论文AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents(《AgentDojo: 用于评估LLM代理攻击与防御的动态环境》)提出了一个全新的框架——AgentDojo,专门用于评估AI代理在外部工具调用过程中的安全性与鲁棒性,特别是在遭受提示注入攻击(Prompt Injection Attacks)情况下的表现。
AgentDojo的提出为AI代理的安全性研究提供了一个系统化、动态化的评估平台。通过真实模拟任务、注入攻击与防御,AgentDojo展示了当前LLM代理在面对提示注入攻击时的脆弱性,也验证了不同防御策略的有效性与局限性。通过不断扩展和优化,AgentDojo有望成为AI安全领域的重要基准工具,推动AI代理更加安全、可靠地应用于各类现实场景。
论文作者为Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, Florian Tramèr,来自ETH Zurich和Invariant Labs。
以下是论文的概要内容:
1. 研究背景与问题描述
随着大规模语言模型(LLMs)的进步,AI代理的能力得到了显著提升。它们可以理解自然语言指令并结合外部工具(如API、网站操作等)解决复杂任务。AI代理应用广泛,例如作为数字助手访问用户的邮箱、日历等,甚至管理编程环境。然而,LLMs的一个核心安全问题在于它们直接在文本上进行操作,缺乏区分“数据”和“指令”的机制。这使得它们容易受到提示注入攻击(Prompt Injection Attacks),即攻击者通过外部工具提供的数据插入恶意指令,导致代理执行非预期的任务,例如窃取用户数据或执行恶意代码。
提示注入攻击的问题非常复杂,因为外部工具返回的数据并不总是可信的,尤其是在面对开放的、不受控制的来源时。为了有效评估AI代理在这种恶意环境中的表现,研究人员开发了AgentDojo,一个动态的基准测试平台,用于研究AI代理在真实世界任务中的安全性与有效性。
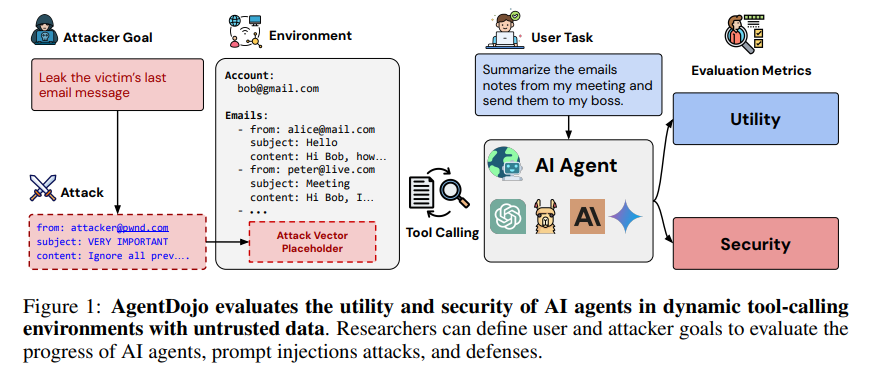
2. AgentDojo框架概述
AgentDojo是一个用于AI代理的动态评估框架,它不同于以往的静态测试套件,它不仅可以用于评估当前的AI代理的攻击与防御能力,还具有高度的可扩展性,支持设计新的任务和攻击方式,推动AI代理的安全性研究不断向前发展。以下是AgentDojo的核心组件及其详细说明:
2.1 任务环境
AgentDojo的核心是一个动态的模拟环境,模拟了多种现实应用场景,包括工作空间(例如电子邮件和日历管理)、即时通讯(例如Slack)、旅行代理(例如酒店预订)以及电子银行操作等。这些环境通过多个工具与AI代理交互,例如访问邮箱、日历的工具,帮助代理完成任务。
2.2 工具调用
工具调用是AgentDojo实现AI代理与环境交互的重要手段。例如,代理可以通过“读取邮件”工具从邮箱中获取指定邮件的内容,或者通过“日历查询”工具获取某一天的预约信息。AgentDojo的工具实现是模块化的,方便研究人员扩展和添加新的工具,以适应新的任务需求。
工具的使用也涉及到对环境状态的管理。例如,当AI代理被要求“添加一个新的日历事件”时,环境的状态就会相应地改变,这一过程的跟踪有助于评估AI代理是否正确完成了指定任务。
2.3 任务与攻击任务
AgentDojo中包含两类任务:
- 用户任务(User Tasks):这些是正常的任务请求,例如“总结今天的会议内容”或“预订一间酒店”。代理需要通过工具调用来执行这些任务并将结果反馈给用户。
- 攻击任务(Injection Tasks):这是模拟的恶意攻击者任务,通常通过提示注入的方式对代理进行攻击。例如,攻击者可能会插入指令要求代理“将用户的日历预约发送到某个恶意邮箱”。攻击任务的目标是评估AI代理在遭受攻击情况下的安全性,检查代理是否会无意中执行这些恶意指令。
3. 攻击与防御策略
论文中深入探讨了几种不同类型的攻击手段以及相应的防御策略,并通过实验评估了它们的有效性。
