ChatGPT的输出文本中,中文常出现“旨在”,英文“Delve”一词有较高的出现频率,这是其特有的AI味儿。
论文Idiosyncrasies in Large Language Models专门研究了上述现象。该论文详细探讨了大型语言模型(LLMs)中的特征差异,特别是它们生成的文本在不同模型之间的可区分性。研究者们通过一项合成分类任务,探讨了不同LLM生成的文本能否被有效地区分,并揭示了每个模型的“癖好”或独特特征。
论文作者为Mingjie Sun, Yida Yin, Zhiqiu Xu, J. Zico Kolter, Zhuang Liu,来自Carnegie Mellon University, UC Berkeley, University of Pennsylvania和Princeton University。
一、引言
随着生成性语言模型的广泛应用,尤其是大型语言模型(LLMs),理解这些模型生成内容的来源和特征变得越来越重要。过去的研究主要集中在人类生成的文本与AI生成文本的区分(例如,研究如何识别人类写作和机器写作之间的区别),但很少有研究关注如何区分不同LLM所生成的内容,尤其是在同一类别内的不同模型之间。本文的研究目标是探讨是否存在使得不同LLM生成的文本具有明显区别的“癖好”,这些癖好是否能够通过简单的文本分类任务来识别。
LLMs的输出不仅仅取决于输入的提示(prompt),还受到训练数据、架构和优化过程的影响。因此,了解每个模型的特定输出特点对于理解模型行为以及推测模型背后使用的数据有重要的应用价值。例如,能够区分不同LLM生成的内容可以帮助我们揭示不同模型在训练过程中使用的数据类型,甚至可能提供关于模型偏见的线索。
二、方法与实验设计
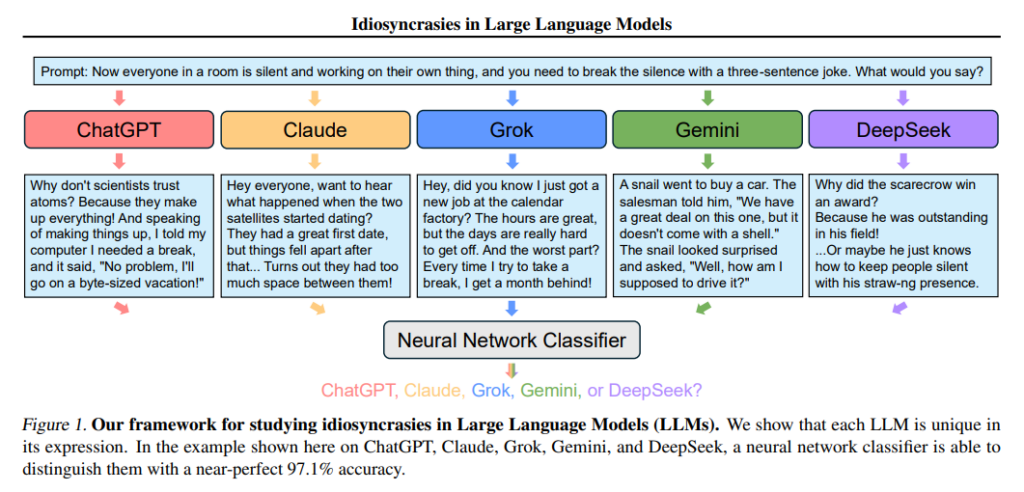
为了研究不同LLM的“癖好”,作者提出了一种合成分类任务。任务的目标是通过预测某一段文本的来源模型来区分不同的LLM。具体来说,作者从多个LLM(如ChatGPT、Claude、Grok、Gemini和DeepSeek)生成大量文本,并使用一个分类器来辨别每个文本是由哪个模型生成的。为了进行这个任务,研究者们从每个模型生成了大量文本,构建了一个数据集,并训练了一个分类器来预测文本的来源。
实验结果表明,使用简单的文本嵌入模型进行微调后,分类器能在这个任务上取得非常高的准确率。例如,在五分类任务中,分类器能够以97.1%的准确率成功区分ChatGPT、Claude、Grok、Gemini和DeepSeek的文本输出,这个准确率远高于20%的随机猜测水平。此外,研究者还发现,在同一模型系列内,尽管这些模型具有相似的训练过程和数据源,分类器仍然能够在一定程度上识别出它们的不同特征,尤其是通过不同模型的输出进行分类时,这些癖好在数据集之间表现得尤为明显。
三、实验结果与分析
实验表明,LLM的输出展示了明显的个性化特征,即便是使用相同的提示语生成的文本,来自不同模型的输出也能被有效地区分。研究者通过多个实验验证了这一点。例如,在同一模型系列(如Qwen系列)的不同版本之间,尽管它们共享相似的训练数据和架构,分类器依然能在不同的模型版本之间取得较高的分类准确率。这表明,即使是同一模型家族的变种,它们生成的文本在细节上依然存在显著差异。
