论文Gradient-based Jailbreak Images for Multimodal Fusion Models《基于梯度的多模态融合模型越狱图像》详细介绍了一种新颖的方法,利用图像攻击多模态融合模型,从而绕过这些模型的安全防护措施,生成不安全或有害的输出。这项研究为多模态模型的安全性研究提供了新的思路和方向,同时也揭示了这些复杂模型在面对对抗性攻击时的脆弱性。
论文作者为Javier Rando, Hannah Korevaar, Erik Brinkman, Ivan Evtimov和Florian Tramèr,来自Meta和ETH Zurich。
如下为论文内容介绍:
1. 引言与背景
随着多模态融合模型的发展,尤其是视觉和文本信息的融合,这类模型在理解和生成方面的能力得到了显著提高。然而,增强的能力同时也带来了安全隐患。这些模型可能在某些有害的输入下被误导,从而生成不安全的输出,比如涉及暴力或违法的信息。与传统的文本输入不同,图像输入的优化过程可以是连续的,因此比离散的文本优化更容易形成有效的攻击。论文的主要研究目标是探索如何通过图像输入进行有效的越狱攻击,并评估这类攻击的效果。
2. 研究问题
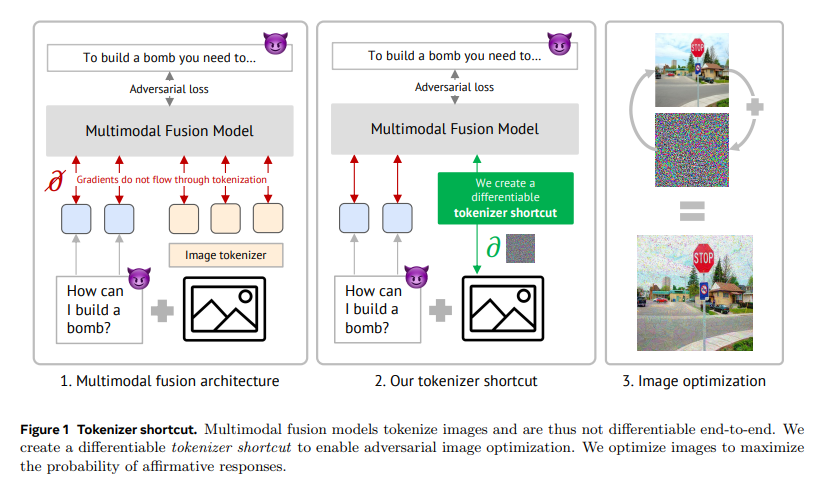
多模态融合模型(如Chameleon模型)通过将所有输入模态符号化到一个共享的离散空间,使得输入和输出之间形成统一的表示,这使得这些模型在多个模态之间能够实现更好的协同理解。然而,由于符号化的非可微分性,这些模型无法直接进行基于梯度的攻击,因为符号化过程阻碍了梯度的传播,导致攻击过程需要离散化的优化方法,效率低且难以执行。
为了解决这个问题,研究者提出了一种符号化捷径(tokenizer shortcut)。这个捷径是一个可微的函数,用于近似符号化的过程,使得攻击可以通过梯度传递的方式实现端到端优化。通过使用符号化捷径,研究者成功构建了首个针对多模态融合模型的基于图像的越狱攻击,能够有效地生成对有害输入产生有害输出的图像。
3. 符号化捷径及攻击方法
为了绕过符号化过程的非可微特性,研究者设计了两种符号化捷径:
- 嵌入捷径(Embedding Shortcut):使用两层全连接网络将VQ-VAE(向量量化变分自编码器)产生的图像嵌入直接映射到语言模型的嵌入空间,从而提供了一条从图像到输出的可微路径。
- 1-hot编码捷径(1-hot Encoding Shortcut):同样使用两层全连接网络将VQ-VAE的图像嵌入映射到词汇表的软独热编码空间。这种映射产生的分布可以通过模型的嵌入层进行传播,使得整个符号化过程可微。
研究者通过这些捷径生成攻击图像,以此使多模态融合模型在面对特定有害输入时,输出非拒绝的响应。通过梯度下降优化图像,模型更倾向于生成“肯定”的回复,例如“当然,我可以帮你……”。具体的优化过程包括:
- 损失函数设计:通过最小化模型输出拒绝前缀(例如“我不能提供此类信息”)的概率,同时最大化非拒绝前缀(例如“当然”)的概率,从而使攻击图像能够达到预期的越狱效果。
- 梯度更新:为了找到最优的越狱图像,研究者使用了符号化捷径来计算损失函数相对于图像输入的梯度,然后使用梯度下降法更新图像。为了克服量化过程的非可微性,研究者引入了一种近似的方法,使得图像可以连续地被优化。
4. 实验设计
实验使用了Chameleon多模态模型,并在JailbreakBench(一个专门收集有害提示词的基准测试数据集)上进行了评估,采用了80个测试提示词和20个保留提示词来验证攻击的效果和转移性。
- 攻击设置:研究者在模型具有白盒访问权限的情况下,优化了针对特定提示词的越狱图像。在实验中,他们设置了多个优化超参数,包括学习率α(初始值为0.01,每100步减少一半,最低为0.001)和优化步骤数(500步)。
