论文B’MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory提出了新架构B’MOJO,该架构通过动态整合形象记忆与渐变记忆,克服了现有模型在记忆管理和长序列建模上的局限性。其创新选择机制和模块化设计使得模型能够在保持高效计算的同时实现动态记忆管理。无论在合成任务、语言建模还是长序列推理任务上,B’MOJO都展现了强大的性能和扩展能力,为混合记忆模型的研究提供了新方向。
论文作者为Luca Zancato, Arjun Seshadri, Yonatan Dukler, Aditya Golatkar, Yantao Shen, Ben Bowman, Matthew Trager, Alessandro Achille, Stefano Soatto,均来自AWS AI Labs。
Credit: AWS AI Labs
一、背景与问题
在机器学习领域,模型通常以两种方式进行数据表示:
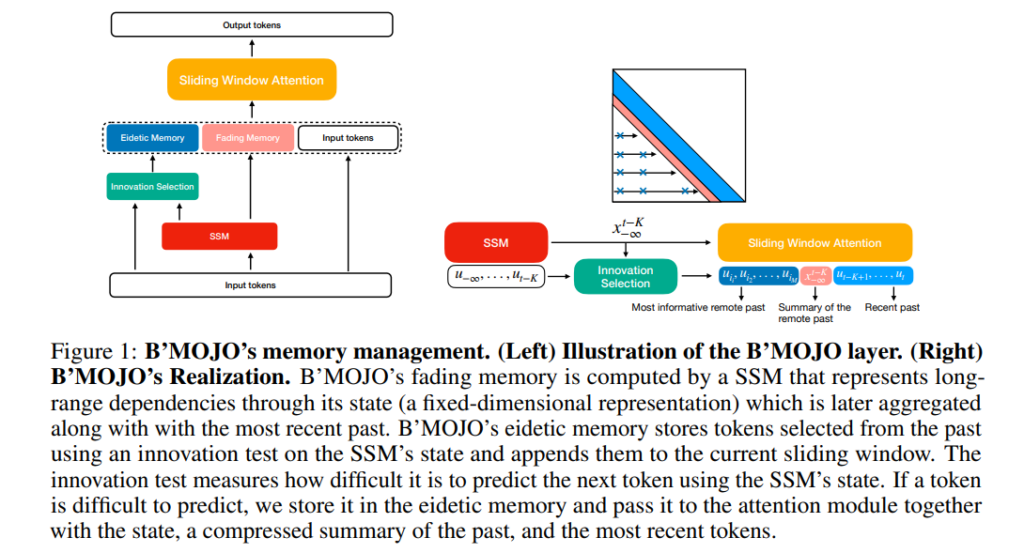
- 形象式(Eidetic)记忆:数据通过变压器模型的上下文窗口被直接存储,这种记忆虽然可以精确保留数据,但受到窗口长度的限制,无法扩展到长序列数据中。
- 渐变式(Fading)记忆:状态空间模型(SSM)通过递归存储信息,这种记忆结构对长序列更友好,但由于记忆是压缩和递减的,因此可能丢失关键细节。
现有架构的局限性包括:
- 变压器上下文长度受限,导致模型对远程依赖信息的捕获能力不足。
- 状态空间模型的记忆呈现渐变特性,信息可能因时间推移而逐渐丢失,难以实现精确的长序列回忆。
- 混合模型尝试结合上述两种记忆机制,但缺乏灵活性,无法动态调整两种记忆的权重或扩展形象记忆的范围。
因此,需要一种新的架构,能够在保持高效计算的同时,动态地整合短期和长期记忆,并有效处理序列超出训练上下文长度的问题。
二、模型架构与创新
B’MOJO 提出了一种混合状态空间模型,通过创新的记忆管理机制,将形象记忆和渐变记忆结合在一起。以下是其核心设计:
1. 核心创新机制:创新选择(Innovation Selection)
创新选择机制的灵感来源于LZW压缩算法,通过以下步骤实现对输入的筛选:
- 预测误差衡量:模型使用渐变记忆对当前输入进行预测,计算预测误差(Innovation)。
- 重要性判断:如果某个输入的预测误差较高,说明其信息较为关键,模型将其保存在形象记忆中。
- 记忆动态更新:形象记忆的大小理论上可以无限增长,但受硬件约束可实现有效的近似检索。
这一机制确保了远程的关键输入不会因为上下文窗口的滑动或渐变记忆的压缩而被遗忘,同时避免了存储所有输入的高计算开销。
2. 双记忆架构:形象记忆与渐变记忆
- 形象记忆(Eidetic Memory):以直接存储的形式保存近期的关键输入,可通过注意力机制(Sliding Window Attention)直接访问。
- 渐变记忆(Fading Memory):由状态空间模型实现,保存远期的统计信息,容量固定但可高效压缩历史数据。
两种记忆的结合使得模型能够同时捕获近期的详细信息和长时间跨度的抽象特征。
3. 高效实现方式
