论文DoRA: Weight-Decomposed Low-Rank Adaptation(权重分解低秩适配)介绍了一种新的参数高效微调方法(PEFT)——DoRA,其旨在缩小LoRA和完全微调(FT)之间的准确性差距。通过将预训练权重分解为幅度和方向两个部分,DoRA专门采用LoRA进行方向更新,从而提高学习能力和训练稳定性,同时避免额外的推理成本。实验表明,DoRA在各种任务上,如常识推理和视觉指令微调,均优于LoRA。
论文作者为Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen,来自NVIDIA和HKUST。
论文内容概要如下:
一、引言
PEFT方法如LoRA因其高效性而广受欢迎,但在准确性上往往不及FT。DoRA通过将权重分解为幅度和方向组件,旨在解决这一问题。这种方法不仅模仿了FT的学习能力,还提高了LoRA的训练稳定性,同时没有增加推理开销。
二、相关工作
PEFT方法分为三类:
- 基于适配器的方法:在模型中引入额外的可训练模块。
- 基于提示的方法:在输入中添加软标记。
- 低秩适配方法(LoRA及其变种):使用低秩矩阵进行权重更新。
DoRA属于第三类,但通过引入权重分解分析来克服LoRA的局限性。
三、权重分解分析
权重分解分析将权重重新参数化为幅度和方向组件。分析表明,LoRA和FT表现出不同的学习模式:
- LoRA显示出方向和幅度变化之间的比例关系,缺乏细微调整能力。
- FT展示了更为多样的学习模式,具有负斜率趋势,表明其具备进行细微调整的能力。
四、方法论:权重分解低秩适配(DoRA)
DoRA将预训练权重分解为幅度(m)和方向(V)组件。方向组件通过LoRA进一步更新,实现高效微调。这种分解简化了LoRA的学习任务,专注于方向更新,同时通过权重归一化原则保持稳定性。
公式:
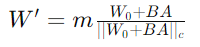
五、DoRA的梯度分析
DoRA的梯度分析显示,权重分解使梯度的协方差矩阵更接近于单位矩阵,有利于优化。这种方法允许更稳定的学习模式,有效增强了LoRA的学习能力。
六、减少训练开销
为了在反向传播过程中减少内存消耗,DoRA将方向更新的范数视为常数,从梯度图中分离出来。此调整显著减少了内存使用,而不会影响准确性。
其、实验
DoRA在各种任务和模型中进行了评估,显示出相对于LoRA的一贯性能提升。
- 常识推理:
- DoRA在LLaMA模型上显著优于LoRA。
- 采用减半秩的DoRA(DoRA†)仍优于LoRA,突显其高效性。
- 图像/视频-文本理解:
- 在VL-BART上,DoRA在图像和视频-文本任务中均优于LoRA。
- 视觉指令微调:
- 在LLaVA-1.5-7B的视觉指令微调任务中,DoRA表现优于LoRA和FT。
- 与其他LoRA变种的兼容性:
- DoRA与VeRA兼容,组合使用(DVoRA)表现优于VeRA和LoRA。
八、DoRA的鲁棒性和微调粒度
- DoRA在不同秩和训练样本量下均表现出色,一直优于LoRA。
- 通过选择性地仅更新特定模块的幅度组件,DoRA可以在减少可训练参数的情况下保持较高的准确性。
九、更广泛的影响
- QDoRA:在QLoRA的基础上增强LoRA的准确性,显示出在Orca-Math上的良好结果。
- 文本到图像生成:DoRA在细化稳定扩散模型的文本到图像生成任务中显著优于LoRA。
十、结论
DoRA缩小了LoRA和FT之间的差距,提供了一种参数高效的微调方法,其学习能力接近于FT。DoRA在多个任务和模型架构中表现出持续改进,且无额外的推理开销。未来工作将探索DoRA在音频等其他领域的适用性。
DoRA on GitHub: https://github.com/NVlabs/DoRA