论文Extending Video Masked Autoencoders to 128 frames(《扩展视频掩码自动编码器至128帧》)研究了如何通过改进的视频掩码自动编码器(MAE)策略来增强视频理解的效果,尤其是在长视频(128帧)上的表现。论文提出了一种适应性解码器掩码策略,可以优先处理最重要的token,从而有效提升长视频的训练效率和性能。
论文作者为Nitesh Bharadwaj Gundavarapu, Luke Friedman, Raghav Goyal, Chaitra Hegde, Eirikur Agustsson, Sagar M. Waghmare, Mikhail Sirotenko, Ming-Hsuan Yang, Tobias Weyand, Boqing Gong, Leonid Sigal,均来自Google。
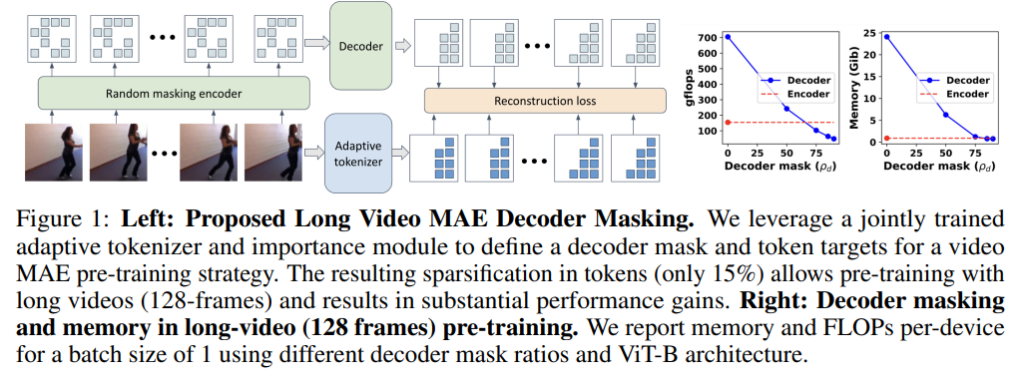
一、论文背景和技术挑战
近年来,视频理解取得了显著的进展,尤其是基于自监督学习的视频基础模型。掩码自动编码器(MAE)因其简单而有效的特性成为了视频理解中的重要工具。然而,大多数现有的MAE模型仅限于处理短视频片段,通常为16或32帧。这是由于现有硬件设备在内存和计算能力方面的限制,因为视频处理过程中,特别是自注意力机制带来的解码操作会导致内存需求呈现出二次方的增长,难以有效扩展到长视频。
具体而言,现有的MAE方法在处理长视频时面临以下几个主要挑战:
- 计算复杂度的增加:自注意力机制在编码和解码过程中对输入序列的所有token进行两两交互,这意味着输入视频的帧数越多,计算复杂度就呈指数级增长,导致对硬件计算能力和内存需求急剧增加。
- 内存瓶颈:长视频的自监督学习需要存储大量的中间特征表示,包括编码器的输出和解码器的输入,而这种高维数据会迅速耗尽硬件设备的内存资源,尤其是在高分辨率和长时间序列的视频任务中。
- token的重要性问题:视频中的每一个token(即视频的片段)对理解整体视频内容的重要性是不同的。现有方法大多采用随机或均匀的方式对视频片段进行掩码,这忽略了视频中不同区域的重要性差异。
二、研究目标
本文的目标是提出一种新的掩码策略,使得掩码自动编码器(MAE)能够有效地应用于长视频(如128帧)的预训练,提升长视频编码器的性能。在此过程中,本文提出了一种适应性解码器掩码策略,结合基于MAGVIT的tokenizer来学习token的重要性,优先选择重要token进行重建,从而降低计算复杂度和内存需求。
三、方法详解
1. 掩码自动编码器(MAE)及其工作机制
掩码自动编码器(MAE)是一种基于自监督学习的模型,通过对视频片段进行部分掩码并要求模型重建这些被掩码部分来进行学习。其工作流程主要包括:
- 输入视频的分块和嵌入:首先将输入的视频划分为不重叠的时空块(patch),每个块通过嵌入层(如3D卷积层)生成token。
- 编码器部分:编码器仅处理一部分未被掩码的token,通过这些token学习视频的初步表示。
- 解码器部分:解码器则通过编码器生成的表示和一些预定义的掩码token来重建被掩码掉的部分。这一过程类似于让模型从“已知”的信息中去推测“未知”部分,帮助模型学习到更丰富的特征。
在传统MAE中,编码器和解码器均使用了标准的Transformer架构,其中每一个层级都通过自注意力机制来处理输入token。这种机制虽然有效,但由于输入序列长度的增加,自注意力计算复杂度呈二次方增长,导致难以处理长序列视频。
2. 双重掩码机制
论文中提出了双重掩码机制,包括编码器掩码和解码器掩码,分别用于选择视频中哪些token参与编码和哪些token需要被重建:
- 编码器掩码:选择视频中部分token作为编码器的输入。对于长视频,编码器掩码通常采用较高的掩码比例(90%),以减少计算量并避免内存溢出。
- 解码器掩码:用于控制哪些token需要被解码器重建。在传统MAE中,解码器通常需要重建所有被掩码的token,这对于长视频来说几乎是不可能的,因为它对计算资源的需求过高。
3. 适应性解码器掩码策略
为了有效地处理长视频中的token选择问题,论文提出了一种适应性解码器掩码策略,重点在于:
- 基于内容的重要性排序:使用一种基于MAGVIT的tokenizer,结合量化模块,学习视频中各个token的重要性评分。重要性评分通过学习得到,是每个token对理解视频整体内容的贡献的量化。通过这种评分机制,可以对token进行排序,优先选择最具信息量的部分进行重建。
- 适应性掩码的实现方式:具体地,通过MAGVIT编码器对视频进行编码,同时利用一个基于CNN的token评分模块为每个token打分,然后使用一个可微的top-k选择层来确定哪些token是最重要的。这些被选中的重要token会被优先保留下来,而其余的token则会被屏蔽掉。
4. 量化token的重建目标
论文中采用了基于MAGVIT的量化token作为重建目标,而不是传统的原始像素重建。这一改进主要是因为:
- 原始像素作为重建目标时,模型往往容易关注到细节层面的重建精度,而忽略更高层次的特征信息。这导致模型的泛化能力不足,尤其是在应对视频的复杂场景时。
- 通过量化token作为重建目标,模型可以更加关注视频中的重要内容特征,从而提升视频理解的效果。MAGVIT tokenizer通过量化视频的片段,将其转换为离散的token,再进行重建。这种方式不仅减轻了计算负担,而且通过量化的方式提升了模型的表示能力。
四、实验与结果分析
一)实验设置
- 数据集:实验在多个常用的视频理解数据集上进行了验证,包括EPIC-Kitchens-100和Diving48等。EPIC-Kitchens-100主要用于动作分类任务,包括短时和长时的视频片段,而Diving48则包含复杂的跳水动作,是一个用于细粒度动作分类的数据集。
- 模型设置:实验中,作者分别对32帧和128帧的视频进行了预训练和微调。通过适应性掩码策略,作者在处理128帧长视频时显著降低了内存和计算的需求,使得预训练能够在普通的硬件设备上进行。
二)主要实验结果
- 对比分析:与随机和均匀掩码策略相比,适应性掩码策略在性能上有显著提升。在EPIC-Kitchens-100上,基于128帧的预训练模型在动作分类任务中的Top-1准确率比使用32帧的模型高出显著的3.9个百分点。在Diving48上,LVMAE在长视频(128帧)预训练的条件下,其Top-1准确率比现有最先进的MC-ViT模型提升了3.9个百分点。
- 掩码比例的影响:实验还对不同掩码比例进行了测试,结果显示,使用适应性掩码并选择15%的token进行重建能够达到最佳性能。这意味着,在给定的计算资源下,通过有效地选择重建的token,可以显著提升模型的训练效率和最终性能。
- 长视频的优势:实验结果表明,长视频(128帧)在掩码自动编码器预训练中带来了显著的性能提升,特别是在理解复杂动作序列和长时间跨度的活动时,LVMAE模型展现了更强的表现。
三)对适应性掩码策略的详细分析
适应性掩码策略的核心是对视频token进行重要性评分,并优先选择最重要的部分进行重建。具体而言,这种方法有以下几个优势:
- 有效的token选择:通过对token进行重要性评分,适应性掩码策略可以有效地减少解码器的计算负担。在大多数视频场景中,只有少数token对视频内容的理解起到关键作用,而通过优先选择这些token进行重建,可以在降低计算复杂度的同时,保持甚至提升模型的性能。
- 避免冗余信息的重建:在视频中,许多帧之间的信息是高度冗余的,尤其是在背景变化不大的情况下。传统的掩码策略往往会对这些冗余信息进行重建,浪费了计算资源。而适应性掩码通过学习视频的动态特性,优先选择那些包含显著变化或重要动作的token,避免了对无关紧要信息的重建。
- 联合量化和掩码:适应性掩码策略结合MAGVIT量化器,通过联合训练的方式,同时学习token的表示和重要性,这使得模型不仅能进行高效的掩码选择,还能在重建过程中保持对视频内容的良好理解。
五、方法的局限性与未来方向
尽管LVMAE在长视频理解中取得了显著的效果,但该方法仍存在一定的局限性:
- 大规模预训练的挑战:本文主要在相对较小的数据集上进行了实验,未来需要探索在大规模数据集上的预训练效果,尤其是在更复杂的视频场景下,如何进一步提高模型的表现仍是一个重要的问题。
- 更长序列的处理:尽管128帧已经显著超越了大多数现有方法的处理能力,但对于某些应用场景,如电影分析、体育赛事回放等,仍需要对更长时间跨度的视频进行处理。未来的研究可以结合记忆机制,或开发更高效的编码器和解码器架构,以进一步扩展模型的处理能力。