论文Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence(《Model Swarms:通过群体智能对LLM专家进行协作搜索适应》)提出了一种新颖的群体智能协作搜索算法来优化和适应大语言模型(LLM)专家群体。该方法基于粒子群优化(PSO)的思想,将多个LLM专家视为“粒子”,在权重空间中进行协作搜索,以找到适合不同任务或领域的最佳模型组合。
论文作者为Shangbin Feng, Zifeng Wang, Yike Wang, Sayna Ebrahimi, Hamid Palangi, Lesly Miculicich, Achin Kulshrestha, Nathalie Rauschmayr, Yejin Choi, Yulia Tsvetkov, Chen-Yu Lee, Tomas Pfister,来自University of Washington和Google。
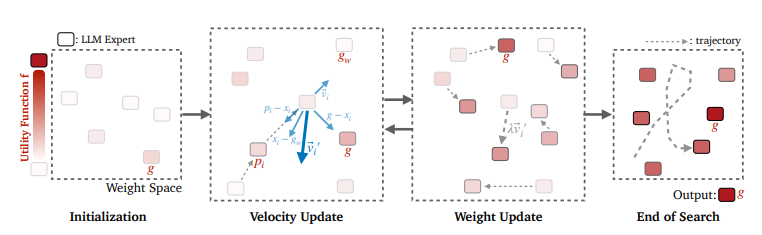
如下为论文概要内容:
一、论文背景与动机
目前的研究倾向于开发大规模的通用型语言模型(如GPT-3),这种模型通常通过共享参数来应对所有语言和任务。然而,通用模型面临的挑战是其在特定任务和领域中表现的局限性,尤其是在数据量较少的情况下。因此,近年来的研究逐渐转向模块化的多模型协作,即多个专家模型相互交互与补充,以发挥各自的特长。这种方法包括专家混合(Mixture-of-Experts,MoE)等方法,通过不同领域专家的合作来提高任务的处理能力,但这些方法通常在模型组成方式上有很强的假设和限制,缺乏灵活性,尤其是当面对未知领域或复杂任务时。
为了解决这些挑战,论文提出了一种新的协作搜索算法——Model Swarms,该算法基于群体智能,通过在权重空间中的协作搜索实现模型的适应与优化。Model Swarms 的目标是通过灵活组合多个LLM(大语言模型)专家,使它们能适应多样化的任务和用户需求,特别是在低数据量的场景下。
二、Model Swarms 的核心思想与机制
1. 群体智能与粒子群优化(PSO)的启发
Model Swarms 的设计灵感来源于群体智能,尤其是粒子群优化(Particle Swarm Optimization, PSO)。PSO是一种基于自然界群体行为的优化算法,如鸟群觅食、鱼群游动等。PSO中,所有粒子(即候选解)在多维空间中协作寻找最优解,每个粒子根据自身和群体的经验调整自己的位置,以此达到全局优化。
在 Model Swarms 中,多个LLM专家被视为群体中的粒子,每个粒子都有自己的“位置”(模型权重)和“速度”(在权重空间中的移动方向)。这些专家模型通过协作调整其权重和参数,最终优化一个效用函数,该效用函数可以代表任务的具体目标,如模型的准确率或对特定用户偏好的适应性。
2. 算法的基本流程
(1)初始群体构建
Model Swarms 开始时需要一个初始的LLM专家群体,这些专家可以是完整的预训练模型或者通过LoRA(低秩适配器)在不同任务上微调过的模型。初始专家群体通过两两插值(pairwise interpolation)扩展为更大的模型集合,以增加搜索过程中的多样性和探索能力。具体地说,通过随机选择两个专家并对其权重进行线性组合来生成新的初始模型,使得搜索过程从更多样化的起点开始。
(2)速度和位置更新
每个粒子模型的移动由其速度决定,而速度的更新受到三个因素的影响:
- 惯性项:保持粒子当前的速度,确保其沿既定方向前进,探索未知区域。
- 个体最优(Personal Best, p_i):每个粒子根据其搜索历史中发现的最佳位置进行调整,朝向历史最佳的位置移动,以进一步探索有前景的区域。
- 全局最优(Global Best, g)和全局最差(Global Worst, g_w):粒子也会受到群体整体最优位置的吸引和最差位置的排斥,从而促进探索有潜力的区域并远离劣质模型。
速度的更新公式为:

(3)权重更新
根据更新后的速度,粒子的权重通过以下方式更新:
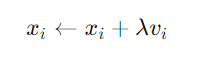
其中,λ是步长参数,控制每次移动的幅度。在每次迭代中,模型根据效用函数f的值来更新全局和个人最优的位置。如果某个粒子在连续若干次迭代中未能找到更优的位置,则该粒子会被“重启”回其个人最佳位置,并将速度设为0,给予其新的探索机会。
(4)协作搜索终止条件
协作搜索在满足以下条件之一时终止:
- 全局最优位置在 c 次迭代中未发生变化。
- 达到最大迭代次数 K。
搜索结束时,全局最优的模型位置被作为最终的输出。
三、实验设置与结果分析
论文的实验涵盖了四种类型的LLM适应任务:单任务适应、多任务领域适应、奖励模型优化、以及人类兴趣适应。
1. 单任务适应
