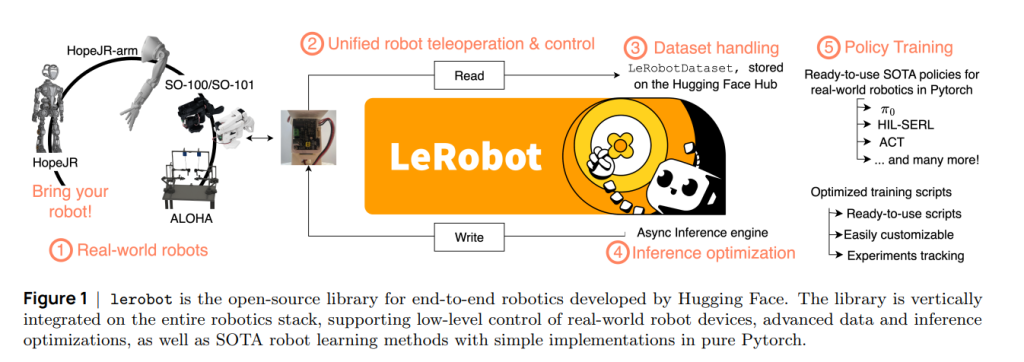
包含数据/模型/工程三位一体内容的机器人学习(Robot Learning)教程
Robot Learning: A Tutorial是一篇面向研究者与实践者的“机器人学习”教程型综述,主张在...
Read More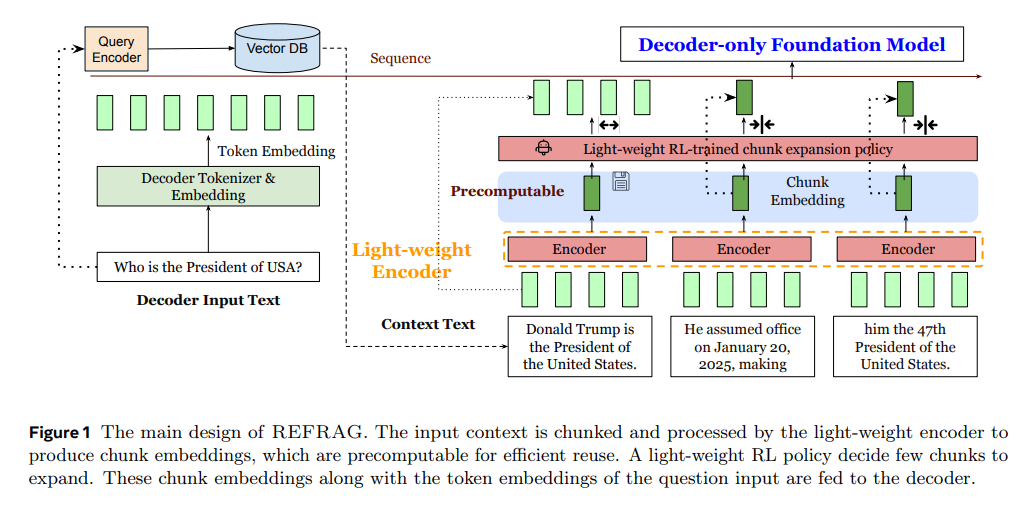
REFRAG (REpresentation For RAG) :解决RAG处理大量外部知识时遇到的速度慢和内存占用大问题
论文REFRAG: Rethinking RAG based Decoding介绍了一种名为 REFRAG (...
