论文Relationships are Complicated! An Analysis of Relationships Between Datasets on the Web(《关系很复杂!对网络数据集之间关系的分析》)由Google研究团队的Kate Lin、Tarfah Alrashed和Natasha Noy撰写,研究了网络上数据集之间的复杂关系,从用户如何发现、使用和共享数据集的角度来理解这些关系的意义和应用。论文的核心是提出一种全面的数据集关系分类体系,并探索这些关系在用户任务中的作用,以及如何通过不同的方法来识别这些关系。
1. 研究背景和动机
随着科学研究对开放数据的依赖越来越高,数据集的发布量呈现出快速增长的趋势。不同于传统的科学出版物,数据集通常不是静态或独立的,它们可能存在多个版本,或者被研究者重新组合、派生出新的数据集。这些数据集之间的关系具有重要的实际意义,例如在验证研究结果时需要精确地知道作者使用了哪个数据集的版本,或者在评估数据的可信度时,用户可能希望找到来自他们信任的存储库中的数据版本。因此,理解这些数据集之间的关系,对于数据的选择、使用、整合和可信度评估至关重要。
2. 数据集关系的全面分类
论文提出了一种全面的数据集关系分类体系,旨在理解网络上数据集之间的各种关系。作者将这些关系分为基于来源的关系和非基于来源的关系。
2.1 基于来源的关系
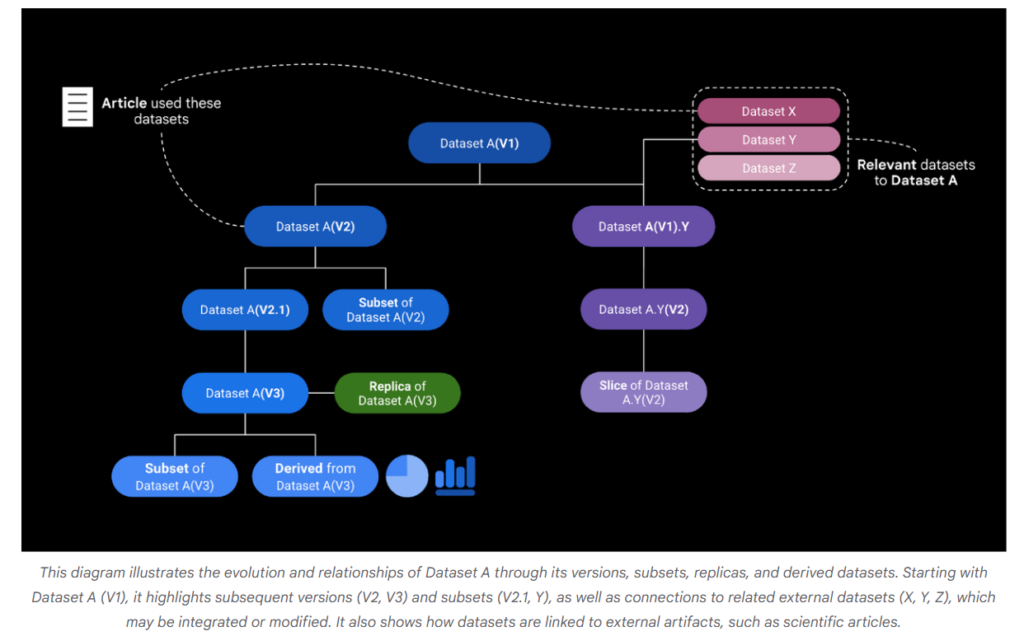
基于来源的关系主要集中于数据集的生成、派生及其变化过程。这类关系涉及数据集的版本控制、子集提取、派生关系等。具体包括以下几种:
- 副本关系(Replica):两个数据集是彼此的副本,意味着它们在内容上完全相同,但发布于不同的平台或网站上。例如,欧洲数据门户可能会聚合各成员国的数据集,因此这些国家的数据集会在多个地方重复发布。识别副本关系对于用户选择可信来源、避免重复下载相同数据非常重要。
- 版本关系(Version and Revision):两个数据集是彼此的版本或修订,意味着它们来源相同,但在内容上存在某些差异。通常,版本之间的变化可能是由于数据的增加、错误的修正,或者结构的调整。这种关系对于确保数据的可重复性至关重要,尤其是在科学研究中,明确使用的具体版本有助于保证结果的准确和可追溯性。
- 子集关系(Subset):一个数据集是另一个数据集的子集,即它是从更大的数据集中提取的一部分数据。例如,美国人口普查局发布的统计数据可能包含按年、按地区的数据子集。理解子集关系有助于用户更好地对数据进行筛选和定位,从而选择最适合的部分用于特定的分析任务。
- 派生关系(Derivation):派生数据集通过对一个或多个原始数据集的加工、转换或聚合而得到。这种关系的存在表明派生数据集在某些方面对原始数据集进行了增值处理。例如,将多个气象数据集汇总成一个全国性的天气统计数据集就是一种派生关系。
- 变体关系(Variant):变体关系指两个数据集共享相同的来源和收集方式,但在某些特定维度上有所不同,例如时间或空间。举例来说,某个数据集可能包含不同年份的气象数据,而这些数据集是彼此的变体。变体关系使得用户能够在不同条件下进行对比分析,以发现数据中的潜在规律和趋势。
2.2 非基于来源的关系
非基于来源的关系则是后天产生的,它们与数据集的使用场景、内容相似性、任务相关性等因素有关。具体包括以下几种:
- 主题相似关系(Topically Similar):数据集在主题或内容上相似,例如涉及相同研究领域但具体指标不同的两个数据集。主题相似性关系帮助用户在寻找特定主题的数据时,找到覆盖类似主题的替代数据集,以便进行更加全面的分析。
- 任务相似关系(Task-similar):任务相似性指的是两个数据集适合完成相似的任务,尽管它们的具体内容和数据结构可能不同。例如,不同类型的交通数据集可能都适用于交通流量预测模型训练。
- 可集成关系(Integratable):两个数据集之间的可集成关系意味着它们可以通过某些公共字段或外键进行整合。例如,一个交通事故数据集可以通过位置和时间字段与交通流量数据集进行关联,从而进行更加深入的分析。这类关系有助于用户将多种数据来源整合起来,以实现复杂的数据分析和知识发现。
