论文Let Your Graph Do the Talking: Encoding Structured Data for LLMs提出的GraphToken方法通过参数高效的图数据编码方式,在LLMs中实现了显著的图推理(graph reasoning)能力提升。GraphToken不仅能够提高图推理任务的准确性,还能够在不增加大量计算成本的情况下,充分利用图的结构信息。实验结果表明,GraphToken在多个图推理任务上的表现超过了现有的其他方法,展示了其在结构化数据处理上的巨大潜力。
论文作者为Bryan Perozzi, Bahare Fatemi, Dustin Zelle, Anton Tsitsulin, Mehran Kazemi, Rami Al-Rfou, Jonathan Halcrow,来自Google Research和Waymo Research。
一、研究背景与问题陈述
近年来,随着大型语言模型(LLMs)在文本数据处理上的成功应用,研究者们逐渐关注如何将更复杂的结构化数据(例如图数据)引入到这些模型中。这一问题的关键在于如何将图结构信息有效地表示为LLMs可以处理的输入形式。结构化数据在现实生活中广泛存在,例如社交网络、分子结构、关系数据库等都包含了节点之间复杂的关系和依赖。将这些数据传递给LLMs通常需要将其序列化为文本,这种方法往往面临着信息解码复杂、推理效果差的问题。
目前,已有一些研究尝试将结构化数据编码为文本序列并输入LLMs,但这种方法存在一定的局限性。首先,文本化的结构化数据必须经过LLM解码,才能有效参与推理,这使得模型在理解和利用结构化数据时的效率较低。其次,现有方法在处理图结构推理任务时表现不佳,LLMs难以直接利用图数据中的结构信息。
针对这些问题,本文提出了GraphToken,一种参数高效的图数据编码方法,旨在通过图神经网络(GNN)生成图令牌(graph tokens),并将其作为LLM输入提示,从而显著提高LLM在图推理任务中的表现。与传统的图文本化编码方法不同,GraphToken方法直接生成图的连续表示,并通过参数高效的方式将其嵌入LLM的提示空间。此方法不仅提高了图推理能力,还减少了计算开销。
二、研究方法
- GraphToken方法概述
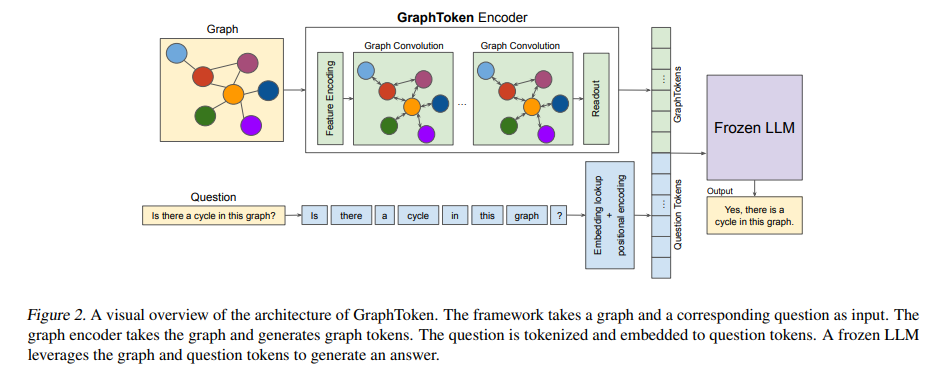
GraphToken是一种基于GNN的编码方法,通过将图结构信息转换为图令牌,以便LLMs能够更好地处理和推理这些数据。与传统的图序列化方法不同,GraphToken直接将图结构编码为连续的表示形式,而非将其转化为文本形式。这种方法通过在GNN中学习图的嵌入表示,生成能够与LLM兼容的输入提示,从而避免了传统方法中由于文本化结构所带来的复杂性。
GraphToken的主要优势在于其高效的参数使用。该方法并不直接训练LLM的所有参数,而是通过冻结LLM的参数,只训练图编码器的少量参数。这种设计使得GraphToken在减少计算资源需求的同时,依然能够显著提高图推理任务的性能。
- 模型架构
GraphToken模型由两个主要部分组成:- 图编码器:图编码器利用GNN对图结构进行编码,将其转化为向量表示。这些表示捕捉了图中的结构信息,并通过池化操作得到一个固定维度的表示。图编码器将图的节点、边以及图的全局特征通过GNN的不同变体进行处理,并生成图令牌。不同的任务(如图级、节点级、边级任务)使用不同的池化策略进行特征汇聚。例如,在图级任务中,图令牌通过全局池化得到,而在节点级任务中,模型则输出每个节点的表示。