Read More
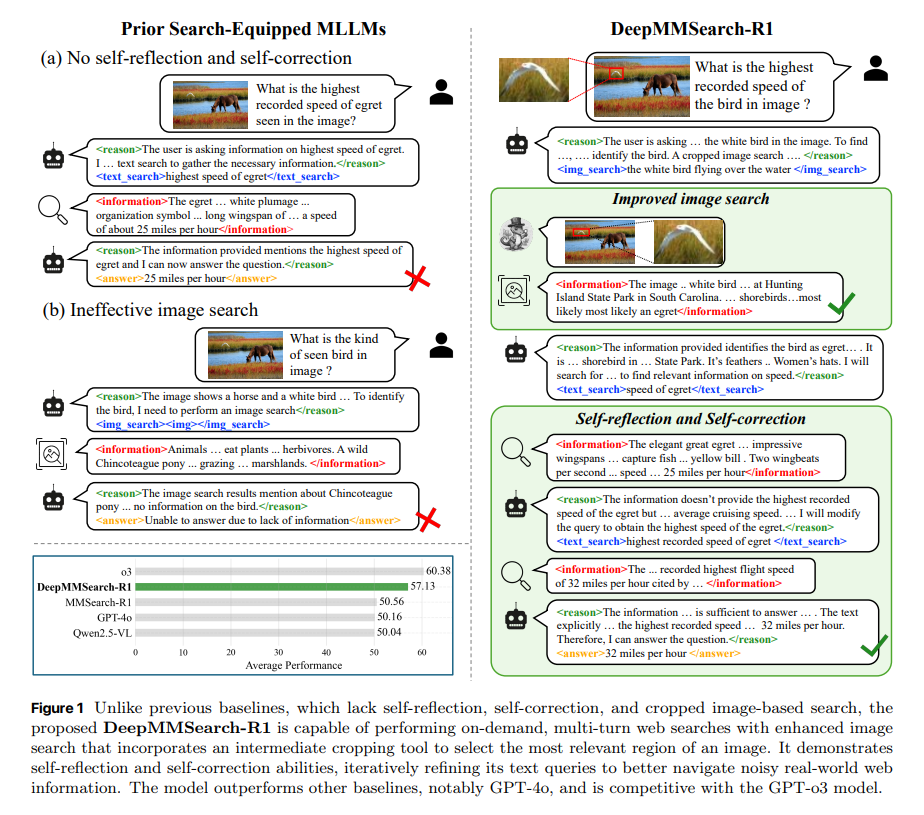
DeepMMSearch-R1:通过“多工具、多轮交互”检索增强推理循环,实现面向真实网页的多模态检索/推理一体化
现实应用中的多模态大模型(MLLM)在知识密集与信息检索型视觉问答任务上常受限于静态训练语料与长尾知识分布,难...
Read More
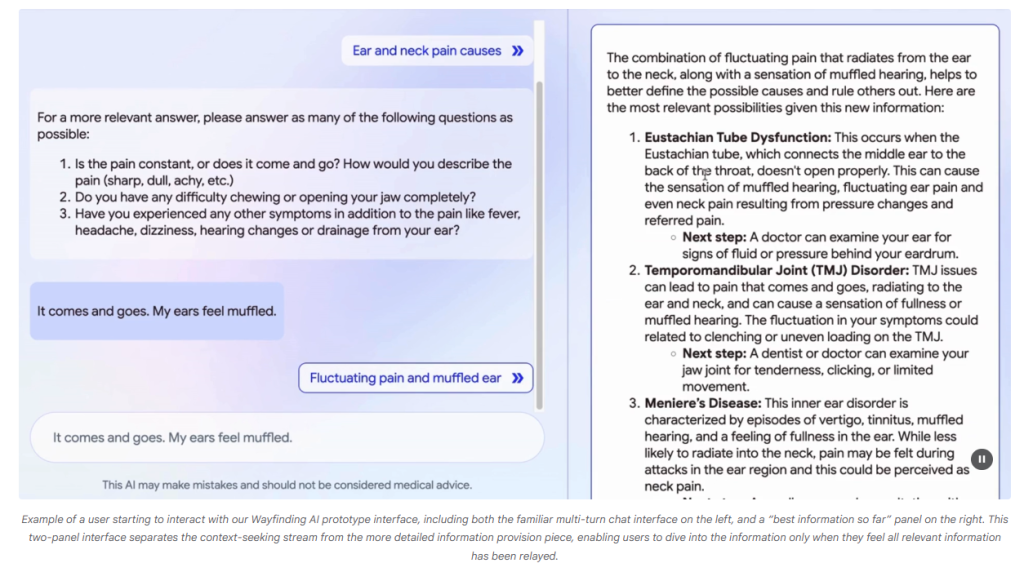
寻路型AI(Wayfinding AI):打造“更像医生”的健康对话系统
现代人获取健康信息的入口极多,但也伴随低质信息、理解偏差与焦虑等风险。大型语言模型(LLMs)虽然在医学知识与...
