参数,特别是“关键密度”(critical density),即道路段从自由流到拥堵状态的转换点。通过模型预测的速度和流量关系,模型成功地预测了道路段的关键密度,并与基于BPR模型和真实数据计算的关键密度进行了对比。结果表明,数据驱动模型在没有特定参数拟合的情况下,仍能准确预测关键密度,证明了模型在提取道路段特性方面的有效性。
5. 讨论与未来方向
论文在讨论部分详细分析了该方法的优势与局限性,并提出了未来的研究方向:
- 优缺点分析:这种数据驱动方法的一个显著优点是能够在全球范围内扩展,而无需为每个路段单独拟合参数。在高速公路上,模型表现出与传统分段方法相媲美甚至更优的性能,但在主干道上的表现还有提升空间。这可能需要更多的特征以及更复杂的网络结构(如图神经网络)来捕获更复杂的交通行为。
- 未来研究方向:未来的工作可以包括优化特征选择、引入更多的动态特征(如交通信号灯、周边路段的影响等),以及更复杂的模型架构(如引入图神经网络或物理约束)。此外,论文还建议在开放数据集上验证模型性能,并探索将其应用于城市交通仿真,以实现更加智能化的交通管理。
6. 结论
本文提出了一种可扩展的、基于深度学习的数据驱动方法,用于识别全球范围内道路分段级别的交通拥堵函数。通过综合静态与动态特征,论文在全球多个主要城市的道路网络上验证了其方法的有效性和泛化能力。结果显示,这种方法在高速公路段的表现尤为突出,尤其是在未观测数据和跨城市的应用中,展示了较强的泛化能力。
未来的研究可以继续优化和扩展该框架,以实现更精确的交通预测和更广泛的应用场景,例如智能导航、城市交通管理,以及智能城市规划等领域。通过将交通物理知识和深度学习技术结合,未来或许能够实现一个既能大规模应用又具有高精度的智能交通预测系统。