3. 数据集关系与用户任务的关联
论文将这些数据集关系与用户在数据集发现和使用中的任务紧密联系在一起。用户在使用数据集时通常需要完成以下几类任务:
- 查找数据集:随着数据量的不断增加,传统的搜索引擎难以满足用户的需求,特别是在用户需要某特定版本的数据或某类特定条件的数据时。理解数据集的版本、子集、派生等关系可以帮助用户更加高效、精确地查找合适的数据集。
- 评估数据集的可信度:数据集的可信度是用户在决定使用数据集之前需要评估的一个重要因素。数据集的来源、版本号、数据的更新频率等信息可以帮助用户判断数据的可靠性和可信度。例如,通过了解某数据集的派生关系,用户可以判断其是否具备所需的质量和可信度。
- 引用和引用管理:在科学研究中,引用数据集的过程类似于引用学术文献。为确保数据的透明性和可重复性,必须精确引用数据的版本和来源。了解数据集之间的派生、子集等关系,有助于更好地引用数据集,确保学术工作的完整性和可验证性。
- 数据集的整理与管理:数据集的整理工作包括收集、组织和维护来自不同来源的数据集,以确保其对研究人员和开发者的可用性。理解数据集之间的各种关系,有助于整理人员更好地管理数据集,包括版本控制、数据集合并、差异追踪等。
4. 识别数据集关系的方法
为了实现对数据集关系的有效识别,作者提出了四种方法来分析和识别这些关系:
- 语义标记分析(Semantic Markup Analysis):使用schema.org等现有的结构化语义标记来识别数据集之间的关系。这种方法依赖于数据集发布者在数据集网页上标记的元数据,但通常这些标记不完整或不准确,因此识别效果有限。
- 启发式方法(Heuristics-Based Methods):基于对大量数据集元数据的分析,提出了一些基于规则的启发式方法,例如通过正则表达式匹配数据集名称、描述中的相似之处来推断数据集之间的关系。这种方法虽然在一定程度上有效,但在面对数据集名称或描述不一致的情况下容易失效。
- 基于梯度提升决策树的多类分类器(Gradient Boosted Decision Trees, GBDT):利用人工标注的样本数据,训练一个梯度提升决策树分类器来识别数据集之间的关系。这种方法能够有效处理数据的复杂性和多样性,在实验中表现出了较高的准确性。
- 基于大语言模型(Large Language Model, LLM)的分类器:基于T5模型的分类器用于识别数据集之间的关系,尤其是在处理复杂的派生关系时表现优异。作者通过对模型进行微调,使其能够进行多类分类,从而更好地理解和推断数据集之间的复杂关系。
5. 研究结果与发现
研究结果表明,schema.org等语义标记在实际使用中极不完整,无法有效地识别数据集之间的关系。在2,178对人工标注的数据集对中,几乎没有数据集通过语义标记明确其与其他数据集的关系。而启发式方法虽然在特定类型关系上有效(例如副本关系和版本关系),但在其他关系类型上表现出较低的召回率。
相比之下,基于GBDT的分类器和基于T5的大语言模型分类器在整体准确率上表现更好,特别是在识别较复杂的派生关系时,T5模型具有更高的F1得分。
通过对270万个网络数据集的分析,研究发现约20%的数据集至少与其他数据集存在一种关系,而这些关系大部分是副本关系和子集关系。此外,研究还发现,数据集的副本通常分布在不同网站上,而子集、版本和派生数据集大多在同一平台发布。
6. 讨论与未来工作
论文在讨论中强调了理解数据集关系的复杂性以及数据集之间关系识别的重要性。作者提出,现有的schema.org等语义标记标准在捕捉数据集关系方面存在诸多不足,建议改进这些标准,并呼吁研究社区制定更好的数据共享实践以鼓励数据集发布者提供完整的元数据信息,例如发布具有持久标识符的数据集,并在元数据中明确数据集的来源和版本。
在未来工作中,作者计划扩展对数据集关系的研究,包括研究不同元数据字段对关系推断的影响,以及进一步探索非基于来源的关系,如主题相似性、任务相似性等。此外,作者还提到,理解这些关系的过程将有助于用户找到可靠的数据源,并发现信息空白,从而推动科学研究和知识发现的发展。
Google Dataset Search: https://datasetsearch.research.google.com/