- 语言模型:LLM接收来自图编码器的图令牌和文本任务描述(例如:“该图是否包含环?”)作为输入,并利用其强大的语言理解能力进行推理。语言模型的参数在训练过程中保持冻结状态,只有图编码器的参数进行更新。
- 训练流程
GraphToken的训练流程与软提示方法类似。训练过程中,输入包括三元组(图G、任务描述T、答案A),其中图G是待处理的图结构,T是描述任务的文本(例如:“该图是否包含环?”),A是任务的答案(例如:“是的,该图包含环”)。在每次前向传播中,GraphToken首先将图G编码为图令牌,然后将任务描述T与图令牌E(G)结合,形成一个扩展的查询Q。LLM利用这个扩展查询进行推理,生成预测结果A。最终,模型通过最小化LLM对预测结果A的困惑度(perplexity),来优化图编码器的参数。
三、实验结果
- 主要实验结果
为了验证GraphToken的效果,本文使用了GraphQA基准数据集,对比了GraphToken与现有方法在多个图推理任务上的表现。实验结果表明,GraphToken在图级、节点级和边级任务上均显著优于其他方法。例如,在环检测任务中,GraphToken的准确率达到了95.6%,远超其他方法。
通过对比不同方法的实验结果,可以发现,GraphToken的优势在于其能够直接利用图的结构信息进行推理,而其他方法则往往依赖文本化的结构描述,导致推理效率较低。GraphToken在图推理任务上的表现提升高达73个百分点,尤其是在处理复杂图结构时表现尤为突出。
- 编码器设计研究
GraphToken的图编码器设计对任务的表现有显著影响。实验表明,不同的图卷积操作在不同任务上表现出不同的优势。具体而言:- 图卷积选择:本文测试了多种图卷积方法,包括图卷积网络(GCN)、消息传递神经网络(MPNN)、图同构网络(GIN)、多头注意力(MHA)等。实验结果显示,MHA和MPNN在许多任务中表现优异,尤其是在边计数和节点度数计算任务中。
- 特征选择:在图编码器中引入学习的节点特征(如Laplace位置编码和唯一身份编码)能显著提高模型性能。学习的特征可以打破GNN的等变性(equivariance),增强其在图推理任务中的表达能力。
- 参数使用
GraphToken的设计具有高度的参数效率。通过只训练图编码器的少量参数,而冻结LLM的参数,GraphToken能在保持高效性的同时,显著降低计算开销。实验结果表明,GraphToken的图编码器在不同模型中使用的参数量从17,000到199,000不等,远低于当前主流LLMs的数十亿级别参数。
四、讨论与未来方向
- 研究意义
GraphToken为结构化数据的LLM应用提供了新的解决方案,能够有效解决LLMs在处理图推理任务时的不足。通过直接对图进行编码,GraphToken避免了传统方法在文本化结构时面临的解码复杂性,从而提高了模型的推理效率。这一方法为未来LLMs在更多领域中的应用奠定了基础,特别是在图数据丰富的任务中,如知识图谱推理、社交网络分析等。 - 未来研究方向
未来可以进一步优化GraphToken的图卷积操作,以更好地支持不同类型的图推理任务。此外,研究者还可以探索GraphToken在其他领域的应用,如:- 事实验证:使用图编码器增强LLM对事实的验证能力,例如,基于知识图谱的事实查询与验证。
- 跨任务泛化能力:通过改进图卷积设计,提升模型在多个任务间的跨领域泛化能力。
- 反向应用:探讨如何利用LLM对GNN进行解释,提升图神经网络的可解释性和推理质量。