在单任务适应中,Model Swarms 被应用于9个数据集,包括知识类(如MMLU)、推理类(如GSM8k)以及安全性类任务(如TruthfulQA)。实验结果表明,Model Swarms相较于12个基准方法,平均性能提升了13.3%,尤其是在推理任务上,表现提升达到了21.0%。这表明该方法在推理密集型的任务中有显著的优势,可能因为协作搜索增强了专家模型在复杂逻辑推理上的泛化能力。
2. 多任务领域适应
在多任务领域适应中,Model Swarms 被用于同时优化医疗、法律、科学和文化等领域中的多个任务。结果显示,在所有测试任务中,Model Swarms 的平均性能提升了5.7%,特别是在法律领域,表现提升最为显著(分别达到了11.3%和10.5%)。这表明模型群体协作能够有效处理包含多种任务的复杂领域,并且在同一个领域中,模型的协作适应通常优于仅针对单个任务的适应。
3. 奖励模型优化
Model Swarms 还被应用于优化奖励模型,目标是使模型适应一般性和对立性偏好,例如长篇详细描述与简洁明了的回答之间的冲突。实验中,Model Swarms 相较于包括PPO和DPO在内的14个基准方法,在低数据情景(仅200个示例)下,性能平均提升了6.7%。尤其是对多样化用户偏好的适应,Model Swarms 展现了卓越的灵活性。
4. 人类兴趣适应
在16个人类兴趣领域中,Model Swarms 的优化使得模型在“LLM-as-a-judge”评分中提升了17.6%,在事实性验证上提升了17.0%,并且在人类评估中取得了70.8%的胜率。这表明,Model Swarms能够显著提高模型对特定领域和特定社区兴趣的适应性,生成更加符合人类期望的输出。
四、深入分析与讨论
1. 正确性的新兴能力
为了评估LLM专家是否在协作搜索过程中学到了新的技能,论文定义了四个正确性等级,并引入了“正确性提升”(C-surge)和“正确性新兴”(C-emerge)两个指标。实验表明,Model Swarms 在四个数据集上的平均C-surge为48.2%,C-emerge为36.0%到53.5%。这意味着,通过协作搜索,LLM专家群体能够解决先前被视为“无法解决”的问题,从而展现出新兴的能力。
2. 弱到强的转变
在协作搜索过程中,实验发现并非所有最优的最终专家在初始时就是最佳的。相反,很多起初表现较差的专家通过协作转变成了最优的专家,这种现象被称为“从弱到强的转变”。论文的实验数据显示,在最终表现最优的专家中,只有10.4%最初排名第一,而56.9%的专家原本位于群体的下半部分。这证明Model Swarms能够有效激发弱模型的潜在能力,使其通过协作获得最佳表现。
3. 多样性对群体协作的影响
多样性在 Model Swarms 的成功中起着至关重要的作用。实验通过控制初始专家的数量和多样性,发现多样性越高的专家群体,其协作搜索的效果越好,性能平均提升了35.3%。这表明,拥有多样化的专家能够提供更广泛的探索空间,促进模型在适应任务时获得更优的表现。
4. 令弱者胜于强者的协作
论文还探讨了如果仅使用初始模型中的弱专家(而非最优专家),它们是否能够通过协作超过最优专家的表现。结果表明,通过协作,弱专家群体的表现可以优于最强的单个专家,这在平均性能上提升了35.4%。这进一步证实了群体智能的强大适应能力,通过协作实现专家的“弱变强”过程。
五、方法的加速与优化
为了减少搜索过程中的计算开销,论文提出了Drop-K和Drop-N两种类似dropout的加速方法,分别是随机跳过某些迭代中的模型评估或随机跳过某些专家的评估。实验表明,通过这两种加速方法,搜索的计算量最多可以减少80%,而性能仅下降6.0%,这为未来更高效的模型协作提供了可能性。
六、与现有工作的对比
论文对比了Model Swarms与现有模型组合方法的区别与优势:
- 与专家混合(MoE)方法相比,Model Swarms 不需要对专家的组合方式进行假设,而是通过协作搜索动态适应。
- 与进化算法(如遗传算法)不同,Model Swarms 不需要复杂的手工设计规则,而是通过群体智能中的简化策略进行优化。
- 与静态模型算术组合方法不同,Model Swarms 通过效用函数动态调整模型的组合方式,具有更高的适应性。
七、结论与未来展望
Model Swarms 提供了一种基于群体智能的灵活适应和优化大语言模型的框架。它通过协作搜索的方式,无需进行大量的调优,便能在低数据量的场景中实现对任务的有效适应。实验结果证明,Model Swarms 能够超越现有的多种模型组合方法,尤其在复杂任务和多样化需求的场景中表现出卓越的性能。
未来挑战与改进方向包括:
- 多样化专家选择的挑战:如何在众多公开模型中选择最合适的专家群体是一个具有挑战性的任务。
- 计算开销与加速优化:协作搜索的计算成本较高,如何在保证性能的同时进一步降低计算复杂度是未来的重要研究方向。
- 权重群体与Token群体的适应性:权重群体能够更深层次地改变模型的能力,但需要共享架构,而Token群体具有更高的灵活性,如何在这两者之间找到平衡将是未来的重要课题。