Read More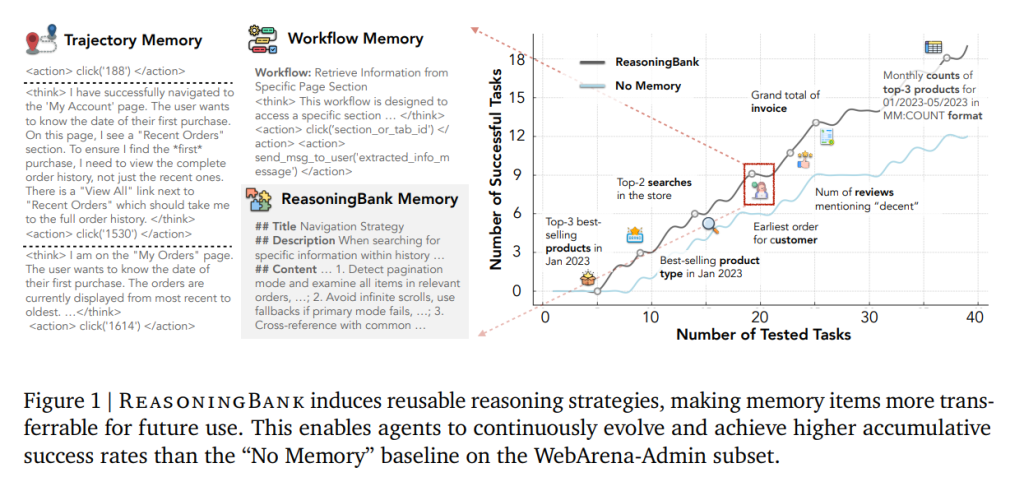
ReasoningBank:构建“面向推理的记忆”机制,使智能体实现自主进化能力
大型语言模型(LLM)驱动的智能体正被用于长期、持续的真实世界任务(如网页浏览、软件工程自动化),但主流智能体...
Read More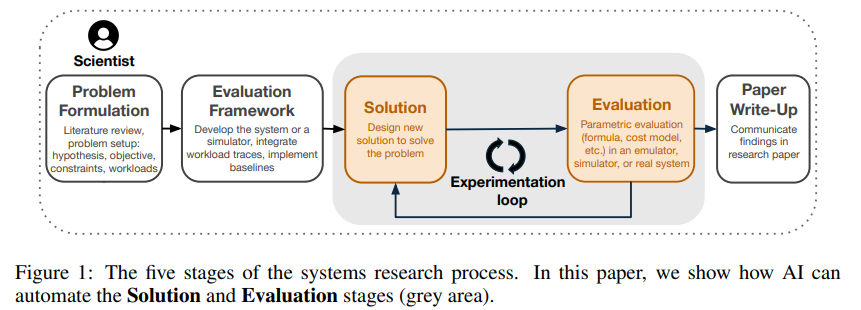
ADRS(AI-Driven Research for Systems):AI驱动下算法自动进化的系统研究新范式
论文Barbarians at the Gate: How AI is Upending Systems Re...
Read MoreAgentic Design Patterns(《智能体设计模式》)
Agentic Design Patterns(《智能体设计模式》),作者:Antonio Gulli 目录...
Read More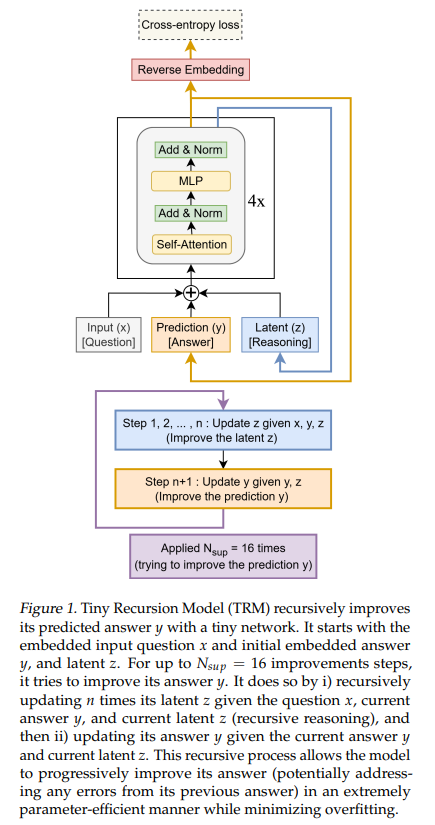
7M参数小模型(Tiny Recursive Model,TRM),在数独、迷宫、ARC-AGI 等“硬推理”任务上表现优于大参数LLM
论文Less is More: Recursive Reasoning with Tiny Networks针...
