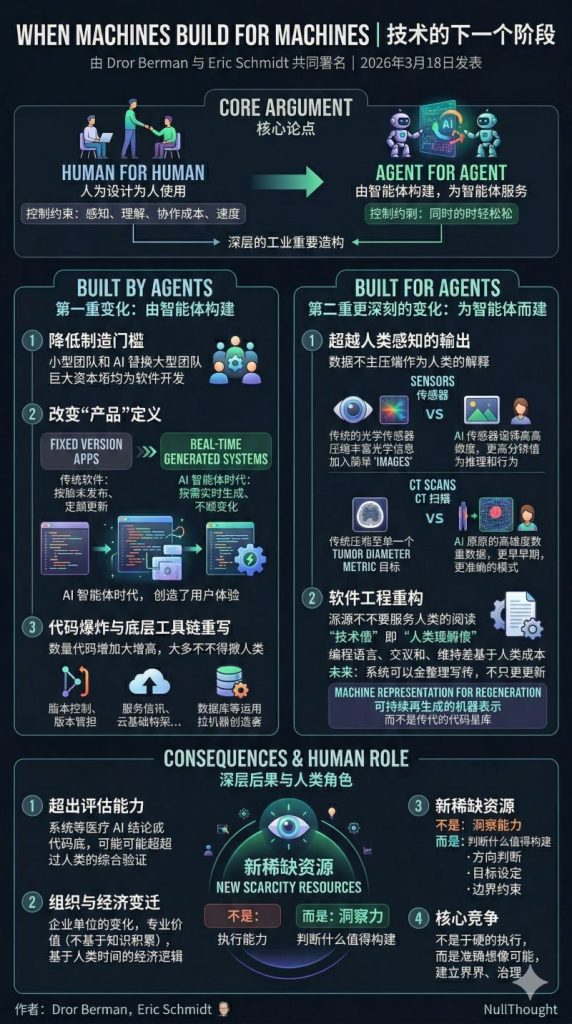
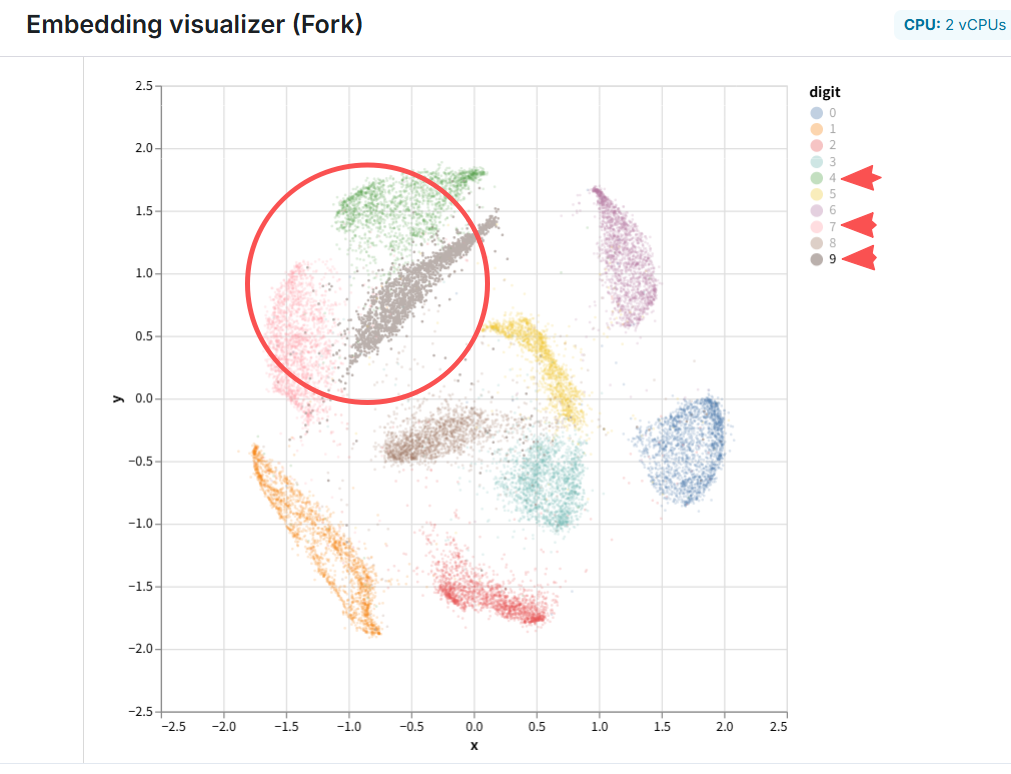
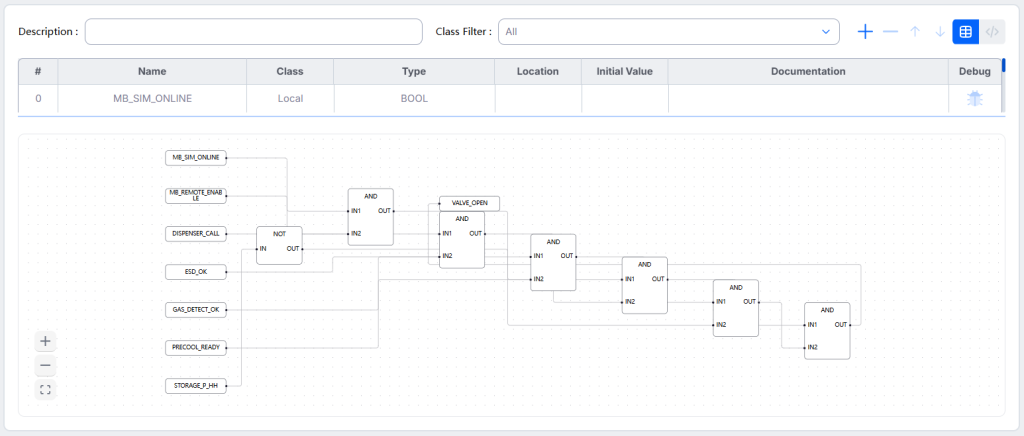
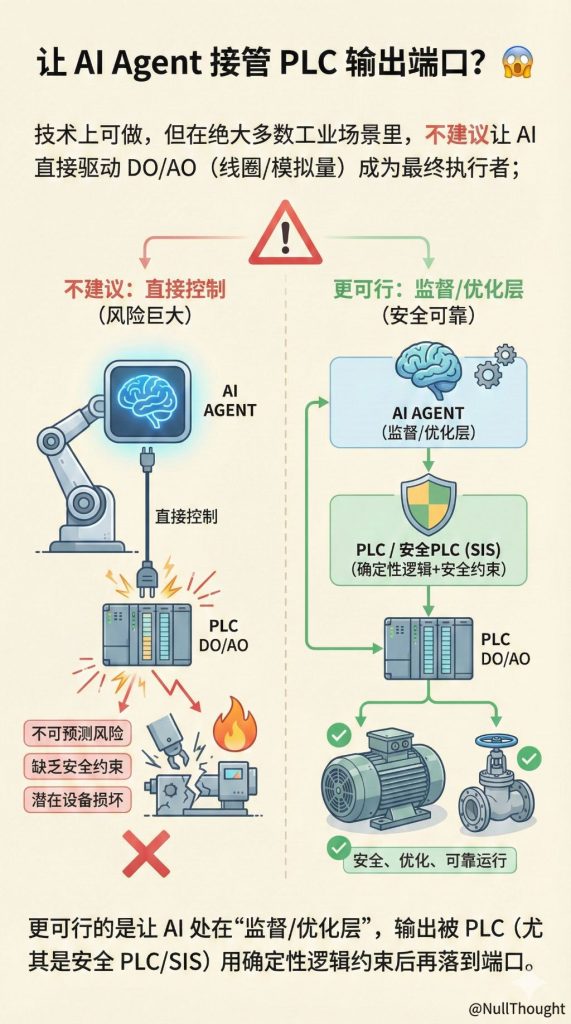
人工智能AI 用AI进行高效数据分析2026-04-18NullThoughtTechAI,AI时代老码农,ChatGPT喂给ChatGPT 80万条实验数据,很快给出分析结论,耗时4m33s。 相关文章: 面向ChatGPT编程...Read MoreVoMP:预测3D物体的物理属性(杨氏模量、泊松比和密度)2026-04-13NullThoughtTechAI,NVIDIA,物理论文VoMP: Predicting Volumetric Mechanical Property Field...Read MoreGoogle发布Gemma 42026-04-03NullThoughtTechAI,大语言模型LLM,谷歌Google 于 2026 年 4 月 2 日发布 Gemma 4 。Gemma 4 定位为“按参数规模衡量,...Read MoreAI时代软件公司,不卖工具,直接卖服务结果2026-04-02NullThoughtTechAI,代理型AI/Agentic AI/AI代理/AI智能体/AI Agent,经济红杉资本合伙人Julien Bek在X上发帖文 Services: The New Software,该文内容...Read More范式改变:当生产端和消费端都是智能体2026-04-01NullThoughtTechAI,代理型AI/Agentic AI/AI代理/AI智能体/AI Agent,经济文章 When