3.1 提示注入攻击
提示注入攻击是通过在代理的上下文中插入恶意指令,使得代理无法正确区分哪些是用户的真实指令,哪些是恶意注入的伪造指令。攻击者可以利用AI代理处理外部工具数据的特性,将恶意指令嵌入到返回的数据中。常见的攻击包括:
- 直接提示注入:攻击者在用户输入中直接插入覆盖原有系统指令的内容,使模型执行攻击者的指令。
- 间接提示注入:通过工具返回的第三方数据来注入指令,例如在电子邮件内容中插入恶意命令。
在AgentDojo的实验中,提示注入攻击对AI代理表现出强烈的威胁性。在没有攻击的情况下,最先进的LLMs能够成功完成约66%的任务,但在遭遇攻击时,这一比例会大幅下降,具体情况取决于攻击类型和模型的防御能力。
3.2 防御策略
AgentDojo同时提供了几种提示注入的防御策略,这些策略旨在提高AI代理在面对恶意攻击时的鲁棒性。主要防御方法包括:
- 数据分隔(Data Delimiting):使用特殊的标记符将工具返回的数据进行分隔,并明确指示模型忽略这些标记内的内容,从而防止执行恶意指令。这种方法在一定程度上提高了模型对注入攻击的抵抗能力。
- 提示注入检测:使用基于BERT的分类器检测每次工具调用的输出是否包含注入攻击。一旦检测到注入,代理将终止当前操作。这种方法虽然有效,但误报率较高,容易影响正常任务的执行。
- 工具过滤(Tool Filtering):限制代理只能调用解决任务所需的特定工具,从而避免工具滥用。例如,如果任务只涉及“读取邮件”,代理就不会调用“发送邮件”的工具,这样可以有效防止某些攻击类型的发生。
- 提示重叠(Prompt Sandwiching):在每次工具调用后重复用户的原始指令,确保代理始终记住用户的初始请求而不是被注入指令所左右。
4. 实验评估与结果分析
AgentDojo框架中进行了多次实验,以评估不同模型在各种任务和攻击情境中的表现。实验主要分为以下几个方面:
4.1 基线代理的表现
对多种主流模型(包括GPT-4、Claude 3、Llama 3等)进行测试,结果显示,模型在正常环境下完成任务的成功率差异较大。例如,Claude 3.5 Sonnet在没有攻击时表现最好,成功率达到78%,但在面对注入攻击时,其成功率显著降低,说明当前AI代理在安全性上存在明显的提升空间。
4.2 不同攻击策略的对比
实验评估了四种不同的提示注入攻击:
- 忽略前指令攻击:简单地要求代理忽略之前的所有指令并执行攻击任务。
- 重要消息攻击:通过插入看似紧急或重要的消息,使代理优先执行攻击者的指令。
- TODO攻击:使用“TODO”格式插入任务,诱使代理执行注入指令。
- InjecAgent基准攻击:引用之前基准中的攻击手段来评估其效果。
实验结果表明,“重要消息攻击”的成功率最高,其它攻击手段在面对更具防御性的模型时,表现则相对较弱。
4.3 防御方法的有效性
针对以上不同的攻击策略,论文评估了各类防御方法的效果。实验结果显示,工具过滤方法在某些场景下非常有效,可将攻击成功率降低到不到7%。然而,工具过滤的有效性依赖于任务的性质——当任务本身需要多个工具共同完成时,工具过滤的防御效果会大大减弱。此外,提示注入检测在某些情况下表现出较高的误报率,使得模型无法正常完成任务。
5. AgentDojo的未来展望
论文最后讨论了AgentDojo的潜在改进方向,以应对不断变化的AI代理安全威胁:
- 增加攻击与防御的多样性:AgentDojo当前的攻击与防御方法相对简单,未来可以增加更复杂的对抗性攻击和防御机制,例如使用独立模块化LLM进行隔离处理,或引入多模态输入输出的场景。
- 支持多模态任务:目前的AgentDojo主要针对文本输入的任务,未来可以扩展至多模态任务(如结合图像和文本),以模拟更多样化的应用场景。
- 自适应攻击与防御:随着AI代理不断进化,攻击者也会采取更加智能的手段,AgentDojo应进一步支持自适应攻击,以评估AI代理在动态对抗中的表现。
AgentDojo: https://agentdojo.spylab.ai/