Read More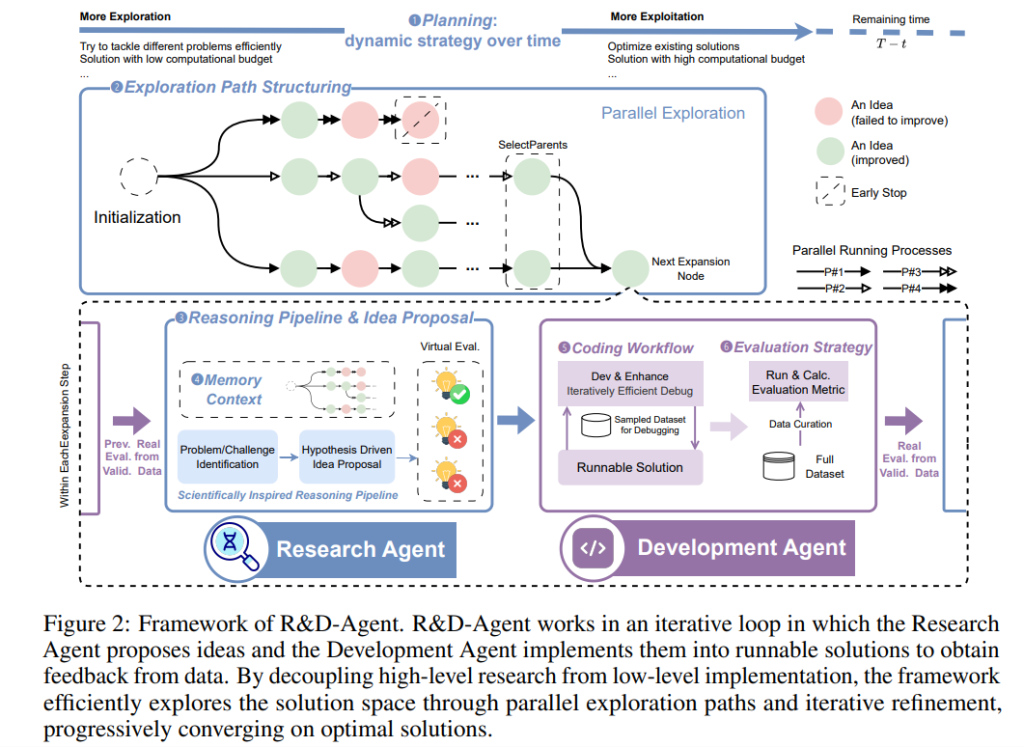
R&D-Agent:系统化、可扩展、解耦合的MLE(Machine Learning Engineering,机器学习工程)智能体架构
随着人工智能(AI)和机器学习(ML)的迅猛发展,数据科学领域取得了显著进展,广泛应用于机器翻译、推荐系统、社...
Read More
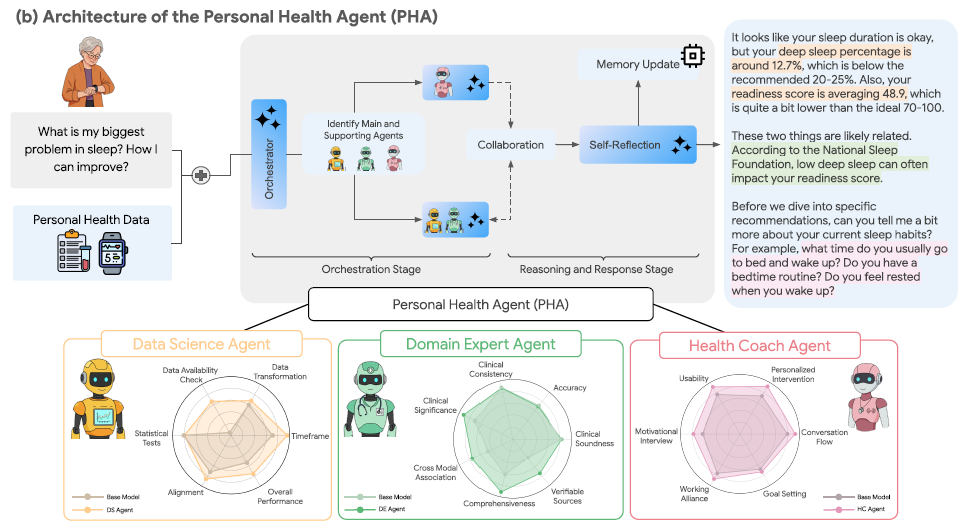
Personal Health Agent(PHA):面向个人健康的多智能体框架,数据科学、领域专家、健康教练三种智能体协同
个人健康与日常福祉高度相关,但传统“单体式”对话大模型在面对真实用户的多样化健康诉求(数据解读、医学知识查证、...
Read More