Machines Build for Machines 由 Dror Berman 与 Eri...Read MoreAI与数字孪生的融合2026-03-06NullThoughtTechAI,制造,工程,物联网Siemens Industry 于 2026 年 3 月 5 日发布的文章 AI and the Digit...Read More针对军事AI,Anthropic与白宫的正面冲突2026-02-28NullThoughtTechAI,military,政治,财经这些天,Anthropic与白宫针对军事AI发生了正面冲突。这次事件的本质,不是“Anthropic 反对美国...Read MoreMapTrace:让AI读懂地图的几何与拓扑关系2026-02-21NullThoughtTechAI,谷歌Google Research 的最新研究成果 MapTrace 解决一个看似“人类直觉”的能力:读懂一张地图...Read MoreDeepRare:智能体式罕见病循证推理诊断系统2026-02-21NullThoughtTechAI,代理型AI/Agentic AI/AI代理/AI智能体/AI Agent,医疗/生物医药,大语言模型LLM论文An agentic system for rare disease diagnosis with tra...Read MoreConformer-PhyFaultNet:滚动轴承故障诊断的泛化尝试2026-02-21NullThoughtTechAI,AI模型泛化,物理,物联网论文 Conformer-PhyFaultNet: Physics-Informed Spectral Att...Read MoreSpaceX轨道数据中心申请2026-02-14NullThoughtTechAI,spacex,宇航文件APPLICATION FOR LAUNCH AND OPERATING AUTHORITY FOR TH...Read More让大模型忘掉部分内容2026-02-13NullThoughtTechAI,大语言模型LLM,微软论文Who’s Harry Potter? Approximate Unlearning in L...Read More让大语言模型当“裁判”评判“共情(empathic)”2026-02-13NullThoughtTechAI,大语言模型LLM论文When large language models are reliable for judging e...Read More一个Embedding visualizer demo2026-02-12NullThoughtTechAI,AI时代老码农marimo上的一个Embedding visualizer(嵌入可视化) demo,演示手写数字识别的嵌入空...Read More用Codex实现设备控制叙述(Control Narrative)到PLC控制逻辑FBD(Functional Block Diagram,功能块图)2026-02-11NullThoughtTechAI,AI时代老码农,OpenAI,工程,物联网,电子电气Implementing the conversion from equipment Control Narr...Read More让 AI Agent 接管 PLC 输出端口?😱2026-02-09NullThoughtTechAI,代理型AI/Agentic AI/AI代理/AI智能体/AI Agent,制造,物联网技术上可做,但在绝大多数工业场景里,不建议让 AI 直接驱动 DO/AO(线圈/模拟量)成为最终执行者;更可行...Read More‹123456›»