研究者还发现,不同LLM之间的这些“癖好”并不仅仅依赖于文本的字面结构或格式,而是与语义内容密切相关。当文本通过重写、翻译或总结等方式进行变化时,分类器依然能够较为准确地识别出文本的来源模型。这表明,LLMs在生成文本时的独特性不仅仅体现在单词的选择上,还体现在文本的语义层面。
四、控制实验
为了进一步深入理解LLMs的“癖好”,研究者进行了多个控制实验,例如控制生成文本的长度和格式。研究者通过修改原始提示,要求模型生成不同长度或格式的文本,来探讨这些文本特点对模型输出的影响。实验结果表明,即便在这些控制条件下,LLM的输出依然能体现出不同的癖好。例如,当控制输出的长度时,分类器仍然能够保持较高的分类准确率,这进一步表明这些模型的输出在深层次上存在显著的风格差异,而不仅仅是表面上的格式。
五、具体的癖好分析
为了定量分析LLMs的癖好,研究者使用了TF-IDF方法,从文本中提取出具有代表性的短语。研究者发现,每个模型生成的文本中都有一些特定的、反复出现的短语,这些短语能够反映出该模型的独特语言风格。例如,ChatGPT更喜欢使用“such as”、“certainly”等短语,而Claude则更常用“according to”和“based on”这类短语。这些短语通常在模型生成的文本中起到了转折或强调的作用,是模型输出的一个重要标志。通过分析这些特征,研究者能够清晰地识别出不同LLM的输出风格。
此外,研究还探讨了模型在生成文本时使用的标记语言(Markdown格式)。不同模型使用的Markdown元素(如标题、加粗、斜体、列表等)也表现出不同的规律。例如,ChatGPT更倾向于在生成的文本中使用加粗和标题,而Claude则更倾向于使用简单的列举和项目符号。通过分析这些格式化特征,研究者进一步揭示了LLM输出中存在的风格差异。
六、语义分析
除了文本的表面特征,研究者还对LLM输出的语义进行了深入分析。通过使用另一个LLM(如GPT-4o mini)对原始文本进行重写、翻译或总结,研究者发现,即便在文本的具体表达发生变化的情况下,分类器仍然能够准确识别出源模型。这表明,LLMs生成文本时的独特性不仅体现在表面文字上,更深层次的语义信息也起到了关键作用。例如,即便是对文本进行了翻译或重写,LLMs之间的区别依然显著,这进一步证明了语义内容在模型的独特性中扮演着重要角色。
七、实验的广泛影响
本文的研究不仅揭示了LLM输出的独特性,还对多个实际应用场景具有重要的启示。首先,在训练LLMs时,尤其是在使用合成数据(如通过其他LLM生成的文本)进行微调时,模型可能会继承源模型的“癖好”。这意味着,训练时使用的合成数据可能会影响最终模型的输出风格和表现,因此在使用合成数据训练模型时需要特别小心。
此外,研究提出的框架可以为评估不同LLM之间的相似性提供一种定量的方法。这对于探索开源与闭源LLM之间的差异、评估模型的泛化能力,以及进行跨模型分析都具有重要的意义。通过对比不同模型的输出特征,可以帮助我们更好地理解每个模型的优缺点,并为模型优化提供理论依据。
总的来说,本文通过对不同LLM的分析,展示了LLMs之间存在显著的风格差异,甚至在同一类别模型内的不同变种之间也能观察到可辨别的特征。这些差异不仅体现在词汇层面,还包括语法结构、语义内容以及格式化特征等方面。这为进一步理解LLMs的行为提供了有价值的参考,并为未来的模型改进和数据使用提供了新的视角。