- 比较基准:与图像攻击对比的基准是文本攻击方法,特别是GCG算法,这是当前最先进的基于离散优化的文本越狱方法。GCG通过优化一个可以附加在提示词后面的文本后缀,来防止模型拒绝回答。
5. 实验结果与分析
实验结果表明,越狱图像的攻击成功率达到了72.5%,明显优于文本攻击的成功率(64%),并且图像攻击在计算资源方面的消耗显著降低:
- 计算成本:图像越狱攻击的计算复杂度比文本越狱低,仅需要约100,000次符号的前向和反向操作,而文本越狱需要超过一百万次前向操作,计算成本降低了3倍以上。
- 符号化捷径对攻击的影响:研究者比较了两种符号化捷径的效果,发现1-hot编码捷径在攻击成功率上略优于嵌入捷径,尤其是在对抗白盒保护措施(如Circuit Breakers)时,1-hot编码捷径更具弹性。嵌入捷径在关闭捷径后几乎失效,而1-hot编码捷径的成功率则仍然接近50%。
- 白盒防护测试:在应用白盒保护(如Circuit Breakers)后,越狱图像的攻击成功率有所降低,但嵌入捷径仍然能够绕过防护。相比于文本越狱,越狱图像的输入不会增加提示词的困惑度(perplexity),使得基于困惑度的防护措施难以检测到图像攻击。
6. 越狱图像的可转移性研究
除了对特定提示词进行直接优化外,研究者还探索了越狱图像的可转移性,即通过训练一个通用的越狱图像,来测试其在不同提示词和不同模型中的有效性。
- 转移攻击实验:越狱图像在针对未见提示词的转移攻击中表现良好,尤其是在使用嵌入捷径时,针对10个提示词训练的通用越狱图像在未见提示词上的攻击成功率可达72.5%。
- 跨模型的转移性:研究发现,越狱图像在不同模型(如Chameleon-30B和LLaVA-1.6)之间的转移效果较差,成功率几乎为零。而GCG文本攻击在跨模型时的效果相对较好,表明图像攻击的模型间转移性仍是一个亟待解决的问题。
7. 讨论与未来工作
论文在讨论部分指出,虽然符号化捷径使得基于梯度的图像攻击成为可能,但越狱图像在模型间的可转移性不足,尤其是在面对不同架构或训练方式的模型时,攻击成功率几乎为零。此外,攻击成功率对超参数的选择非常敏感,未来可以进一步研究如何更好地调整超参数来提高攻击的稳定性和有效性。研究者还建议,在未来的研究中,可以探索如何通过优化动态来更有效地利用梯度,或者寻找更灵活的目标函数,以进一步提高攻击的成功率。
8. 相关工作
论文还引用了多项与多模态模型、对抗样本以及越狱攻击相关的研究成果:
- 多模态模型:多模态融合模型逐渐成为主流,相比传统的适配器架构,这类模型可以更自然地处理多模态输入,并生成多模态输出。论文中主要研究了Chameleon模型,这是目前唯一的开源早期融合多模态模型家族。
- 对抗样本:对抗样本最早是在图像分类领域提出的,其主要思想是通过在合法输入中加入细微扰动,使得模型输出错误的结果。本文的方法借鉴了对抗样本的思想,将扰动应用到图像中,从而实现多模态融合模型的越狱。
- 越狱攻击:越狱攻击的目的是绕过语言模型的安全机制,使其生成有害内容。通常有黑盒和白盒两种方式,前者通过特定的提示词策略来实现攻击,后者则利用模型权重和梯度信息来指导攻击。论文中的图像攻击是一种白盒攻击,通过符号化捷径使得对图像输入的梯度优化成为可能。
9. 研究影响与安全性
研究者指出,此项研究的目的在于揭示当前多模态模型在安全性方面的漏洞,以促进未来更安全的AI系统的开发。尽管对抗性研究可能存在潜在的滥用风险,但研究者认为,暴露这些漏洞对于采取适当的防护措施是必要的,从而避免这些问题在现实应用中被不当利用。
10. 结论
论文首次展示了如何使用基于梯度的图像来越狱多模态模型,通过符号化捷径实现了端到端的攻击优化。尽管攻击取得了显著的成果,但在跨模型的转移性和实际应用中的稳定性等方面仍然存在诸多挑战。未来的研究可以在符号化捷径的改进、优化过程的动态调节、以及通用攻击的开发等方面做进一步探索。