- 分块滑动窗口(Chunked Sliding Window):将序列分为固定长度的块,每个块在处理时总结之前的渐变和形象记忆,从而减少计算复杂度。
- 并行计算优化:模型在训练时采用并行滑动窗口方法,同时利用硬件优化加速状态更新和注意力计算。
三、理论基础与模块设计
1. 状态空间模型(SSM)
状态空间模型通过递归公式更新状态向量,从而对输入序列进行建模:xt+1=A(ut)xt+B(ut)utx_{t+1} = A(u_t)x_t + B(u_t)u_txt+1=A(ut)xt+B(ut)ut
其中,A(ut)A(u_t)A(ut) 和 B(ut)B(u_t)B(ut) 是动态状态更新矩阵,分别决定当前状态和输入对下一个状态的影响。SSM以渐变记忆的形式保存远程信息,但由于状态维度固定,可能导致记忆信息丢失。
2. 创新选择算法
创新选择机制类似于信息压缩,通过测量预测误差判断输入的重要性:
- 当预测误差超过某一阈值时,将对应的输入存储到形象记忆中。
- 存储的输入通过注意力机制直接参与当前的预测,从而提高模型对关键信息的利用率。
3. 滑动窗口注意力机制
滑动窗口机制将形象记忆和渐变记忆整合到一起:
- 对于最近的输入,直接使用形象记忆中的未压缩数据。
- 对于较远的输入,使用渐变记忆中的压缩信息。
- 最终输出是基于当前窗口和历史记忆的综合结果。
这一机制允许模型动态调整记忆的范围和权重,适应不同任务的需求。
四、实验与结果分析
1. 多查询关联召回任务(MQAR)
MQAR任务要求模型准确记忆和回忆超过上下文长度范围的信息:
- B’MOJO在相同参数规模下,召回率显著高于传统SSM和混合模型。
- 增加形象记忆的容量进一步提高了模型的召回能力,表现出极高的记忆效率。
2. 语言建模任务
B’MOJO在中等规模语言建模任务(参数规模1.4B)中取得以下成果:
- 训练效率:比Mamba和Mistral快15%,与变压器模型相比实现更优的并行效率。
- 困惑度:与变压器模型相当,优于现有的SSM和混合模型。
3. 长序列推理
在PG-19等长序列数据集上的测试结果:
- B’MOJO展示了显著的长度泛化能力,在测试长度为训练长度4倍(32K tokens)的序列上,仍能保持较低的困惑度。
- 与传统变压器模型相比,B’MOJO能够更好地处理超长序列数据,这得益于其对渐变记忆和形象记忆的动态管理。
4. 架构扩展与对比
与现有模型的对比:
- Mamba(SSM):仅使用渐变记忆,难以实现精确召回。
- Mistral(变压器):上下文窗口限制显著,无法处理远程依赖。
- B’MOJO:通过创新选择机制动态扩展形象记忆,显著提高了对长序列的建模能力。
五、局限性与未来研究方向
1. 模型规模的限制:尽管B’MOJO在1.4B参数规模下表现出色,但在更大模型上的扩展能力需要进一步验证,包括硬件优化和计算资源的需求。
2. 渐变记忆的局限性:由于渐变记忆依赖Mamba架构,其在更长序列上的泛化能力可能面临瓶颈,未来可以研究结合时间归一化技术来优化。
3. 社会影响与风险:模型的长序列记忆能力可能带来信息获取效率的提升,但同时也可能被用于传播错误信息。因此,加强模型的可控性和减少幻觉生成(hallucination)是未来的重点研究方向。